使用scrapy框架爬取微博热搜榜
注:在使用爬虫抓取网站数据之前,非常重要的一点是确保遵守相关的法律、法规以及目标网站的使用条款。
(最底下附下载链接)
准备工作:
安装依赖:
确保已经安装了Python环境。
使用pip安装scrapy:pip install scrapy。
创建Scrapy项目:
打开命令行工具,在期望的位置创建一个新的Scrapy项目:scrapy startproject weiboHotSearch。
进入项目目录:cd weiboHotSearch。
设置User-Agent和其他headers:
修改settings.py文件中的USER_AGENT以及其他可能需要自定义的headers,模拟真实浏览器访问。
编写爬虫
1.创建Spider

2. 定义Item
在items.py文件中定义你想要抓取的数据字段。对于微博热搜榜单,我们可能需要如下字段:
import scrapyclass WeiboHotsearchItem(scrapy.Item):rank = scrapy.Field() # 排名keyword = scrapy.Field() # 热搜关键词url = scrapy.Field() # 关键词链接hot_index = scrapy.Field() # 热度指数category = scrapy.Field() # 类别(如置顶、实时上升等)3. 编写Spider
使用genspider命令生成一个爬虫模板并编辑它:
1. 导入必要的库
import scrapy
from ..items import WeiboHotsearchItem
from urllib.parse import urljoin
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time2. 爬虫类定义
class HotSearchSpider(scrapy.Spider):name = 'hot_search'allowed_domains = ['s.weibo.com']start_urls = ['https://s.weibo.com/top/summary']3. 初始化方法
def __init__(self, *args, **kwargs):super(HotSearchSpider, self).__init__(*args, **kwargs)chrome_options = Options()chrome_options.add_argument("--headless") # 无头模式运行chrome_options.add_argument("--disable-gpu")chrome_options.add_argument("--no-sandbox")self.driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=chrome_options)目的:初始化爬虫实例时,配置并启动一个无界面(headless)模式的Chrome浏览器实例,以避免在执行过程中弹出浏览器窗口。
4. 解析方法
def parse(self, response):self.driver.get(response.url)# 显式等待,直到所有的tr元素都出现wait = WebDriverWait(self.driver, 20)wait.until(EC.presence_of_all_elements_located((By.XPATH, '//table/tbody/tr')))# 滚动页面到底部以触发更多内容加载last_height = self.driver.execute_script("return document.body.scrollHeight")while True:self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")time.sleep(2) # 等待新内容加载new_height = self.driver.execute_script("return document.body.scrollHeight")if new_height == last_height:breaklast_height = new_heightfor sel in self.driver.find_elements(By.XPATH, '//table/tbody/tr'):item = WeiboHotsearchItem()item['rank'] = sel.find_element(By.XPATH, './/td[@class="td-01"]').text if sel.find_elements(By.XPATH,'.//td[@class="td-01"]') else Noneitem['keyword'] = sel.find_element(By.XPATH, './/td[@class="td-02"]/a').text if sel.find_elements(By.XPATH,'.//td[@class="td-02"]/a') else Nonehref = sel.find_element(By.XPATH, './/td[@class="td-02"]/a').get_attribute('href') if sel.find_elements(By.XPATH, './/td[@class="td-02"]/a') else Noneitem['url'] = urljoin('https://s.weibo.com', href) if href else Noneitem['hot_index'] = sel.find_element(By.XPATH, './/td[@class="td-02"]/span').text if sel.find_elements(By.XPATH, './/td[@class="td-02"]/span') else Noneitem['category'] = sel.find_element(By.XPATH, './/td[@class="td-03"]/i').text if sel.find_elements(By.XPATH,'.//td[@class="td-03"]/i') else Noneyield item目的:
使用Selenium加载网页并等待所有目标元素加载完成。
实现页面滚动以加载动态内容,确保获取完整数据。
遍历每个搜索结果项,提取排名、关键词、链接、热度指数和类别等信息,封装到WeiboHotsearchItem对象中,并将其生成为输出。
5. 关闭方法
def closed(self, reason):self.driver.quit()目的:当爬虫关闭时,确保释放由Selenium创建的浏览器资源,即关闭浏览器实例。
4.配置Pipeline以保存至MongoDB
import pymongoclass MongoDBPipeline:collection_name = 'weibo_hotsearch'def __init__(self, mongo_uri, mongo_db):self.mongo_uri = mongo_uriself.mongo_db = mongo_db@classmethoddef from_crawler(cls, crawler):return cls(mongo_uri=crawler.settings.get('MONGO_URI'),mongo_db=crawler.settings.get('MONGO_DATABASE', 'items'))def open_spider(self, spider):self.client = pymongo.MongoClient(self.mongo_uri)self.db = self.client[self.mongo_db]def close_spider(self, spider):self.client.close()def process_item(self, item, spider):self.db[self.collection_name].insert_one(dict(item))return item5. 更新Settings
# 启用pipelines
ITEM_PIPELINES = {'weibo_hotsearch.pipelines.MongoDBPipeline': 300,
}# MongoDB连接设置
MONGO_URI = 'mongodb://localhost:27017/'
MONGO_DATABASE = 'weibo'# 其他可选设置
ROBOTSTXT_OBEY = False # 如果网站有robots.txt且不允许爬取,请谨慎设置为True
DOWNLOAD_DELAY = 1 # 设置下载延迟避免触发反爬虫机制# 禁用默认的下载器中间件
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}6.查看Mongodb保存结果

mongodb-windows-x86下载
源码下载
相关文章:
使用scrapy框架爬取微博热搜榜
注:在使用爬虫抓取网站数据之前,非常重要的一点是确保遵守相关的法律、法规以及目标网站的使用条款。 (最底下附下载链接) 准备工作: 安装依赖: 确保已经安装了Python环境。 使用pip安装scrapyÿ…...

瑞吉外卖项目学习笔记(七)新增菜品、(批量)删除菜品
瑞吉外卖项目学习笔记(一)准备工作、员工登录功能实现 瑞吉外卖项目学习笔记(二)Swagger、logback、表单校验和参数打印功能的实现 瑞吉外卖项目学习笔记(三)过滤器实现登录校验、添加员工、分页查询员工信息 瑞吉外卖项目学习笔记(四)TableField(fill FieldFill.INSERT)公共字…...

es快速扫描
介绍 Elasticsearch简称es,一款开源的分布式全文检索引擎 可组建一套上百台的服务器集群,处理PB级别数据 可满足近实时的存储和检索 倒排索引 跟正排索引相对,正排索引是根据id进行索引,所以查询效率非常高,但是模糊…...

前端对页面数据进行缓存
页面录入信息,退出且未提交状态下,前端对页面数据进行存储 前端做缓存,一般放在local、session和cookies里面,但是都有大小限制,如果页面东西多,比如有上传的图片、视频,浏览器会抛出一个Quota…...

leetCode322.零钱兑换
题目: 给你一个整数数组coins,表示不同面额的硬币;以及一个整数amount,表示总金额。 计算并返回可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回-1。 你可以认为每种硬币的数量是无限的。 示例1࿱…...

jsp-servlet开发
STS中开发步骤 建普通jsp项目过程 1.建项目(非Maven项目) new----project----other----Web----Dynamic Web Project 2.下载包放到LIB目录中,如果是Maven项目可以自动导包(pom.xml中设置好) 3.设置工作空间,网页…...
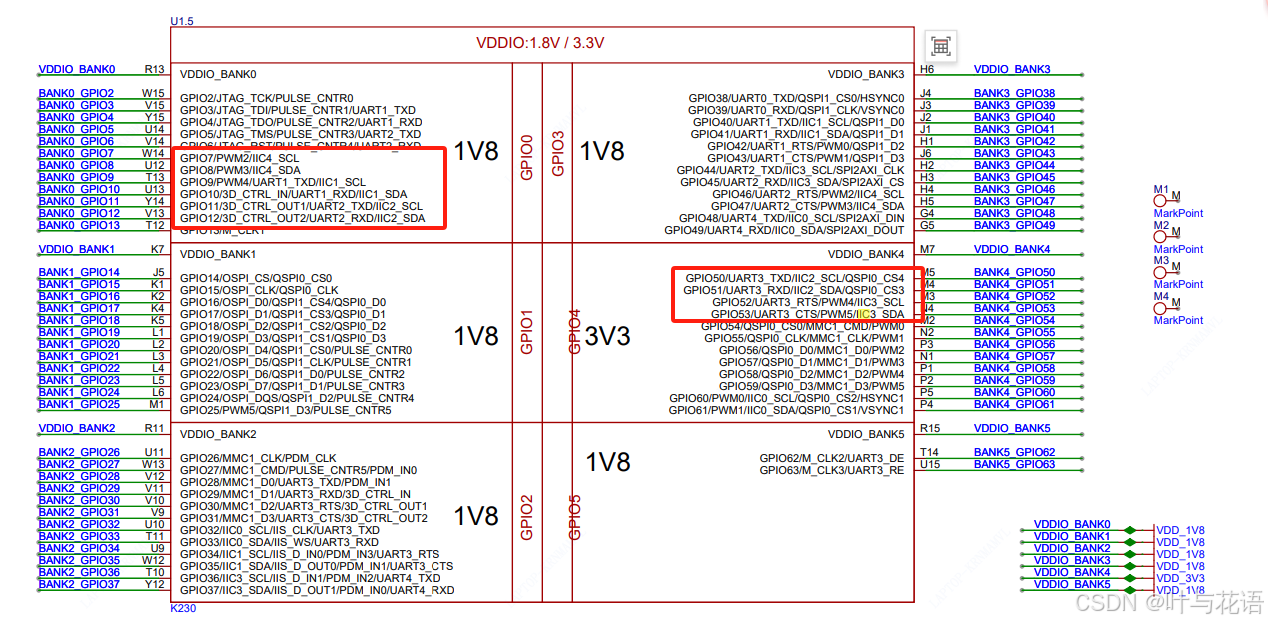
从零玩转CanMV-K230(7)-I2C例程
文章目录 前言一、IIC API二、示例总结 前言 K230内部包含5个I2C硬件模块,支持标准100kb/s,快速400kb/s模式,高速模式3.4Mb/s。 通道输出IO配置参考IOMUX模块。 一、IIC API I2C类位于machine模块下。 i2c I2C(id, freq100000) 【参数】…...

n阶Legendre多项式正交性的证明
前言 在《n次Legendre(勒让德)多项式在区间(-1, 1)上根的分布及证明》这篇文章中,我们阐述了Legendre多项式在 [ − 1 , 1 ] [-1,1] [−1,1]上的根分布情况并给出了证明。本文将证明Legendre多项式在 [ − 1 , 1 ] [-1,1] [−1,1]上的正交性质。 正交多项式的定义…...
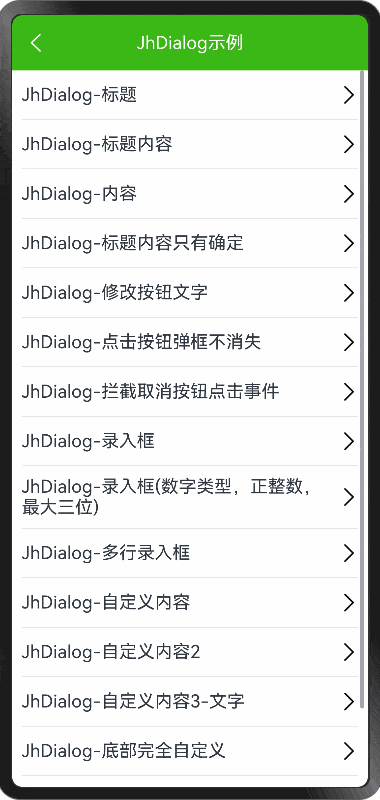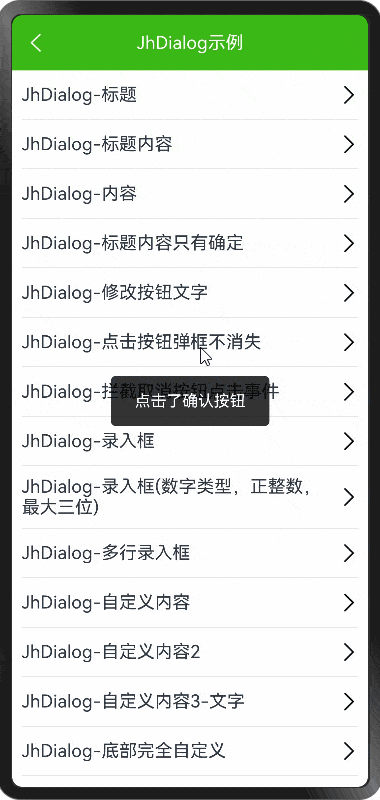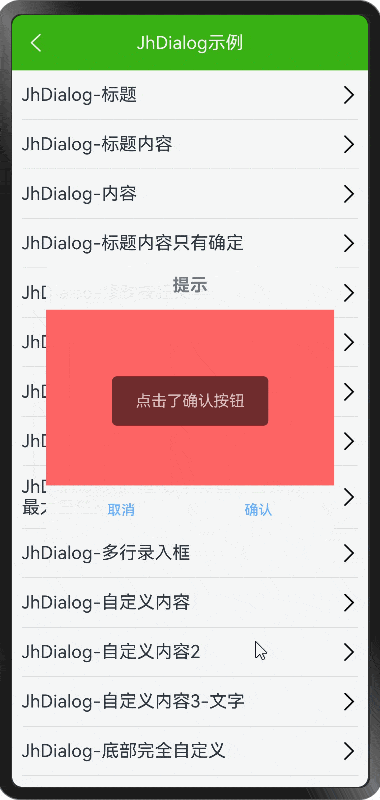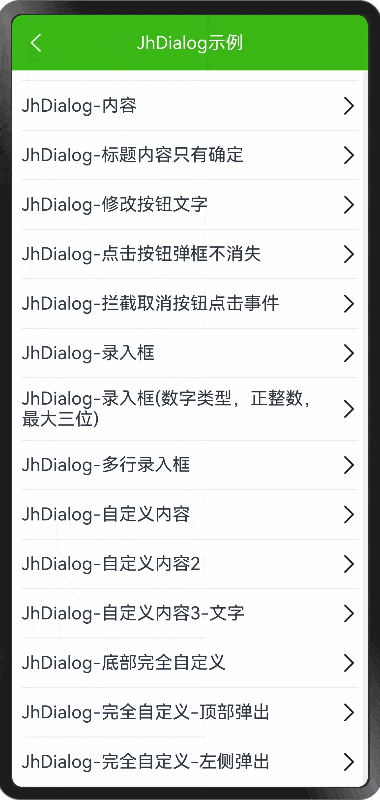
HarmonyOS NEXT - Dialog 和完全自定义弹框
demo 地址: https://github.com/iotjin/JhHarmonyDemo 组件对应代码实现地址 代码不定时更新,请前往github查看最新代码 在demo中这些组件和工具类都通过module实现了,具体可以参考HarmonyOS NEXT - 通过 module 模块化引用公共组件和utils HarmonyOS NE…...

内容与资讯API优质清单
作为开发者,拥有一套API合集是必不可少的。这个开发者必备的API合集汇集了各种实用的API资源,为你的开发工作提供了强大的支持!无论你是在构建网站、开发应用还是进行数据分析,这个合集都能满足你的需求。你可以通过这些免费API获…...
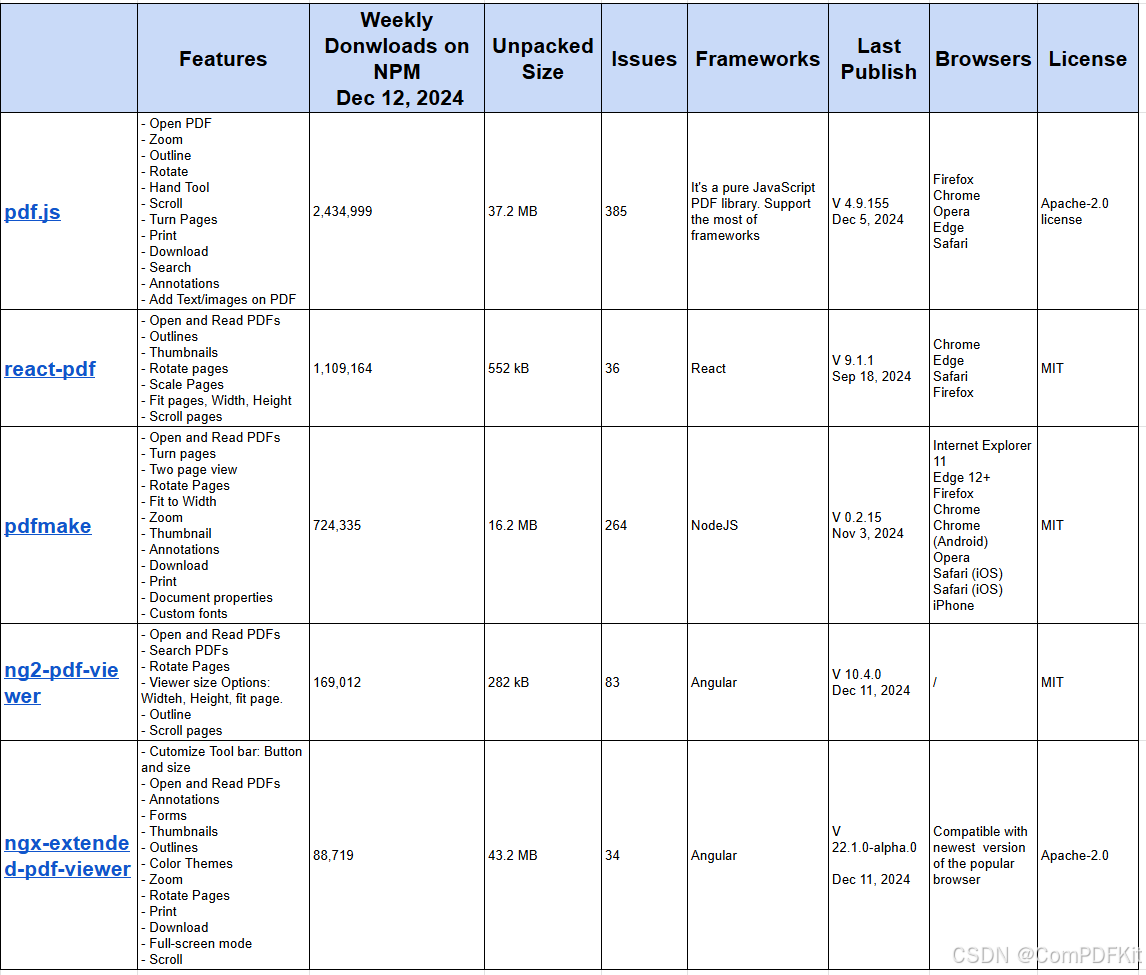
开源 JS PDF 库比较
原文查看:开源JavaScript PDF Library对比 对于需要高性能、复杂功能或强大支持处理复杂 PDF 的项目,建议选择商业 PDF 库, 如ComPDFKit for Web。但是,如果您的目标只是在 Web 应用程序中显示 PDF,则可以使用几个可靠的开源…...
AnaPico信号源在通信测试中的应用案例
AnaPico信号源在通信测试中的应用案例广泛,涉及多种通信技术和测试需求。以下是一些具体的应用实例: 1. APPH系列信号源分析仪(相位噪声分析仪) APPH系列是一款高性能相位噪声分析仪和VCO测试仪,其不同型号的频率范围…...

《智启新材:人工智能重塑分子结构设计蓝图》
在当今科技飞速发展的时代,新材料的研发宛如一场激烈的竞赛,而人工智能(AI)作为一匹黑马,正以前所未有的速度和力量驰骋于这片赛场,为新材料的分子结构设计带来了革命性的突破,成为推动行业发展…...
进阶岛-L2G5000
茴香豆:企业级知识库问答工具 茴香豆本地标准版搭建 环境搭建 安装茴香豆 知识库创建 测试知识助手 Gradio UI 界面测试...

单点登录平台Casdoor搭建与使用,集成gitlab同步创建删除账号
一,简介 一般来说,公司有很多系统使用,为了实现统一的用户名管理和登录所有系统(如 GitLab、Harbor 等),并在员工离职时只需删除一个主账号即可实现权限清除,可以采用 单点登录 (SSO) 和 集中式…...
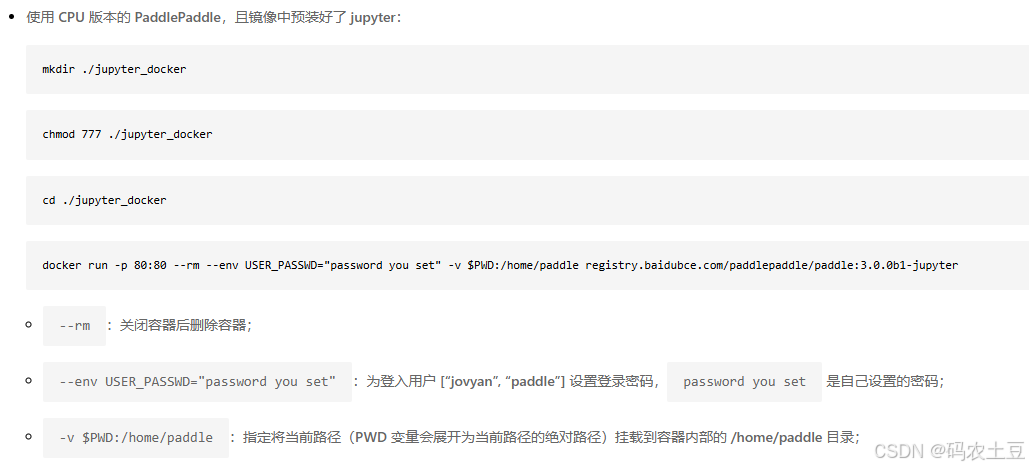
PaddlePaddle飞桨Linux系统Docker版安装
PaddlePaddle飞桨Linux系统Docker版安装 最近学习和了解PP飞桨,一切从安装开始。官网的安装教程很详细: https://www.paddlepaddle.org.cn/install/quick?docurl/documentation/docs/zh/install/docker/linux-docker.html 记录我在安装过程中遇到的问题…...
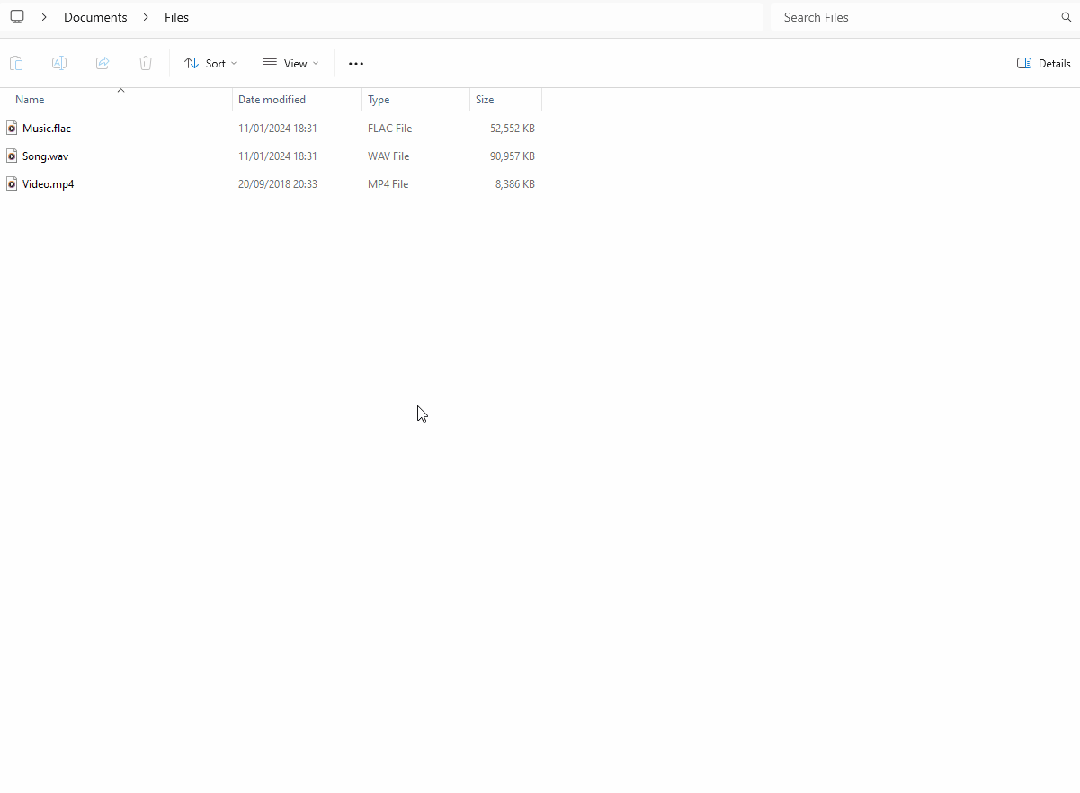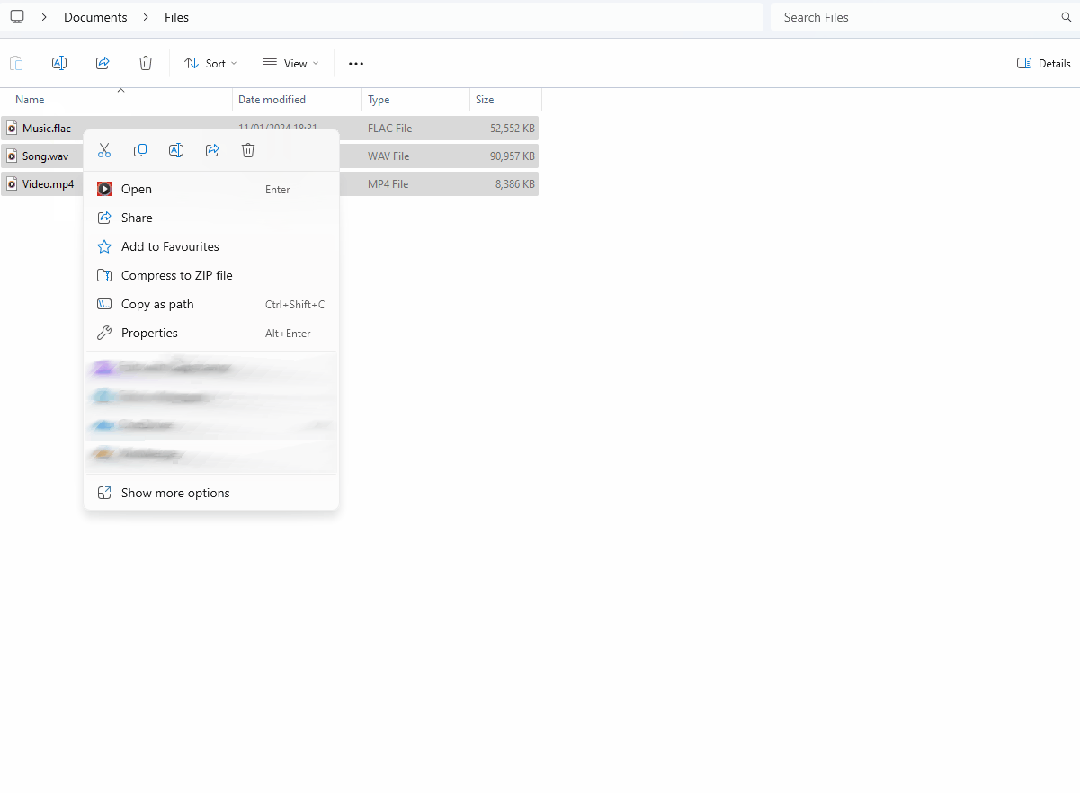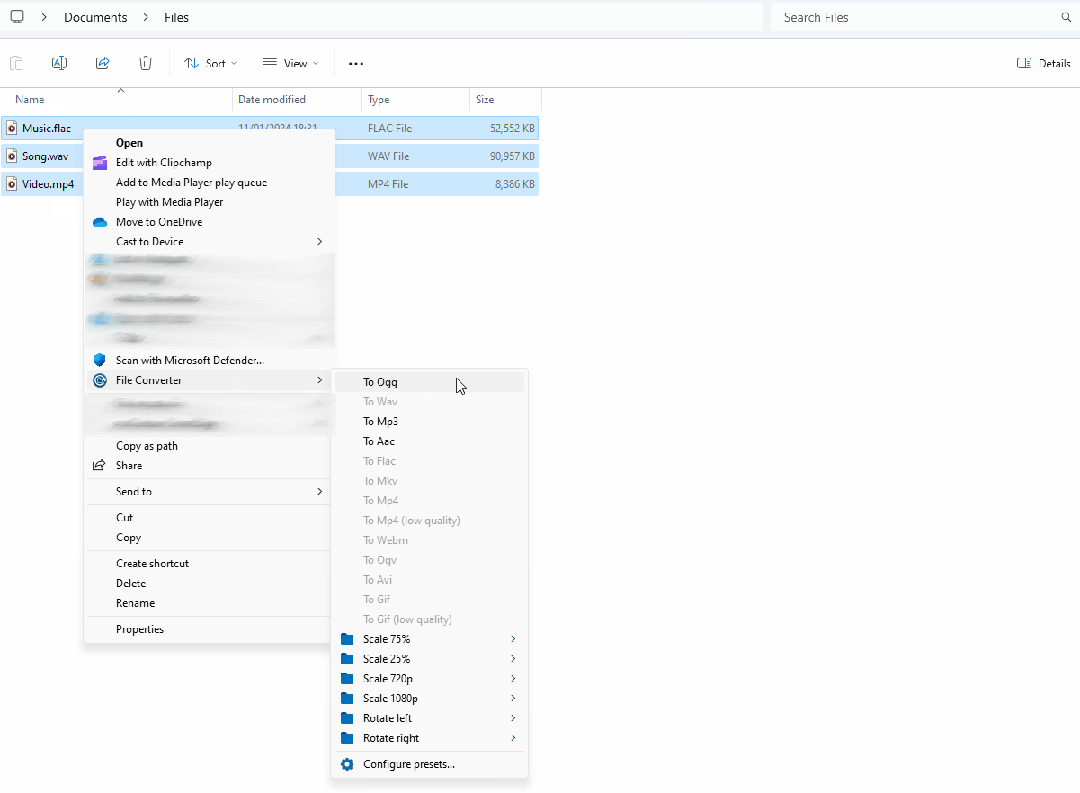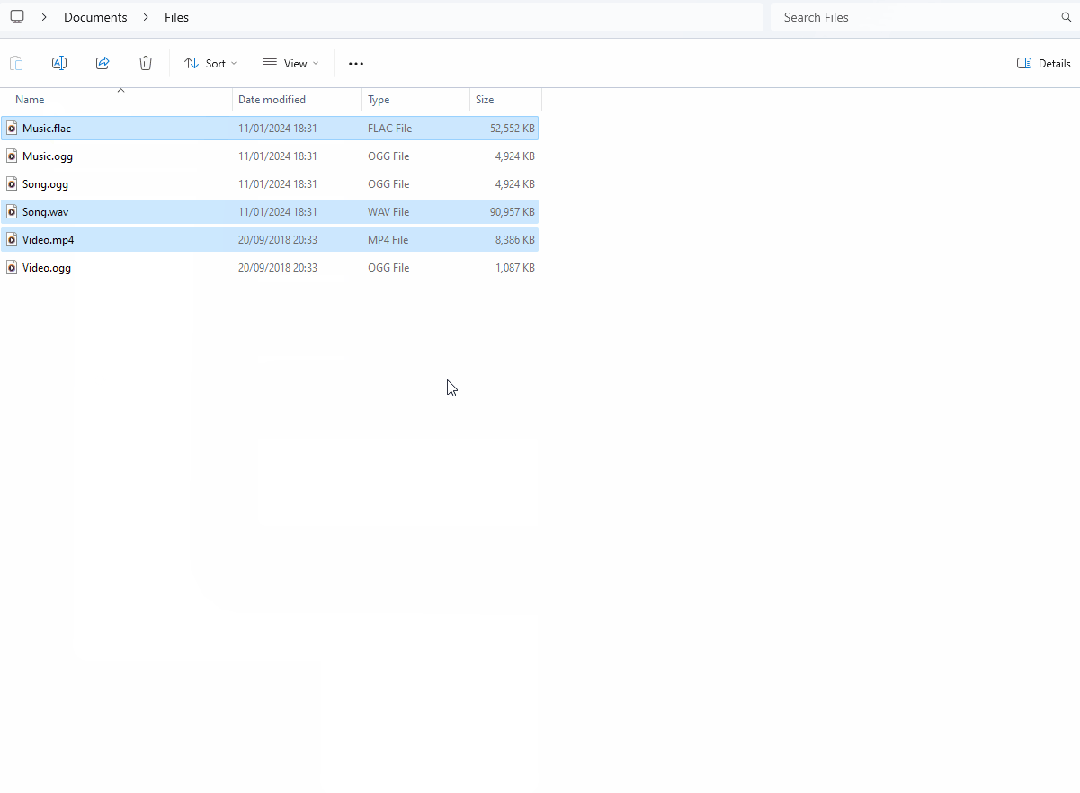
一款基于.NET开发的简易高效的文件转换器
前言 今天大姚给大家分享一款基于.NET开发的免费(GPL-3.0 license)、简易、高效的文件转换器,允许用户通过Windows资源管理器的上下文菜单来转换和压缩一个或多个文件:FileConverter。 使用技术栈 ffmpeg:作为文件转换…...

Spring Boot教程之三十一:入门 Web
Spring Boot – 入门 Web 如今,大多数应用程序都需要模型-视图-控制器(MVC) 架构来满足各种需求,例如处理用户数据、提高应用程序效率、为应用程序提供动态特性。它主要用于构建桌面图形用户界面 (GUI),但现在越来越流行用于构建基于 Web 的…...

青少年编程与数学 02-004 Go语言Web编程 20课题、单元测试
青少年编程与数学 02-004 Go语言Web编程 20课题、单元测试 一、单元测试(Unit Testing)二、集成测试(Integration Testing)三、区别四、Go Web单元测试使用testing包使用testify框架使用GoConvey框架 五、应用示例步骤 1: 创建HTT…...

概率论 期末 笔记
第一章 随机事件及其概率 利用“四大公式”求事件概率 全概率公式与贝叶斯公式 伯努利概型求概率 习题 推导 一维随机变量及其分布 离散型随机变量(R.V)求分布律 利用常见离散型分布求概率 连续型R.V相关计算 利用常见连续型分布的计算 均匀分布 正态…...

3层修复机制深度解析:Windows更新故障修复工具架构原理
3层修复机制深度解析:Windows更新故障修复工具架构原理 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool Reset Wind…...

编写程序实现智能厨房刀具消毒,完成后自动提示,保障饮食安全。
📝 项目概述:Smart Knife Sterilizer Slogan: 代码守护舌尖安全,紫外精准消杀;让每一刀都切得安心,吃得放心。 一、 实际应用场景描述 (Context & Scenario) * 场景:现代家庭厨房。菜刀、水果刀在使用后…...

【常见开发问题】SQL注入示例及防范措施介绍
SQL注入示例及防范措施介绍 文章目录 SQL注入示例及防范措施介绍 一、SQL注入简介 二、SQL防注入方法 三、总结 一、SQL注入简介 SQL注入是将Web页面的原URL、表单域或数据包输入的参数,修改拼接成SQL语句传递给Web服务器,进而传给数据库服务器以执行数据库命令。其根本原因…...

免费不花一分钱,每月多省18小时,2026实测视频文案提取网站每年帮你省699元会员费
做AI工具测评快三年了,前前后后测了不下二十款录音转写、视频文案提取工具,踩过的坑能绕办公桌三圈,实话实说,目前测下来听脑AI是同类工具中最值得用的,没有之一。今天不给大家讲虚的,给你们算实打实的效率…...

Qwen3.5-4B-Claude-OpusAI应用:轻量级推理服务嵌入内部知识库方案
Qwen3.5-4B-Claude-OpusAI应用:轻量级推理服务嵌入内部知识库方案 1. 模型概述 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是基于Qwen3.5-4B的推理蒸馏模型,特别强化了结构化分析、分步骤回答、代码与逻辑类问题的处理能力。该版本以GGUF量…...

XUnity.AutoTranslator终极指南:如何为Unity游戏实现实时自动翻译
XUnity.AutoTranslator终极指南:如何为Unity游戏实现实时自动翻译 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator是一款功能强大的Unity游戏实时翻译插件,专…...

DeepSeek V4 全面实测:万亿参数开源模型的工程落地与成本推演
上周 DeepSeek V4 的消息一出,我当天夜里几乎没合眼——作为从 V2 时期一路跟过来的独立开发者,每次大版本迭代对我来说都像一场技术狂欢。V3 的性能已经足够激进,V4 直接把参数量拉到了万亿级别,而且还保持开源,这件事…...
)
Claude读论文系列(七)
SkillSieve 精读笔记 论文标题: SkillSieve: A Hierarchical Triage Framework for Detecting Malicious AI Agent Skills arXiv: 2604.06550 | 2026-04-09 作者: Yinghan Hou(Imperial College London) Zongyou Yang…...

春联生成模型效果展示:‘健康‘、‘奋斗‘主题对联,意境优美接地气
春联生成模型效果展示:健康、奋斗主题对联,意境优美接地气 春节将至,家家户户都开始张罗贴春联。一副好春联不仅要对仗工整、平仄合规,更要能表达出对新年的美好祝愿。今天我要为大家展示一款基于达摩院PALM大模型的春联生成模型…...

HTTP接口设计进阶技巧:http-api-guide高级应用解析
HTTP接口设计进阶技巧:http-api-guide高级应用解析 【免费下载链接】http-api-guide 项目地址: https://gitcode.com/gh_mirrors/ht/http-api-guide 在API开发领域,设计一套规范、高效且易于维护的HTTP接口至关重要。http-api-guide作为一份全面…...