Python Pandas(5):Pandas Excel 文件操作
Pandas 提供了丰富的 Excel 文件操作功能,帮助我们方便地读取和写入 .xls 和 .xlsx 文件,支持多表单、索引、列选择等复杂操作,是数据分析中必备的工具。
| 操作 | 方法 | 说明 |
|---|---|---|
| 读取 Excel 文件 | pd.read_excel() | 读取 Excel 文件,返回 DataFrame |
| 将 DataFrame 写入 Excel | DataFrame.to_excel() | 将 DataFrame 写入 Excel 文件 |
| 加载 Excel 文件 | pd.ExcelFile() | 加载 Excel 文件并访问多个表单 |
| 使用 ExcelWriter 写多个表单 | pd.ExcelWriter() | 写入多个 DataFrame 到同一 Excel 文件的不同表单 |
1 读取 Excel 文件
pd.read_excel() 方法用于从 Excel 文件中读取数据并加载为 DataFrame。它支持读取 .xls 和 .xlsx 格式的文件。语法格式如下:
pandas.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None, usecols=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=<no_default>, date_format=None, thousands=None, decimal='.', comment=None, skipfooter=0, storage_options=None, dtype_backend=<no_default>, engine_kwargs=None)
io:这是必需的参数,指定了要读取的 Excel 文件的路径或文件对象。sheet_name=0:指定要读取的工作表名称或索引。默认为0,即第一个工作表。header=0:指定用作列名的行。默认为0,即第一行。names=None:用于指定列名的列表。如果提供,将覆盖文件中的列名。index_col=None:指定用作行索引的列。可以是列的名称或数字。usecols=None:指定要读取的列。可以是列名的列表或列索引的列表。dtype=None:指定列的数据类型。可以是字典格式,键为列名,值为数据类型。engine=None:指定解析引擎。默认为None,pandas 会自动选择。converters=None:用于转换数据的函数字典。true_values=None:指定应该被视为布尔值True的值。false_values=None:指定应该被视为布尔值False的值。skiprows=None:指定要跳过的行数或要跳过的行的列表。nrows=None:指定要读取的行数。na_values=None:指定应该被视为缺失值的值。keep_default_na=True:指定是否要将默认的缺失值(例如NaN)解析为NA。na_filter=True:指定是否要将数据转换为NA。verbose=False:指定是否要输出详细的进度信息。parse_dates=False:指定是否要解析日期。date_parser=<no_default>:用于解析日期的函数。date_format=None:指定日期的格式。thousands=None:指定千位分隔符。decimal='.':指定小数点字符。comment=None:指定注释字符。skipfooter=0:指定要跳过的文件末尾的行数。storage_options=None:用于云存储的参数字典。dtype_backend=<no_default>:指定数据类型后端。engine_kwargs=None:传递给引擎的额外参数字典。
本文以 runoob_pandas_data.xlsx 为例,下载链接:https://static.jyshare.com/download/runoob_pandas_data.xlsx
import pandas as pd# 读取 data.xlsx 文件
df = pd.read_excel('runoob_pandas_data.xlsx')# 打印读取的 DataFrame
print(df)

read_excel 默认读取第一个表单(sheet_name=0),假设 data.xlsx 文件中只有一个表单,读取后的数据会存储在一个 DataFrame 中。如果 data.xlsx 文件中有多个表单,可以通过指定 sheet_name 来读取特定表单的数据,例如 pd.read_excel('data.xlsx', sheet_name='Sheet1')。
import pandas as pd# 读取默认的第一个表单
df = pd.read_excel('data.xlsx')
print(df)# 读取指定表单的内容(表单名称)
df = pd.read_excel('data.xlsx', sheet_name='Sheet1')
print(df)# 读取多个表单,返回一个字典
dfs = pd.read_excel('data.xlsx', sheet_name=['Sheet1', 'Sheet2'])
print(dfs)# 自定义列名并跳过前两行
df = pd.read_excel('data.xlsx', header=None, names=['A', 'B', 'C'], skiprows=2)
print(df)
2 将 DataFrame 写入 Excel 文件
to_excel() 方法用于将 DataFrame 写入 Excel 文件,支持 .xls 和 .xlsx 格式。
DataFrame.to_excel(excel_writer, *, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, inf_rep='inf', freeze_panes=None, storage_options=None, engine_kwargs=None)
excel_writer:这是必需的参数,指定了要写入的 Excel 文件路径或文件对象。sheet_name='Sheet1':指定写入的工作表名称,默认为'Sheet1'。na_rep='':指定在 Excel 文件中表示缺失值(NaN)的字符串,默认为空字符串。float_format=None:指定浮点数的格式。如果为None,则使用 Excel 的默认格式。columns=None:指定要写入的列。如果为None,则写入所有列。header=True:指定是否写入列名作为第一行。如果为False,则不写入列名。index=True:指定是否写入索引作为第一列。如果为False,则不写入索引。index_label=None:指定索引列的标签。如果为None,则不写入索引标签。startrow=0:指定开始写入的行号,默认从第0行开始。startcol=0:指定开始写入的列号,默认从第0列开始。engine=None:指定写入 Excel 文件时使用的引擎,默认为None,pandas 会自动选择。merge_cells=True:指定是否合并单元格。如果为True,则合并具有相同值的单元格。inf_rep='inf':指定在 Excel 文件中表示无穷大值的字符串,默认为'inf'。freeze_panes=None:指定冻结窗格的位置。如果为None,则不冻结窗格。storage_options=None:用于云存储的参数字典。engine_kwargs=None:传递给引擎的额外参数字典。
import pandas as pd# 创建一个简单的 DataFrame
df = pd.DataFrame({'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'Los Angeles', 'Chicago']
})# 将 DataFrame 写入 Excel 文件,写入 'Sheet1' 表单
df.to_excel('output.xlsx', sheet_name='Sheet1', index=False)# 写入多个表单,使用 ExcelWriter
with pd.ExcelWriter('output.xlsx') as writer:df.to_excel(writer, sheet_name='Sheet1', index=False)
df.to_excel(writer, sheet_name='Sheet2', index=False)

3 加载 Excel 文件
ExcelFile 是一个用于读取 Excel 文件的类,它可以处理多个表单,并在不重新打开文件的情况下访问其中的数据。
excel_file = pd.ExcelFile('data.xlsx')| 方法 | 功能描述 |
|---|---|
sheet_names | 返回文件中所有表单的名称列表 |
parse(sheet_name) | 解析指定表单并返回一个 DataFrame |
close() | 关闭文件,以释放资源 |
import pandas as pd# 使用 ExcelFile 加载 Excel 文件
excel_file = pd.ExcelFile('data.xlsx')# 查看所有表单的名称
print(excel_file.sheet_names)# 读取指定的表单
df = excel_file.parse('Sheet1')
print(df)# 关闭文件
excel_file.close()
4 写入 Excel 文件
ExcelWriter 是 pandas 提供的一个类,用于将 DataFrame 或 Series 对象写入 Excel 文件。使用 ExcelWriter,你可以在一个 Excel 文件中写入多个工作表,并且可以更灵活地控制写入过程。
pandas.ExcelWriter(path, engine=None, date_format=None, datetime_format=None, mode='w', storage_options=None, if_sheet_exists=None, engine_kwargs=None)path:这是必需的参数,指定了要写入的 Excel 文件的路径、URL 或文件对象。可以是本地文件路径、远程存储路径(如 S3)、URL 链接或已打开的文件对象。engine:这是一个可选参数,用于指定写入 Excel 文件的引擎。如果为None,则 pandas 会自动选择一个可用的引擎(默认优先选择openpyxl,如果不可用则选择其他可用引擎)。常见的引擎包括'openpyxl'(用于.xlsx文件)、'xlsxwriter'(提供高级格式化和图表功能)、'odf'(用于 OpenDocument 格式如.ods)等。date_format:这是一个可选参数,指定写入 Excel 文件中日期的格式字符串,例如"YYYY-MM-DD"。datetime_format:这是一个可选参数,指定写入 Excel 文件中日期时间对象的格式字符串,例如"YYYY-MM-DD HH:MM:SS"。mode:这是一个可选参数,默认为'w',表示写入模式。如果设置为'a',则表示追加模式,向现有文件中添加数据(仅支持部分引擎,如openpyxl)。storage_options:这是一个可选参数,用于指定与存储后端连接的额外选项,例如认证信息、访问权限等,适用于写入远程存储(如 S3、GCS)。if_sheet_exists:这是一个可选参数,默认为'error',指定如果工作表已经存在时的行为。选项包括'error'(抛出错误)、'new'(创建一个新工作表)、'replace'(替换现有工作表的内容)、'overlay'(在现有工作表上覆盖写入)。engine_kwargs:这是一个可选参数,用于传递给引擎的其他关键字参数。这些参数会传递给相应引擎的函数,例如xlsxwriter.Workbook(file, **engine_kwargs)或openpyxl.Workbook(**engine_kwargs)等。
4.1 ExcelWriter
基本语法:
with ExcelWriter('output.xlsx') as writer:df.to_excel(writer, sheet_name='Sheet1')你可以使用同一个 ExcelWriter 对象将不同的 DataFrame 写入同一个 Excel 文件的不同工作表。
import pandas as pddf1 = pd.DataFrame([["AAA", "BBB"]], columns=["Spam", "Egg"])
df2 = pd.DataFrame([["ABC", "XYZ"]], columns=["Foo", "Bar"])
with pd.ExcelWriter("path_to_file.xlsx") as writer:df1.to_excel(writer, sheet_name="Sheet1")df2.to_excel(writer, sheet_name="Sheet2")

4.2 设置日期格式或日期时间格式
from datetime import date, datetimeimport pandas as pddf = pd.DataFrame([[date(2014, 1, 31), date(1999, 9, 24)],[datetime(1998, 5, 26, 23, 33, 4), datetime(2014, 2, 28, 13, 5, 13)],],index=["Date", "Datetime"],columns=["X", "Y"],
)
with pd.ExcelWriter("path_to_file.xlsx",date_format="YYYY-MM-DD",datetime_format="YYYY-MM-DD HH:MM:SS"
) as writer:df.to_excel(writer)

4.3 向现有 Excel 文件追加内容
with pd.ExcelWriter("path_to_file.xlsx", mode="a", engine="openpyxl") as writer:df.to_excel(writer, sheet_name="Sheet3")使用 if_sheet_exists 参数替换已存在的工作表:
with ExcelWriter("path_to_file.xlsx",mode="a",engine="openpyxl",if_sheet_exists="replace",
) as writer:df.to_excel(writer, sheet_name="Sheet1")
向同一个工作表写入多个 DataFrame,注意 if_sheet_exists 参数需要设置为 overlay:
with ExcelWriter("path_to_file.xlsx",mode="a",engine="openpyxl",if_sheet_exists="overlay",
) as writer:df1.to_excel(writer, sheet_name="Sheet1")df2.to_excel(writer, sheet_name="Sheet1", startcol=3)4.4 将 Excel 文件存储在内存中
import ioimport pandas as pddf = pd.DataFrame([["ABC", "XYZ"]], columns=["Foo", "Bar"])
buffer = io.BytesIO()
with pd.ExcelWriter(buffer) as writer:df.to_excel(writer)
4.5 将 Excel 文件打包到 zip 压缩文件中
import zipfileimport pandas as pddf = pd.DataFrame([["ABC", "XYZ"]], columns=["Foo", "Bar"])
with zipfile.ZipFile("path_to_file.zip", "w") as zf:with zf.open("filename.xlsx", "w") as buffer:with pd.ExcelWriter(buffer) as writer:df.to_excel(writer)
4.6 向底层引擎传递额外的参数
with pd.ExcelWriter("path_to_file.xlsx",engine="xlsxwriter",engine_kwargs={"options": {"nan_inf_to_errors": True}}
) as writer:df.to_excel(writer)
在追加模式下,engine_kwargs 会传递给 openpyxl 的 load_workbook:
with pd.ExcelWriter("path_to_file.xlsx",engine="openpyxl",mode="a",engine_kwargs={"keep_vba": True}
) as writer:df.to_excel(writer, sheet_name="Sheet2")相关文章:
Python Pandas(5):Pandas Excel 文件操作
Pandas 提供了丰富的 Excel 文件操作功能,帮助我们方便地读取和写入 .xls 和 .xlsx 文件,支持多表单、索引、列选择等复杂操作,是数据分析中必备的工具。 操作方法说明读取 Excel 文件pd.read_excel()读取 Excel 文件,返回 DataF…...

区块链技术:Facebook 重塑社交媒体信任的新篇章
在这个信息爆炸的时代,社交媒体已经成为我们生活中不可或缺的一部分。然而,随着社交平台的快速发展,隐私泄露、数据滥用和虚假信息等问题也日益凸显。这些问题的核心在于传统社交媒体依赖于中心化服务器存储和管理用户数据,这种模…...

跨平台App开发,有哪些编程语言和工具,比较一下优劣势?
1. React Native 语言:JavaScript 工具:React Native框架 优势: 跨平台支持:一套代码可同时运行在iOS和Android上。 社区支持:拥有庞大的社区和丰富的第三方库。 热更新:支持热更新,无需重新…...
Windows逆向工程入门之汇编环境搭建
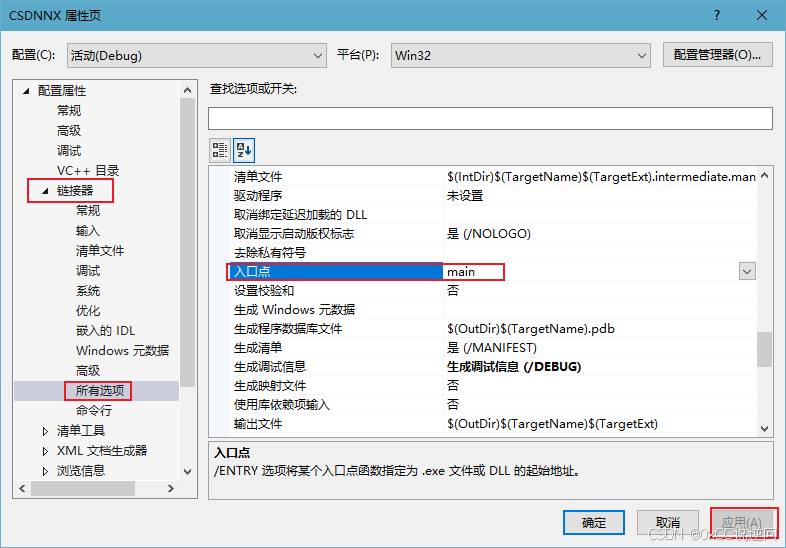
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 Visual Studio逆向工程配置 基础环境搭建 Visual Studio 官方下载地址安装配置选项(后期可随时通过VS调整) 使用C的桌面开发 拓展可选选项 MASM汇编框架 配置MASM汇编项目 创建新项目 选择空…...

网络安全溯源 思路 网络安全原理
网络安全背景 网络就是实现不同主机之间的通讯。网络出现之初利用TCP/IP协议簇的相关协议概念,已经满足了互连两台主机之间可以进行通讯的目的,虽然看似简简单单几句话,就描述了网络概念与网络出现的目的,但是为了真正实现两台主机…...

《Peephole LSTM:窥视孔连接如何开启性能提升之门》
在深度学习的领域中,长短期记忆网络(LSTM)以其出色的序列数据处理能力而备受瞩目。而Peephole LSTM作为LSTM的一种重要变体,通过引入窥视孔连接,进一步提升了模型的性能。那么,窥视孔连接究竟是如何发挥作用…...
viem库
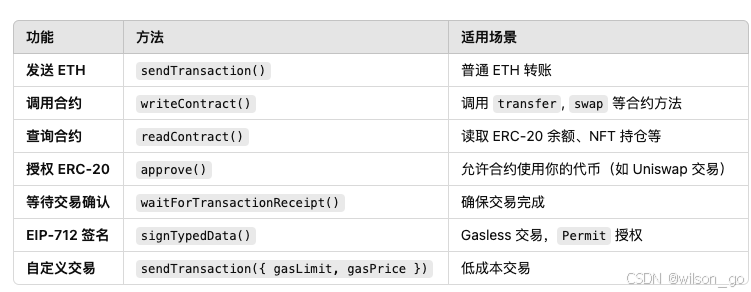
viem是一个用于和以太坊进行交互的javascript库,它提供了简单的API进行智能合约的读取和写入操作,你可以使用它来与区块链上智能合约进行交互,查询链上数据等。 基本功能 1,创建公有客户端 createPublicClient 可以创建一个链接…...
Iceberg and AIStor 的Lakehouse Architecture 权威指南
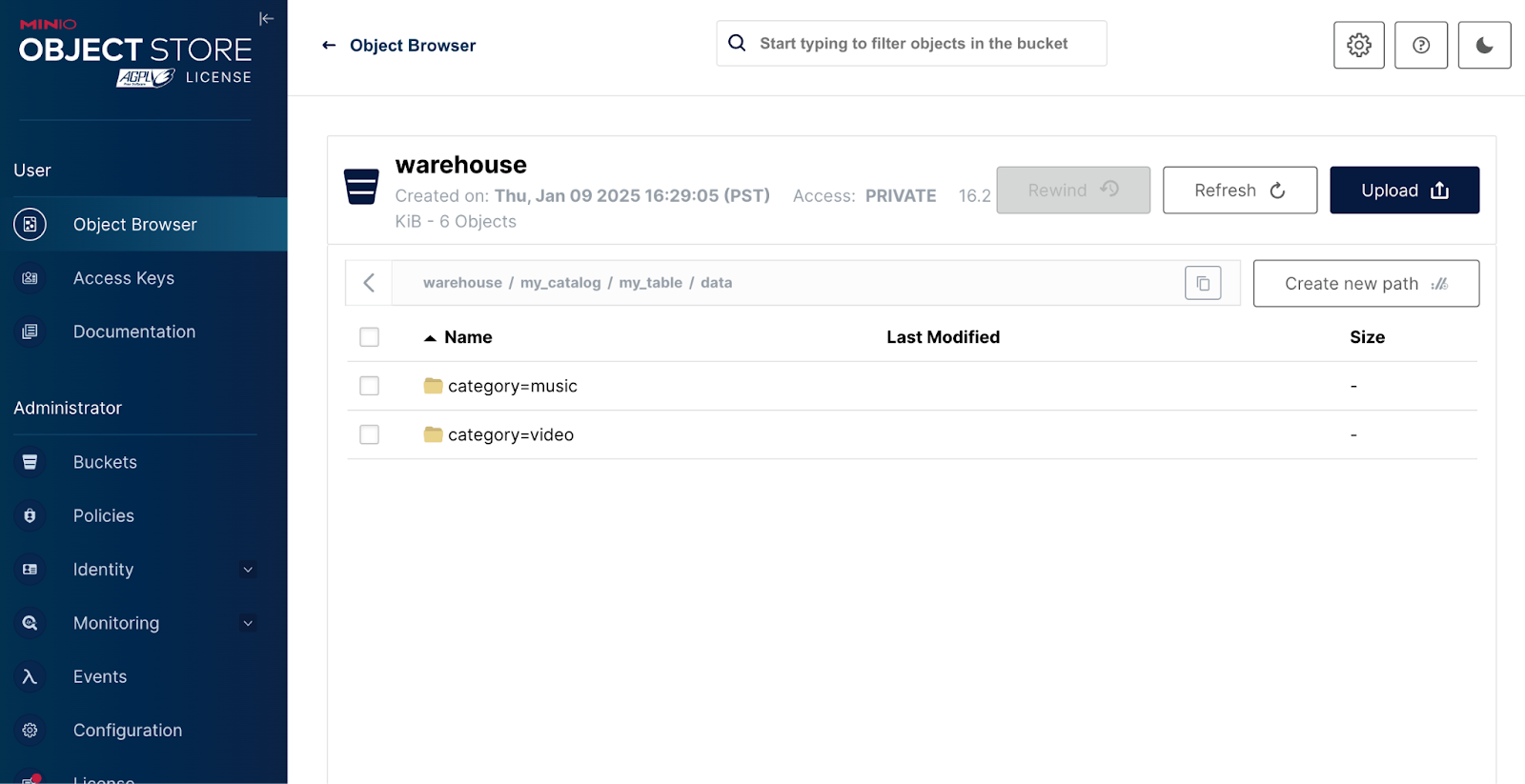
Apache Iceberg 似乎已经掀起了一场(暴风雪)数据世界。它最初由 Ryan Blue(也是 Tabular 的成员,现在是 Databricks 的名人)在 Netflix 孵化,最终被传输到它目前所在的 Apache 软件基金会。从本质上讲&…...
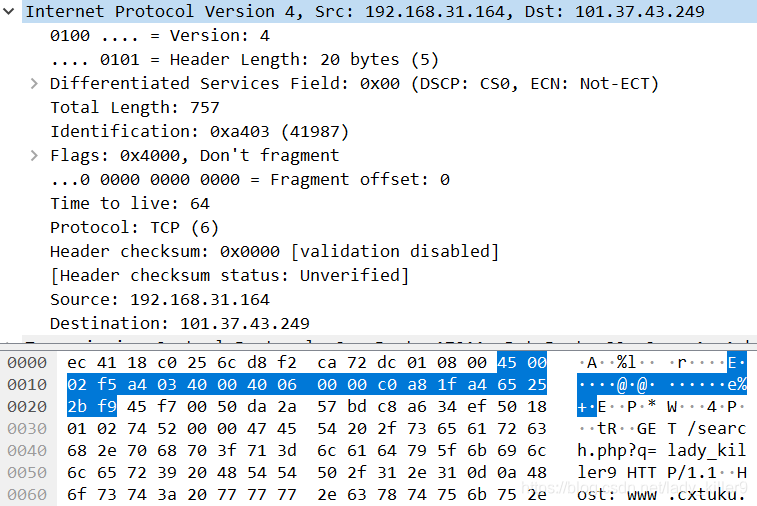
TCP/IP 协议图解 | TCP 协议详解 | IP 协议详解
注:本文为 “TCP/IP 协议” 相关文章合辑。 未整理去重。 TCP/IP 协议图解 退休的汤姆 于 2021-07-01 16:14:25 发布 TCP/IP 协议简介 TCP/IP 协议包含了一系列的协议,也叫 TCP/IP 协议族(TCP/IP Protocol Suite,或 TCP/IP Pr…...
第四节 docker基础之---dockerfile部署JDK
本地宿主机配置jdk 创建test目录: [rootdocker ~]# mkdir test 压缩包tomcat和jdk上传到root/test目录下: 本机部署Jdk 解压jdk: [rootdocker test]# tar -xf jdk-8u211-linux-x64.tar.gz [rootdocker test]# tar -xf apache-tomcat-8.5.…...
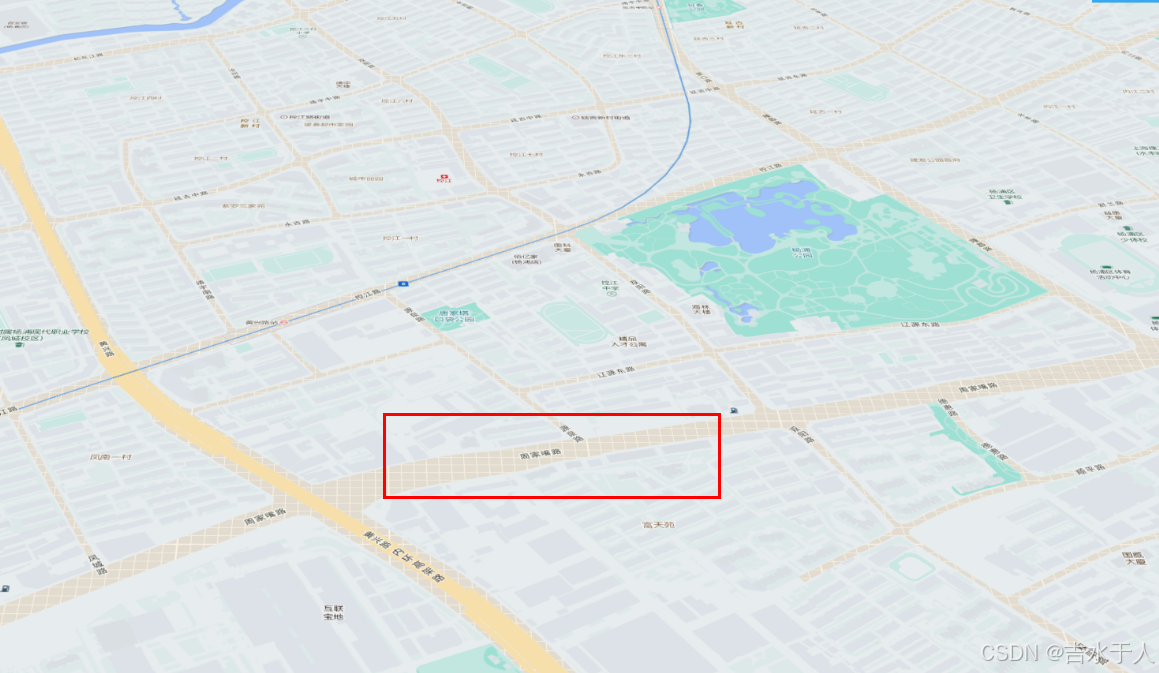
Arcgis/GeoScene API for JavaScript 三维场景底图网格设为透明
项目场景: 有时候加载的地图服务白色区域会露底,导致在三维场景时,露出了三维网格,影响效果,自此,我们需要将三维场景的底图设为白色或透明。 问题描述 如图所示: 解决方案: 提示…...

基于javaweb的SpringBoot电影推荐系统
🎬 秋野酱:《个人主页》 🔥 个人专栏:《Java专栏》《Python专栏》 ⛺️心若有所向往,何惧道阻且长 文章目录 运行环境开发工具适用功能说明项目介绍环境需要技术栈使用说明 运行环境 Java≥8、MySQL≥5.7 开发工具 eclipse/idea/myeclips…...
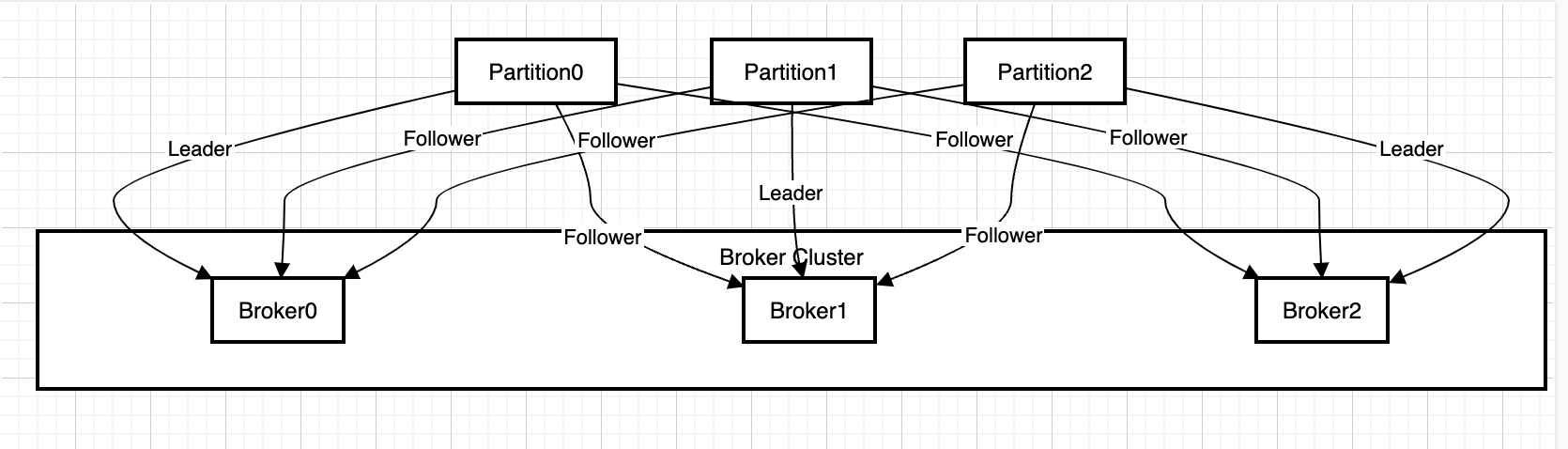
【kafka系列】Topic 与 Partition
Kafka 的 Topic(主题) 和 Partition(分区) 是数据组织的核心概念,它们的映射关系及在 Broker 上的分布直接影响 Kafka 的性能、扩展性和容错能力。以下是详细解析: 一、Topic 与 Partition 的映射关系 Top…...
大数据项目2:基于hadoop的电影推荐和分析系统设计和实现
前言 大数据项目源码资料说明: 大数据项目资料来自我多年工作中的开发积累与沉淀。 我分享的每个项目都有完整代码、数据、文档、效果图、部署文档及讲解视频。 可用于毕设、课设、学习、工作或者二次开发等,极大提升效率! 1、项目目标 本…...
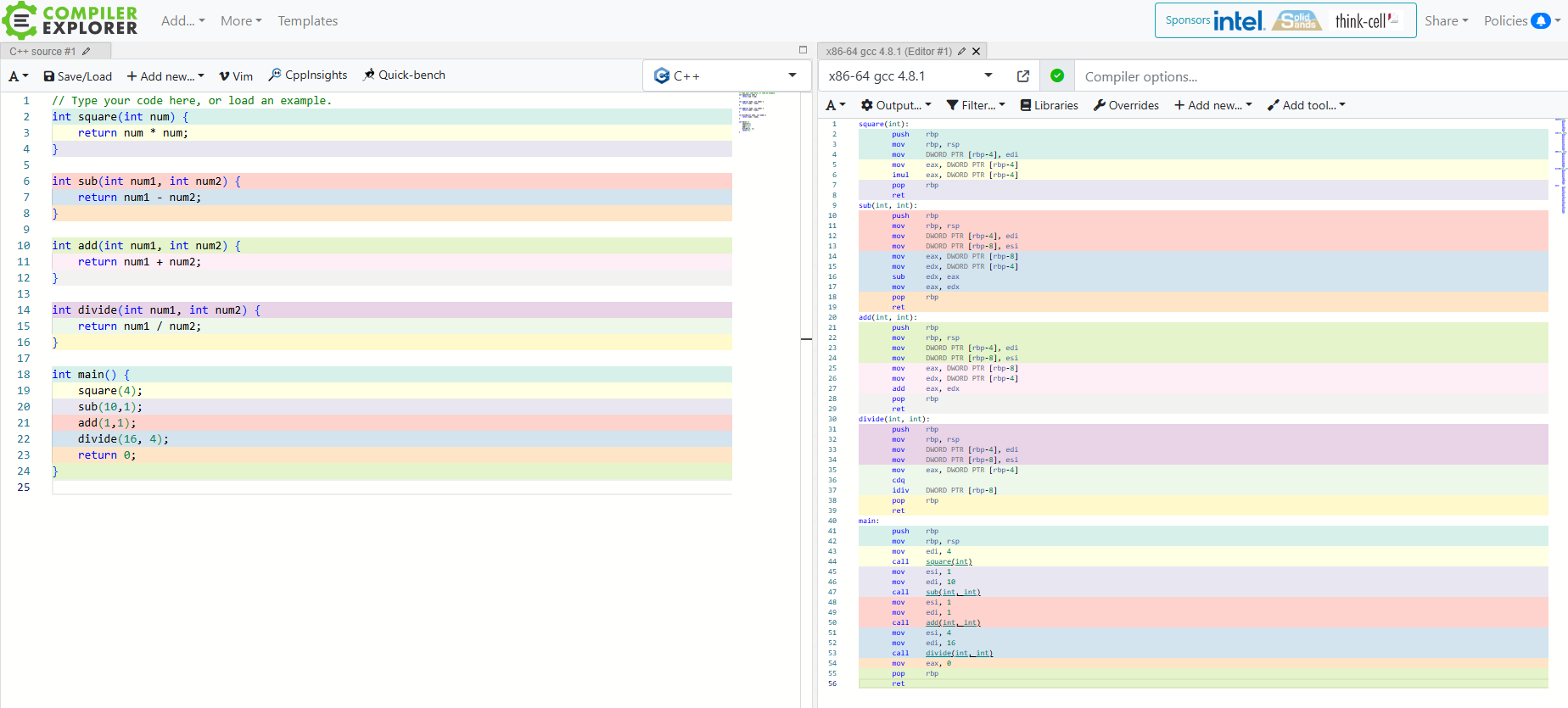
[笔记] 汇编杂记(持续更新)
文章目录 前言举例解释函数的序言函数的调用栈数据的传递 总结 前言 举例解释 // Type your code here, or load an example. int square(int num) {return num * num; }int sub(int num1, int num2) {return num1 - num2; }int add(int num1, int num2) {return num1 num2;…...
的性能对比)
同步阻塞IO和多路复用IO(epoll)的性能对比
多路复用 I/O(如 epoll)相比传统的同步阻塞 I/O 在网络性能上具有显著优势,主要原因在于其高效的事件驱动机制和对高并发的优化能力。 1. 同步阻塞 I/O 的性能瓶颈 在传统的同步阻塞 I/O 模型中,每个网络连接通常需要一个独立的线…...

前端 CSS 动态设置样式::class、:style 等技巧详解
一、:class 动态绑定类名 v-bind:class(缩写为 :class)可以动态地绑定一个或多个 CSS 类名。 1. 对象语法 通过对象语法,可以根据条件动态切换类名。 <template><div :class"{ greenText: isActive, red-text: hasError }&…...

qt widget和qml界面集成到一起
将 Qt Widgets 和 QML 界面集成在一起可以利用 QQuickWidget 或 QQuickView。以下是基本步骤: 使用 QQuickWidget 创建 Qt Widgets 项目: 创建一个基于 Widgets 的应用程序。添加 QQuickWidget: 在你的窗口或布局中添加 QQuickWidget。 例如,可以在 QMainWindow 中使用: …...
BUU30 [网鼎杯 2018]Fakebook1
是一个登录界面,我们先注册一个试试: 用dirsearch扫描出来robots.txt,也发现了flag.php,并下载user.php.bak 源代码内容: <?phpclass UserInfo {public $name "";public $age 0;public $blog &quo…...
信息科技伦理与道德3-2:智能决策
2.2 智能推荐 推荐算法介绍 推荐系统:猜你喜欢 https://blog.csdn.net/search_129_hr/article/details/120468187 推荐系统–矩阵分解 https://blog.csdn.net/search_129_hr/article/details/121598087 案例一:YouTube推荐算法向儿童推荐不适宜视频 …...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...

对比按量计费与Token Plan套餐的实际成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐的实际成本差异 在构建和运营基于大模型的应用时,成本控制是一个核心的工程考量。Taotok…...

如何快速掌握MPC视频渲染器:面向初学者的完整教程
如何快速掌握MPC视频渲染器:面向初学者的完整教程 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 想要在Windows系统上获得影院级的视频播放体验吗?MPC…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...