JVM相关面试题
1. 类加载与双亲委派机制
聊一下你对类加载器的理解。
类加载器是JVM用来加载类文件到内存的组件。它负责将字节码文件解析为java.lang.Class实例,并存储到运行时数据区的方法区中。类加载器分为Bootstrap ClassLoader、Extension ClassLoader和Application ClassLoader,它们共同构成了类加载的层次结构。2.双亲委派机制是什么?它的作用是什么?
双亲委派机制是指当一个类加载器加载类时,它会先将请求委派给父加载器,只有当父加载器无法加载时,才会尝试自己加载。它的作用是避免类的重复加载,确保类的唯一性,并防止用户自定义类覆盖核心类库。3.JVM中类加载器的种类有哪些?
Bootstrap ClassLoader:加载JVM核心类库(如rt.jar),由C++实现。
Extension ClassLoader:加载扩展类库(如jre/lib/ext目录下的类)。
Application ClassLoader:加载应用类路径(classpath)中的类。
Custom ClassLoader:用户自定义类加载器,通过继承ClassLoader实现。
如何自定义类加载器?
自定义类加载器需要继承ClassLoader类,并重写findClass(String name)方法。通常还需要实现loadClass方法来实现双亲委派机制。
示例代码:
java
复制
public class MyClassLoader extends ClassLoader {@Overrideprotected Class<?> findClass(String name) throws ClassNotFoundException {byte[] classData = loadClassData(name);if (classData == null) {throw new ClassNotFoundException();}return defineClass(name, classData, 0, classData.length);}private byte[] loadClassData(String name) {// 加载类文件的字节码// 示例:从文件系统加载try {String fileName = name.replace('.', File.separatorChar) + ".class";InputStream in = new FileInputStream(fileName);ByteArrayOutputStream out = new ByteArrayOutputStream();int b;while ((b = in.read()) != -1) {out.write(b);}return out.toByteArray();} catch (IOException e) {e.printStackTrace();}return null;}
}
自定义类加载器时需要注意哪些问题?
确保遵循双亲委派机制,避免类的重复加载。
注意线程安全问题。
确保加载的字节码符合JVM规范。
避免内存泄漏。4. JVM运行时数据区
JVM运行时数据区有哪些部分组成?
堆(Heap):存储对象实例和数组。
方法区(Method Area):存储类的结构信息,如常量池、字段、方法等。
Java栈(Java Stack):存储局部变量、操作数栈和方法调用信息。
本地方法栈(Native Method Stack):支持本地方法的执行。
程序计数器(Program Counter Register):记录当前线程执行的字节码指令地址。5.Java堆(Heap)的作用是什么?为什么需要分代设计?
作用:堆是JVM管理内存的主要区域,用于存储对象实例和数组。
分代设计:为了提高垃圾回收效率,堆被分为年轻代和老年代。年轻代存储新创建的对象,老年代存储经过多次回收仍然存活的对象。分代设计可以针对不同类型的对象采用不同的回收策略,提高回收效率。
方法区、元空间和持久代的关系是什么?
方法区:JVM规范中定义的区域,用于存储类的结构信息。
持久代(Permanent Generation):JDK 1.7及之前的实现,方法区的物理实现。
元空间(Metaspace):JDK 1.8引入的替代持久代的区域,使用本地内存,避免了持久代的内存溢出问题。
J6.Java栈和本地方法栈的区别是什么?
Java栈:用于存储Java方法的调用信息,如局部变量表、操作数栈等。
本地方法栈:用于支持本地方法(如JNI调用)的执行,存储本地方法的调用信息。
程序计数器的作用是什么?
程序计数器记录当前线程执行的字节码指令地址。如果当前线程正在执行Java方法,则记录字节码指令的地址;如果正在执行本地方法,则为undefined。程序计数器是线程私有的,每个线程都有自己的程序计数器。7. 栈帧结构与动态链接
栈帧的结构是怎样的?
栈帧是方法调用的内存模型,每个方法调用都会创建一个新的栈帧。栈帧结构包括:
局部变量表:存储方法参数和局部变量。
操作数栈:用于存储操作数和中间结果。
动态链接:将常量池中的符号引用转换为直接引用。
方法出口信息:记录方法返回地址等信息。8.动态链接的作用是什么?
动态链接是指在运行时将常量池中的符号引用转换为直接引用。它允许在运行时解析类、方法和字段的引用,从而支持多态和动态绑定。9.如何理解局部变量表和操作数栈?
局部变量表:存储方法参数和局部变量,每个变量占用一个槽(slot)。局部变量表的大小在编译时确定。
操作数栈:用于存储操作数和中间结果。操作数栈的大小也在编译时确定。操作数栈支持栈操作,如压栈(push)和弹栈(pop)。10. 垃圾回收机制
垃圾回收的触发条件是什么?
堆内存不足:当堆内存无法分配新对象时,触发垃圾回收。
Eden区满:在分代收集中,当Eden区满时,触发Minor GC。
老年代内存不足:当老年代内存不足时,触发Full GC。
元空间不足:当元空间内存不足时,也可能触发垃圾回收。11.常见的垃圾回收算法有哪些?
标记-清除算法:标记活动对象,清除未标记的对象。缺点是会产生内存碎片。
标记-整理算法:标记活动对象,并将活动对象移动到内存的一端,整理内存空间。
复制算法:将内存分为两块,每次只使用一块,当一块内存用满时,将活动对象复制到另一块内存中。
标记-清除算法和标记-整理算法的区别是什么?
标记-清除算法:标记活动对象,清除未标记的对象。优点是简单,缺点是会产生内存碎片。
标记-整理算法:标记活动对象,并将活动对象移动到内存的一端,整理内存空间。优点是减少内存碎片,缺点是需要移动对象,可能导致性能开销。
分代收集算法的工作原理是什么?
分代收集算法将堆分为年轻代和老年代。年轻代使用复制算法,老年代使用标记-整理算法或标记-清除算法。年轻代的垃圾回收称为Minor GC,老年代的垃圾回收称为Full GC。12.常见的垃圾收集器有哪些?它们的优缺点是什么?
Serial收集器:单线程收集器,适合单核处理器。优点是简单高效,缺点是会暂停所有线程(Stop-The-World)。
Parallel收集器:多线程收集器,适合多核处理器。优点是吞吐量高,缺点是会暂停所有线程。
CMS收集器:并发标记-清除收集器,适合低延迟场景。优点是并发执行,减少停顿时间,缺点是会产生内存碎片。
G1收集器:分区收集器,适合大堆内存。优点是分区收集,减少停顿时间,缺点是配置复杂。
ZGC:低延迟垃圾收集器,适合超大堆内存。优点是低延迟,缺点是资源消耗较高。13.如何选择合适的垃圾收集器?
根据应用的场景选择垃圾收集器:
如果应用对延迟要求不高,可以选择吞吐量优先的收集器(如Parallel收集器)。
如果应用对延迟要求高,可以选择低延迟的收集器(如CMS收集器或G1收集器)。
如果堆内存较大,可以选择分区收集器(如G1收集器或ZGC)。14.G1垃圾收集器的工作原理是什么?如何调优?
工作原理:G1收集器将堆内存划分为多个大小相等的区域(Region),分为Eden区、Survivor区和老年代区。G1通过并发标记和分区收集的方式,减少停顿时间。
调优:
使用-XX:G1HeapRegionSize设置区域大小。
使用-XX:MaxGCPauseMillis设置最大停顿时间目标。
使用-XX:G1NewSizePercent和-XX:G1MaxNewSizePercent调整新生代大小。15.ZGC的特点是什么?
低延迟:ZGC的目标是将停顿时间控制在10ms以内。
高吞吐量:支持大堆内存(如TB级)。
并发执行:大部分垃圾回收工作与应用线程并发执行。
如何判断是否适用G1垃圾收集器?
应用堆内存较大(如大于4GB)。
应用对延迟要求较高。
应用的新生代和老年代对象比例差异较大。16. JVM性能优化
JVM性能优化的常用方法有哪些?
调整堆大小:根据应用需求调整堆大小(-Xms和-Xmx)。
选择合适的垃圾收集器:根据应用需求选择合适的垃圾收集器。
调整垃圾收集器参数:根据应用需求调整垃圾收集器参数(如-XX:MaxGCPauseMillis)。
减少内存泄漏:通过工具(如JProfiler、VisualVM)检测和修复内存泄漏。
优化代码:减少不必要的对象创建和大对象分配。17.如何分析JVM的性能问题?
使用JVM监控工具(如VisualVM、JProfiler)监控JVM的性能指标,如堆内存使用情况、垃圾回收频率、线程状态等。
使用jstack、jmap、jstat等命令行工具分析线程堆栈、堆内存和垃圾回收情况。
分析GC日志,了解垃圾回收的频率和停顿时间。18.JVM常用命令有哪些?它们的作用是什么?
jps:列出当前Java进程。
jstack:打印线程堆栈信息,用于分析线程状态和死锁问题。
jmap:生成堆转储文件,用于分析内存泄漏和内存使用情况。
jstat:监控垃圾回收情况,如Eden区、Survivor区和老年代的使用情况。
jcmd:发送命令到Java进程,如触发GC、生成堆转储文件等。
相关文章:

JVM相关面试题
1. 类加载与双亲委派机制 聊一下你对类加载器的理解。 类加载器是JVM用来加载类文件到内存的组件。它负责将字节码文件解析为java.lang.Class实例,并存储到运行时数据区的方法区中。类加载器分为Bootstrap ClassLoader、Extension ClassLoader和Application ClassLo…...

WiFi定位:宠物安全的“秘密武器”
从「全网寻狗」到「实时掌控」的进化史 凌晨三点收到邻居转发的「寻狗启事」,配图里的金毛犬项圈上赫然挂着某品牌定位器 —— 这样的魔幻场景在养宠圈并不罕见。随着宠物经济突破 3000 亿规模,智能定位器早已从「小众玩具」变成「刚需装备」。但你知道…...

【git】【reset全解】Git 回到上次提交并处理提交内容的不同方式
Git 回到上次提交并处理提交内容的不同方式 在 Git 中,若要回到上次提交并对提交内容进行不同处理,可使用 git reset 命令搭配不同选项来实现。以下为你详细介绍操作步骤及各选项的作用。 1. 查看提交历史 在操作之前,可通过以下命令查看提…...

【leetcode hot 100 11】移动零
一、暴力解法:两个 for 循环,外层循环遍历所有可能的左边界,内层循环遍历所有可能的右边界 class Solution {public int maxArea(int[] height) {int max_area0;for(int i0; i<height.length; i){for(int ji1; j<height.length; j){in…...

DeepSeek 部署实战:Ollama + 多客户端 + RAG
DeepSeek 部署实战:Ollama 多客户端 RAG 一、前置条件 (一)硬件要求 GPU:强烈建议使用 NVIDIA RTX 3090 或更高型号,显存至少 24GB。小显存跑大模型会遇到诸多问题,本人亲测 2080Ti 跑模型体验不佳。内…...

Linux通过设备名称如何定位故障硬盘
因为ceph集群的服务器硬盘都是直通的,当我们发现有硬盘存储坏道需要更换硬盘,但是因为盘序可能不是连续的,无法定位服务器上那块硬盘是故障的,如果冒然测试可能把正常的硬盘拔出,得不偿失,所以就写一下我定…...

大模型基础概念之神经网络宽度
在大模型中,神经网络宽度是提升模型容量的核心手段之一,与深度、数据规模共同构成性能的三大支柱。合理增加宽度可显著增强模型表达能力,但需结合正则化、硬件优化和结构设计进行平衡。未来趋势可能包括动态宽度调整、稀疏化宽度设计(如MoE)以及更高效宽度-深度复合缩放策…...

数据开发的简历及面试
简历 个人信息: 邮箱别写QQ邮箱, 写126邮箱/189邮箱等 学历>>本科及以上写,大专及以下不写 专业>>非计算机专业不写 政治面貌>>党员写, 群众不用写 掌握的技能: 精通 > 熟悉 > 了解 专业工具: 大数据相关的 公司: 如果没有可以写的>>金融服…...

数据存储:一文掌握存储数据到ElasticSearch详解
文章目录 一、Elasticsearch简介二、Python与Elasticsearch交互2.1 安装必要的库2.2 连接到Elasticsearch服务器 三、数据准备四、创建索引(可选)五、存储数据5.1 单个文档索引5.2 批量索引 六、查询数据七、更新和删除数据7.1 更新文档7.2 删除文档 八、…...
)
Pytorch使用手册--将 PyTorch 模型导出为 ONNX(专题二十六)
注意 截至 PyTorch 2.1,ONNX 导出器有两个版本。 torch.onnx.dynamo_export 是最新的(仍处于测试阶段)导出器,基于 PyTorch 2.0 发布的 TorchDynamo 技术。 torch.onnx.export 基于 TorchScript 后端,自 PyTorch 1.2.0 起可用。 一、torch.onnx.dynamo_export使用 在 60 …...

Vue2+Element实现Excel文件上传下载预览
目录 一、需求背景 二、落地实现 1.文件上传 图片示例 HTML代码 业务代码 2.文件下载 图片示例 方式一:代码 方式二:代码 3.文件预览 图片示例 方式一:代码 方式二:代码 一、需求背景 在一个愉快的年后ÿ…...

物联网平台建设方案一
系统概述 构建物联网全域支撑服务能力,为实现学院涵盖物联网设备的全面感知、全域互联、全程智控、全域数字基底、全过程统筹管理奠定基础,为打造智能化提供坚实后台基石。 物联网平台向下接入各种传感器、终端和网关,向上通过开放的实施分…...

机器学习破局指南:零基础6个月系统训练计划
以下是为零基础学习者制定的「机器学习」系统学习计划(含学习路径资源推荐),分为6个阶段,建议学习周期4-6个月: 一、基础准备阶段(1-2周) 目标:掌握必要数学工具与编程基础 数学基础…...

mmdetection框架下使用yolov3训练Seaships数据集
之前复现的yolov3算法采用的是传统的coco数据集,这里我需要在新的数据集上跑,也就是船舶检测方向的SeaShips数据集,这里给出教程。 Seaships论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber8438999 一、…...
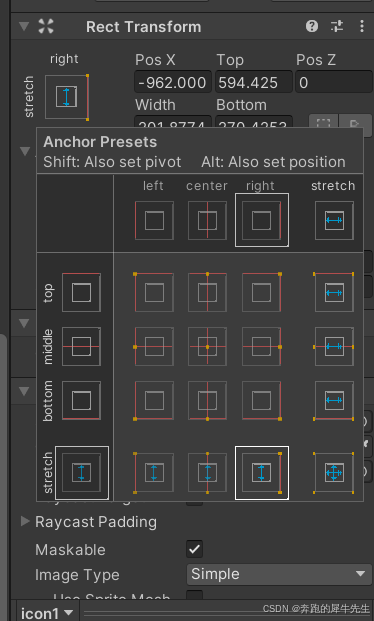
unity学习52:UI的最基础组件 rect transform,锚点anchor,支点/轴心点 pivot
目录 1 image 图像:最简单的UI 1.1 图像的基本属性 1.2 rect transform 1.3 image的component: 精灵 → 图片 1.4 修改颜色color 1.5 修改材质 1.6 raycast target 1.7 maskable 可遮罩 1.8 imageType 1.9 native size 原生大小 2 rect transform 2.1 …...

STM32MP15-FSMP1A单片机移植Linux系统platform总线驱动
之前在该单片机下移植的Linux驱动是学习过程中,对Linux内核驱动的引导学习,接下来才是比较正常的驱动开发。 在Linux内核中,对于驱动的处理,一般会通过总线进行设备信息和设备驱动的匹配,来达到自动检测外设连接系统以…...
)
Java 常见的面试题(设计模式)
一、说一下你熟悉的设计模式? **设计模式:**是一套被反复使用的代码设计经验的总结(情境中一个问题经过证实的一个解决方案)。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。设计模式使人们可以更加简…...

机器学习3-聚类
1 聚类解决的问题 知识发现,发现事物之间的潜在关系异常值检测特征提取 数据压缩的例子新闻自动分组、用户分群、图像分割、像素压缩等等 2 与监督学习比较 监督学习是需要给定X、Y,X为特征,Y为标签,选择模型,学习&a…...

html中的css
css (cascading style sheets,串联样式表,也叫层叠样式表) css规范一般约定: 1.存放CSS样式文件的目录一般命名为style或css。 2.在项目初期,会把不同类别的样式放于不同的CSS文件,是为了CSS编…...

36. Spring Boot 2.1.3.RELEASE 中实现监控信息可视化并添加邮件报警功能
1. 创建 Spring Boot Admin Server 项目 1.1 添加依赖 在 pom.xml 中添加 Spring Boot Admin Server 和邮件相关依赖: <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-w…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...

搞定这 5 个全栈电商项目,面试别再用 Todo-List 凑数了
找独立开发练手项目或者写简历项目时,最忌讳两件事:一是太简单(纯前端 Mock 数据,点两下就没了),二是太假(一上来就硬套微服务、消息队列、高并发,结果自己根本Hold不住)…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...

BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器
BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...

终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式
终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多个窗口间来回切换,浪费宝…...