小红书湖仓架构的跃迁之路
作者:李鹏霖(丁典),小红书-研发工程师,StarRocks Contributor & Apache Impala Committer
本文整理自小红书工程师在 StarRocks 年度峰会上的分享,介绍了小红书自助分析平台中,StarRocks 与 Iceberg 结合后,如何实现极速湖仓分析架构。
与原有架构相比,湖上分析架构的 P90 查询性能提升了 3 倍,目前查询 响应时间 稳定在 10 秒以内。 同时,采用 Iceberg 存储格式后,尽管数据量和行数保持不变,但实际存储空间相较原有 ClickHouse 存算分离版本减少了一半。
RedBI 自助分析是小红书数据平台下的一款可视化、即席查询分析工具,专为分析师设计。它支持通过简单的拖拽操作完成数据分析,并在秒级返回查询结果,核心特点可以总结为: 灵活、快速、自助 。
下图为自助分析平台的原始架构,其核心是小红书内部自研存算分离版本的 ClickHouse。通过存算分离和智能缓存,不仅延长了数据集的生命周期,还能根据业务使用习惯将热点数据缓存在本地,从而实现接近存算一体架构的查询性能。

在数据分析流程中,分析师首先与数据仓库团队讨论数据需求。根据需求,数据仓库团队会创建相应的数据集,并在小红书的大数据研发管理平台 Dataverse 上开发 Hive2CK 类型的 ETL 任务。
Hive2CK 任务 是一种基于 Spark 的数据处理任务,主要从上游的 Hive 表中获取数据。处理后的数据会先写入 OSS(对象存储服务),然后通过 ClickHouse 将这些文件加载至其系统中,根据用户的使用习惯将热点数据缓存至本地,确保最终提供给用户查询。
原架构痛点
首先,随着业务需求的快速增长和分析师使用习惯的不断变化,最初基于与数据仓库团队沟通制定的索引策略逐渐失效,导致数据集的查询性能出现明显下降。现有架构没有灵活的机制来根据分析需求和使用习惯动态调整排序键与索引,因此导致 查询性能下降 。
其次,ClickHouse 在支持 Join 操作方面存在一定限制。尽管可以为部分数据集建立 Colocate Join,但其桶数与集群节点绑定的方式,使得扩容或缩容时,节点数和桶数之间的依赖关系增加了操作复杂度。此外,维度表无法复用,Join Key 的绑定程度过高,使得不同数据集之间的 Join 操作灵活性受限。

最后,数据的访问方式也存在一定局限。目前的数据访问只能通过 ClickHouse 查询,缺乏更灵活的方式,尤其在一些场景下,某些数据需要根据不同的分析需求进行读取。如果继续依赖 ClickHouse 来读取这些数据,可能会对线上服务产生影响,导致系统在处理多样化需求时,性能和效率遭遇瓶颈。
这些问题不仅影响了查询性能,也限制了平台的扩展性和自助性,迫切需要找到一套有效的解决方案来应对当前架构的挑战。
湖上分析架构
随着原架构暴露出的性能瓶颈和灵活性限制,我们开始寻求更加高效的解决方案。在此背景下,RedBI 自助分析平台的架构进行了重大升级,采用了新的湖上分析架构。
首先,原有的 Hive2CK 替换为 Hive2Iceberg,数据存储格式转为 Parquet。与 ClickHouse 存储格式相比,这种转变不仅在支持各自最优压缩算法的前提下,实现了更高的压缩率, 实际应用中的压缩比提升了近一倍 。此外,StarRocks 作为 OLAP 查询引擎,具备了出色的扩缩容能力和快速的响应速度。
与此同时,依托 StarRocks 的 DataCache 功能,查询性能不再依赖于网卡 I/O。通过将热点数据缓存至本地 BE 节点,避免了频繁的远程数据拉取,进一步提升了查询的稳定性和响应速度。

在年初立项前,我们对湖上分析架构进行了 POC 测试。测试集选取了当时自助分析中排名前十的热门数据集,并模拟了 N 天内的实际查询场景。测试结果表明,与原有架构相比, 湖上分析架构的 P90 查询性能实现了 3 倍的提升。

排序键 保鲜能力
为了应对随着时间推移数据集查询性能下降的问题,我们设计了一套湖上分析数据集智能优化的解决方案。
-
扩展 StarRocks 的审计日志插件,新增了 Iceberg ScanReport 的关键信息(如 nonPartFilterCols、resultDataFiles 和 dataInBytes)。
-
结合审计日志数据与表统计信息,预估用户的使用习惯,智能选择排序列。
-
针对新增分区数据,通过异步 ZOrder 排序任务优化非分区列的 DataSkip 效果,从而实现排序键和索引的持续优化。
提升数据集的自助性
针对多表分析场景(如自助分析人群包维表和笔记维表),当前,分析平台采用了 Broadcast Join / InSubQuery 的方式进行处理,这相较于传统的 Colocate Join 具有显著的性能优势。由于 Broadcast Join 不依赖于节点绑定,它使得扩容与缩容变得更加灵活,能够根据业务需求动态调整,而不受固定节点数的限制。
为了进一步提升数据集的自助性,我们引入了灵活配置的 JoinKey 策略。原则上,只要能够避免数据倾斜,任何字段都可作为 JoinKey。不过,考虑到当前集群规模与平台性能要求,我们对可进行 Shuffle Join 的维表数量做出了限制,最多支持与主表进行关联的 四个维表 ,以避免影响其他数据集的快速响应。
取数灵活
湖上数据集的存储与查询完全分离,赋予了更高的灵活性。用户可以直接通过 SQL 在公共 OLAP 资源池中进行启发式和探索式查询,既满足了多样化需求,又避免了对特定引擎或集群的依赖。
Data Skipping
-
关于排序的优化:
当我们在 DLF (Data Lake Formation)中检测到大部分拖拽查询都集中在某一列时,可以采用 线性排序 来提升效率。而对于两列或三列的场景,可以进一步考虑多维排序。需要注意的是,排序列通常不会超过三列,这样既能保证查询性能,又避免了复杂度过高的问题。
-
Z-Order排序:

Z-Order(也称为Z-Order Curve)是一种空间填充曲线,用于将多维数据映射到一维数据中。Z-Order 本质上是一种对多维数据进行排序的方式,它通过将多个维度的坐标交替地排列在一起,从而形成一个线性索引。
Z-Order 通过将数据点在多维空间中的坐标进行交替二进制编码,然后根据这些编码来排序。例如,在二维空间中,假设一个点有两个维度(x, y),我们可以将 x 和 y 的二进制位交替排列,形成一个新的值。对于更高维度的数据,Z-Order 会扩展此方法。在二维情况下,如果一个点的坐标是 (x, y),而 x 和 y 的二进制表示分别为:
-
x = 3 → 011
-
y = 5 → 101
那么,Z-Order 会将这两个二进制值交替取各位形成成:
-
z = 0, 1, 1, 0, 1, 1
Z-Order 的关键在于它可以对多维数据进行有效的线性排序,这种排序在某些查询模式下具有很好的性能表现,尤其是范围查询。
-
DataFile ( Parquet file)非分区列 min-max 索引
Iceberg 具备“DataFile(Parquet 文件)非分区列的 Min-Max 索引”功能,具体表现为:
-
无需打开具体的 Parquet 文件,用户即可通过 Iceberg 元数据访问该索引。
-
在经过上述排序后,Parquet 文件内部数据将呈现有序结构。结合 Min-Max 索引特性,Iceberg 能在前端(FE)执行谓词下推,从而显著提升数据湖分析的性能。

上图展示了 Iceberg 的整体结构,元数据文件中的 ManifestFile 包含了大量 DataFile 级别的指标,例如:
DataFile.RECORD_COUNT,
DataFile.FILE_SIZE,
DataFile.COLUMN_SIZES,
DataFile.VALUE_COUNTS,
DataFile.NULL_VALUE_COUNTS,
DataFile.NAN_VALUE_COUNTS,
DataFile.LOWER_BOUNDS,
DataFile.UPPER_BOUNDS,
...

有了全部 DataFile 中非分区列的 min-max 索引数据,就可以做谓词下推。在 OLAP 引擎创建查询计划时,通过 org.apache.iceberg.Scan#planFiles 接口,根据 WHERE 子句中的谓词和 min-max 索引数据进行 DataFiles 级别的过滤,从而显著提升查询性能。
参考:
https://github.com/apache/iceberg/blob/main/api/src/main/java/org/apache/iceberg/TableScan.java
https://github.com/apache/iceberg/blob/main/api/src/main/java/org/apache/iceberg/DataFile.java
智能选择 Z-Order 排序键

为解决 ClickHouse 索引键保鲜度较低 的问题,我们设计了一种基于用户行为记录的智能排序键选择与更新机制,应用于 自助分析平台 ,并通过 Z-Order 排序 提升查询效率。上图红框展示了这一机制的核心流程。
具体实现步骤如下:
-
StarRocks 审计日志插件: 记录每个查询中每个表的下推的非分区列信息,以及 planFiles 接口返回的迭代器中涉及的 DataFiles 总 Bytes 等信息。
-
数据湖管理平台 (DLF): 通过分析审计日志,智能推断出自助分析数据集中的表的候选排序列。根据这些列的NDV(不同值数量)做一层筛选,最终系统会自动在 Dataverse 平台创建和更新rewrite_zorder_dataFiles 任务。
-
Dataverse 平台 :具有任务血缘能力,确保在上游 hive2iceberg 任务完成后,自动触发 rewrite_zorder_dataFiles 任务。
-
异步执行: rewrite_zorder_dataFiles 任务的执行是异步的,依赖于 Iceberg 的原子提交(atomiccommit)机制,分析师用户不感知整个优化过程。
StarRocks x Iceberg JOIN
在自助分析场景中,用户对数据集自助性的需求不断提升,尤其是在 JoinKey 灵活选择 上。StarRocks 支持成熟的 Shuffle Join 和 Broadcast Join 能力,不受分桶数或集群节点扩缩容的影响,能够快速扩展原数据集的 JoinKey。用户只需审批通过,即可在 分钟级 内完成新 JoinKey 的上线配置。


在项目中期阶段,湖上数据集的覆盖率已经达到 50%。然而,由于大多数数据集是从 ClickHouse 迁移而来的单表数据,且当时机型无法满足 DataCache 的使用需求,分析任务仍依赖从 OSS 读取 Parquet 文件。这种情况下,随着用户需求从单表分析转向多表数据集配置,Shuffle Join 的使用频率激增,网卡带宽逐渐成为性能瓶颈。
为解决这一问题,我们首先针对规模较大的多表数据集,选择采用 Iceberg 分桶表(10 桶) 的方式优化数据分布。同时,在 StarRocks 中引入对 Iceberg 分桶表的 Colocate Join 和 Bucket Join 支持,减少 Shuffle Join 对网卡带宽的依赖,从而缓解性能压力。在这一阶段,我们优先缓解网卡带宽瓶颈,待机型满足要求后,再逐步引入 DataCache ,通过本地磁盘读取替代从 OSS 读取数据的方式。
随着 DataCache 的引入,网卡带宽几乎完全腾出来用于 Shuffle Join 和 Broadcast Join,这不仅提升了性能,也保留了对 JoinKey 的灵活扩展能力。即使在使用分桶表时,仍能够兼顾 Shuffle Join 的扩展性,无需考虑集群节点数量的问题, 提高数据集自主性 。
排序列选取算法
在数据湖管理平台中,为提升查询性能和优化数据存储结构,排序列的筛选显得尤为重要。以下是排序列选取算法的具体规则和条件:
-
唯一值数量 (NDV)
排序列的候选字段需要具备足够的区分度。因此,算法会筛选唯一值数量(NDV)不少于 15 的列,以避免因低区分度而导致的排序效果较差。
-
频次比例
某列的查询使用频率,即列的使用次数与该表的查询总次数的比值,应不少于 0.15。这一条件确保排序列是用户查询的核心字段,有助于优化高频使用场景。
-
文件数量
数据分区中文件数量的丰富性是影响排序效果的另一个因素。候选列所在的分区,文件数量应超过 10 个,以确保排序后的数据能覆盖更多文件。
-
频次排名
为进一步提高排序列的筛选精度,算法优先关注查询频次排名前 3 的列。这种方式能够快速锁定用户最常查询的字段,最大化排序优化的收益。
-
查询占比
最后,通过分析列在整体查询中的占比,判断其是否值得进行排序。如果某列的查询占比较低,即便符合其他条件,也可能会被排除在排序列之外,从而避免无效优化。
查询性能优化
Data Skip 效果
随着业务需求的变化,某流量占比较高的数据集经历了多轮迭代和扩展。从最初包含店铺 ID、用户 ID、商品 ID 等基本字段,到逐步加入直播间 ID 和用户浏览笔记 ID 等信息,该数据集的字段不断丰富以满足日益复杂的分析需求。
为了应对这种动态变化,我们通过调整 Z-Order 排序任务中的排序列(sort_order),实现对数据的动态优化。具体来说,根据分析师的使用习惯和 T+1 阶段反馈,及时调整排序方式,使得新增数据可以更贴近近期用户的查询模式。值得注意的是,这一优化完全异步进行,不会影响历史数据,用户也无需感知优化过程即可受益。
优化完成后,该数据集的某些常用查询模式显著受益,占整体查询的比例达到 30%。从优化后的统计图表可以看到,Data Skip 技术在减少数据扫描量上效果明显,当前每日扫描数据量与优化后的 Data Skip 数据量形成了鲜明对比。

Data Cache
在数据湖分析场景中,StarRocks作为OLAP查询引擎,需要高效地扫描存储在对象存储(如OSS)中的 Parquet 文件。以小红书自助分析平台为例,频繁访问相同的数据会导致重复的网络I/O开销,尤其是在数据是 T+1 产出时。此时,带宽资源往往不能充分用于多表数据集的Join操作。为了优化这一问题,StarRocks 自 2.5 版本引入了 DataCache 功能。
StarRocks DataCache 通过将外部存储系统中的原始数据切分成多个数据块,并将这些块缓存到StarRocks本地的BE节点,从而减少了重复的远程数据拉取开销。这样,热点数据可以被缓存到本地,显著提升了查询和分析的性能。根据测试数据, 集群的 P90 查询性能提升约 20% 。需要注意的是,缓存的块位置与节点数量紧密相关。当集群进行扩缩容操作时,部分缓存会失效,导致一些数据块不再有效。
为了解决扩缩容后缓存失效的问题,当前的解决办法是安排在夜间进行扩缩容,并在扩缩容完成后重新运行当天的查询。这样,数据缓存会重新分布,并确保缓存的有效性。这一策略保证了在集群扩缩容后,DataCache功能能够快速恢复。

在我们的实际场景中,针对线上的两个典型查询案例进行了分析,截取了查询的执行Profile,结果显示,DataCache的命中率相当高,几乎达到理想状态。这个效果的原因主要有以下几点:
首先,由于数据集大多属于T+1级别的数据,上午生成的数据在下午一般不会发生变化。这样一来,用户查询的数据集基本保持一致,查询模式趋于稳定。这种情况下,DataCache能够高效缓存热点数据,减少了重复的数据拉取,显著提升了查询性能。
其次,每天的查询习惯大致相同,尤其是同一天内,用户查询的需求往往会集中在相似的时间段和数据范围。因此,数据缓存策略能够在用户查询峰值时,提供足够的缓存支持,从而减少了带宽消耗,并加速了查询响应。

通过对比开启和关闭DataCache时的监控数据,我们可以在Grafana中清晰地看到,开启DataCache后,网卡流量显著降低,节省的带宽几乎达到了2到3倍。
大查询优化策略

在面对大查询带来的性能瓶颈时,我们实施了大查询优化策略,以确保自助分析平台能够在数据量激增的情况下,继续保持高效的查询响应能力。
随着某些业务的快速增长,新数据分区的数量急剧增加,导致某些查询涉及的单个分区数据量大幅上升。例如,某些数据集的单分区数据量从年初的100亿,已经增长至目前的200多亿。这种数据量的增长可能会导致查询过慢,甚至影响系统的整体性能,特别是在没有有效优化的情况下。
为了应对这一挑战,我们为StarRocks中的Iceberg表实现了 EXPLAIN ESTIMATE 功能。该功能能够在实际查询之前估算查询的数据量。如果预估结果显示查询的数据量超过某个设定的阈值,系统会智能地将查询请求引导到一个规模较小的StarRocks集群,或者是Spark集群来执行,从而避免超大查询占用过多计算资源。这不仅减少了对其他查询的影响,也降低了查询超时的风险。

从性能监控数据来看,开启此优化功能后,整体集群的CPU使用率得到了有效控制。特别是在大查询出现时,CPU的负载没有急剧攀升,避免了计算资源的过度消耗。相对而言,P90响应时间在开启该优化后表现更为平稳,避免了因资源过载而导致的性能急剧下降。
项目收益
根据我们的测量结果,从年初到现在, P90 响应时间提升了三倍,当前的查询响应时间大约可以控制在10秒以内 。
此外,通过优化存储方式,尤其是应用Iceberg的Parquet存储格式(如版本1.12),我们在存储效率上也获得了显著的提升。与原有的ClickHouse存量分离版本相比,采用Iceberg存储后,尽管数据量和行数保持一致, 但实际存储空间减少了一半 。
未来规划
未来规划中,我们将探索结合 StarRocks 和 Paimon 的近实时湖仓分析架构,围绕公司业务需求,进一步优化近实时链路的处理能力,并针对具有主键(PK)需求的湖上分析场景,制定更高效的优化方案。
直播回放:https://www.bilibili.com/video/BV18EC5YuEcA/?vd_source=1cb452610138142d1300dd37a6162a88
延伸阅读:
StarRocks 助力小红书离线数仓提效,提升百倍回刷性能!
StarRocks 在小红书自助分析场景的应用与实践
更多交流,联系我们:StarRocks
相关文章:
小红书湖仓架构的跃迁之路
作者:李鹏霖(丁典),小红书-研发工程师,StarRocks Contributor & Apache Impala Committer 本文整理自小红书工程师在 StarRocks 年度峰会上的分享,介绍了小红书自助分析平台中,StarRocks 与 Iceberg 结合后&#x…...

pytorch高可用的设计策略和集成放大各自功能
在使用 PyTorch 编写模型时,为确保模型具备高可用性,可从模型设计、代码质量、训练过程、部署等多个方面采取相应的方法,以下为你详细介绍: 模型设计层面 模块化设计 实现方式:将模型拆分成多个小的、独立的模块,每个模块负责特定的功能。例如,在一个图像分类模型中,可…...

神经网络前向微分和后向微分区别
1. 计算顺序 前向微分(前向模式) 从输入到输出逐层计算:沿计算图的正向顺序(输入层 → 输出层),同时计算函数值和导数。 每一步同步更新导数:每个中间变量的导数随值一起计算,例如&…...

Android 创建一个全局通用的ViewModel
(推荐)使用ViewModelStore 代码示例: class MyApplication : Application(), ViewModelStoreOwner {private val mViewModelStore ViewModelStore()override fun onCreate() {super.onCreate()}override val viewModelStore: ViewModelSto…...

windows 利用nvm 管理node.js 2025最新版
1.首先在下载nvm 下载链接 2. 下载最新版本的nvm 3. 同意协议 注意:选择安装路径 之后一直下一步即可 可以取消勾选 open with Powershell 勾选后它会自动打开Powershell 这里选用cmd 输入以下命令查看是否安装成功 nvm version 查看已经安装的版本 我之前自…...

基于物联网技术的电动车防盗系统设计(论文+源码)
1总体设计 本课题为基于物联网技术的电动车防盗系统,在此将整个系统架构设计如图2.1所示,其采用STM32F103单片机为控制器,通过NEO-6M实现GPS定位功能,通过红外传感器检测电瓶是否离开位,通过Air202 NBIOT模块将当前的数…...
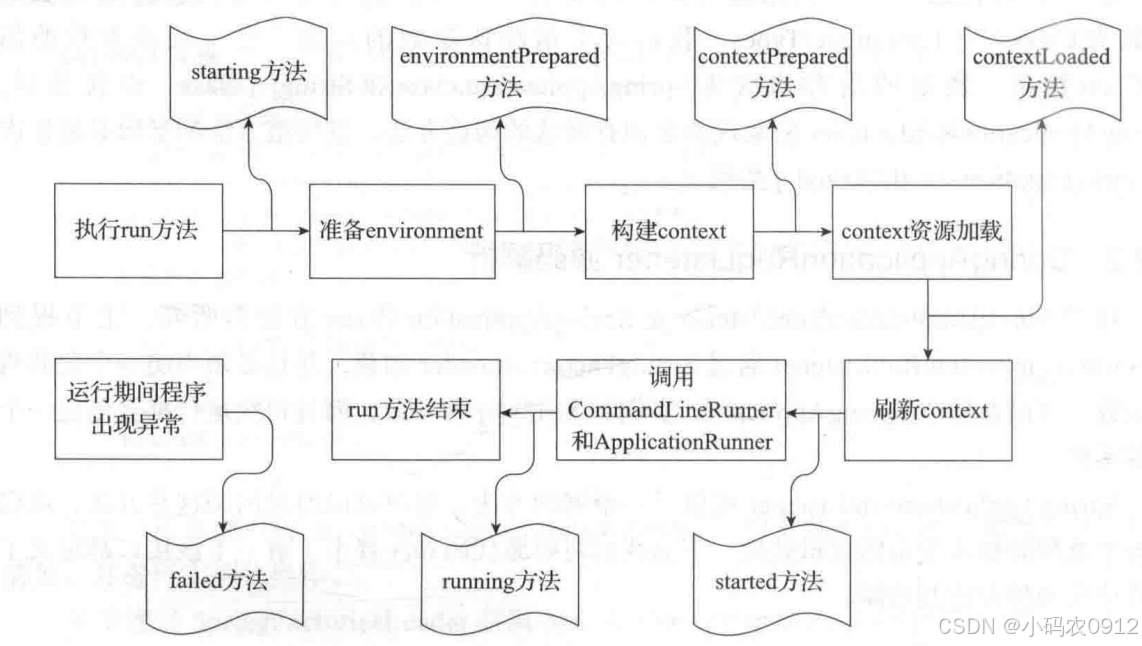
run方法执行过程分析
文章目录 run方法核心流程SpringApplicationRunListener监听器监听器的配置与加载SpringApplicationRunListener源码解析实现类EventPublishingRunListener 初始化ApplicationArguments初始化ConfigurableEnvironment获取或创建环境配置环境 打印BannerSpring应用上下文的创建S…...

关联封号率降70%!2025最新IP隔离方案实操手册
高效运营安全防护,跨境卖家必看的风险规避指南 跨境账号管理的核心挑战:关联封号风险激增 2024年,随着全球电商平台对账号合规的审查日益严苛,“关联封号”已成为跨境卖家最头疼的问题之一。无论是同一IP登录多账号、员工操作失误…...

LeetCode 解题思路 10(Hot 100)
解题思路: 上边: 从左到右遍历顶行,完成后上边界下移(top)。右边: 从上到下遍历右列,完成后右边界左移(right–)。下边: 从右到左遍历底行,完成后…...
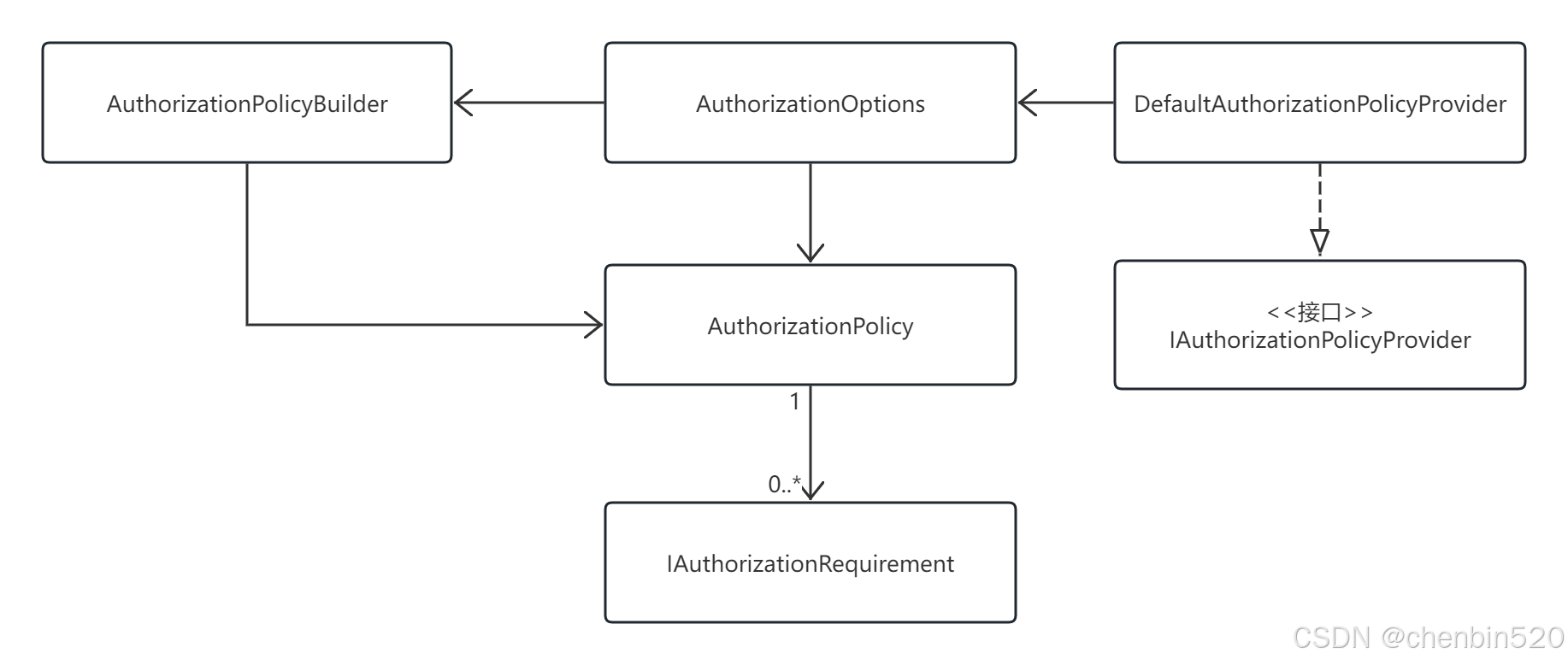
ASP.NET Core JWT认证与授权
1.JWT结构 JSON Web Token(JWT)是一种用于在网络应用之间安全传输声明的开放标准(RFC 7519)。它通常由三部分组成,以紧凑的字符串形式表示,在身份验证、信息交换等场景中广泛应用。 2.JWT权限认证 2.1添…...
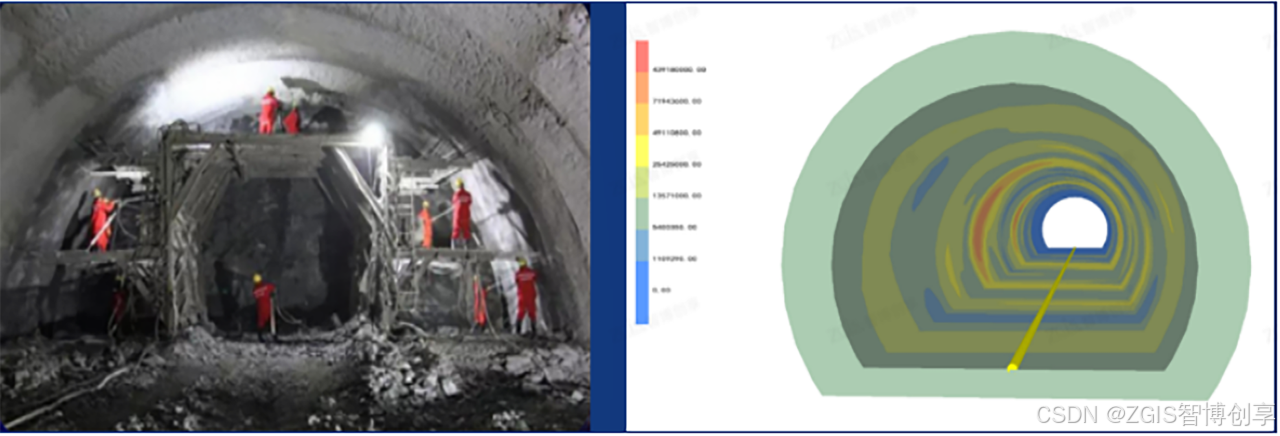
城市地质安全专题连载⑧ | 强化工程地质安全保障力度,为工程项目全栈护航
作者 | 徐海洋、孙美琴 在城市化进程日益加速的今天,城市地质安全问题日益凸显,成为制约城市可持续发展的关键因素之一。从隧道掘进中的突发灾害,到高层建筑地基的稳定性挑战,再到城市地下空间的开发利用风险,地质安全…...

50.xilinx fir滤波器系数重加载如何控制
, 注意:matlab量化后的滤波器系数为有符号数,它是以补码形式存储的,手动计算验证时注意转换为负数对应数值进行计算。...

低代码平台的后端架构设计与核心技术解析
引言:低代码如何颠覆传统后端开发? 在传统开发模式下,一个简单用户管理系统的后端开发需要: 3天数据库设计5天REST API开发2天权限模块对接50个易出错的代码文件 而现代低代码平台通过可视化建模自动化生成,可将开发…...
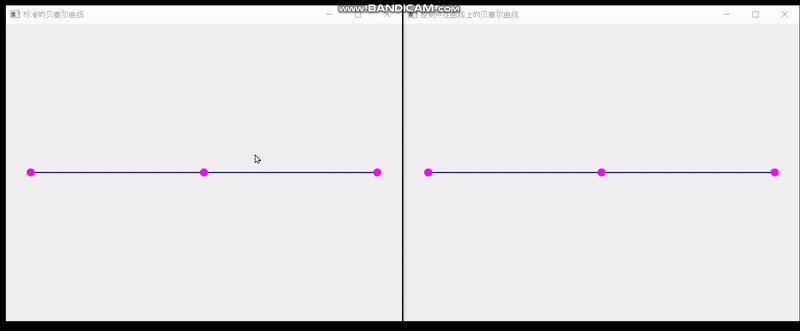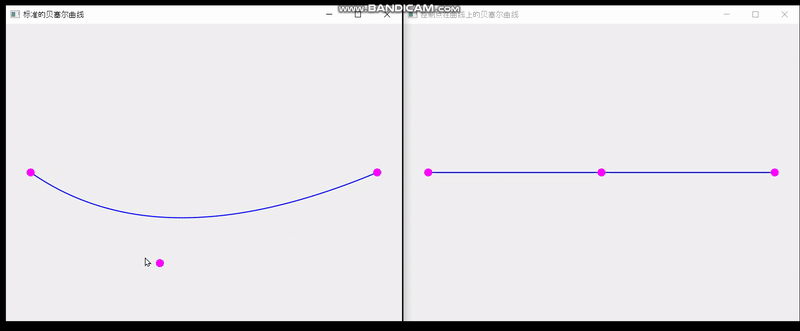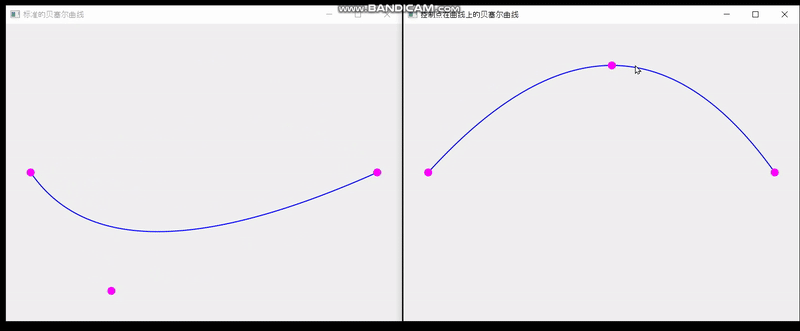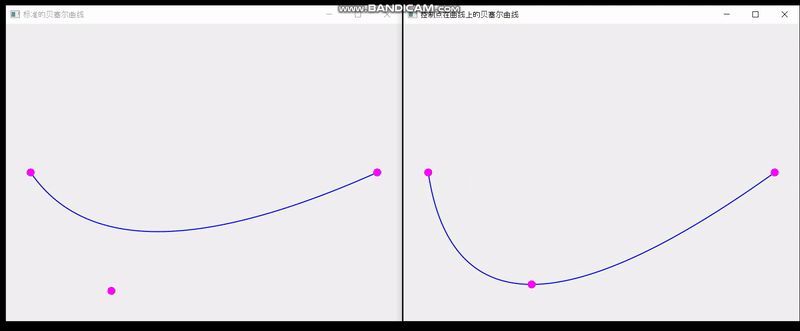
QT实现单个控制点在曲线上的贝塞尔曲线
最终效果: 一共三个文件 main.cpp #include <QApplication> #include "SplineBoard.h" int main(int argc,char** argv) {QApplication a(argc, argv);SplineBoard b;b.setWindowTitle("标准的贝塞尔曲线");b.show();SplineBoard b2(0.0001);b2.sh…...

svn 通过127.0.01能访问 但通过公网IP不能访问,这是什么原因?
连接失败的提示如下 1、SVN的启动方法 方法一: svnserve -d -r /mnt/svn 方法二: svnserve -d --listen-port 3690 -r /mnt/svn 方法三: svnserve -d -r /mnt/svn --listen-host 0.0.0.0 2、首先检查svn服务器是否启动 方法一&#x…...
)
学习DeepSeek V3 与 R1 核心区别(按功能维度分类)
一、定位与架构 V3(通用型模型) 定位:多模态通用大模型,擅长文本生成、多语言翻译、智能客服等多样化任务12。架构:混合专家(MoE)架构,总参数 6710 亿,每次…...

C++中的 互斥量
1.概念: 为什么:线程的异步性,不是按照时间来的!!! C并发以及多线程的秘密-CSDN博客 目的 多线程编程中,当多个线程可能同时访问和修改共享资源时,会导致数据不一致或程序错误。…...
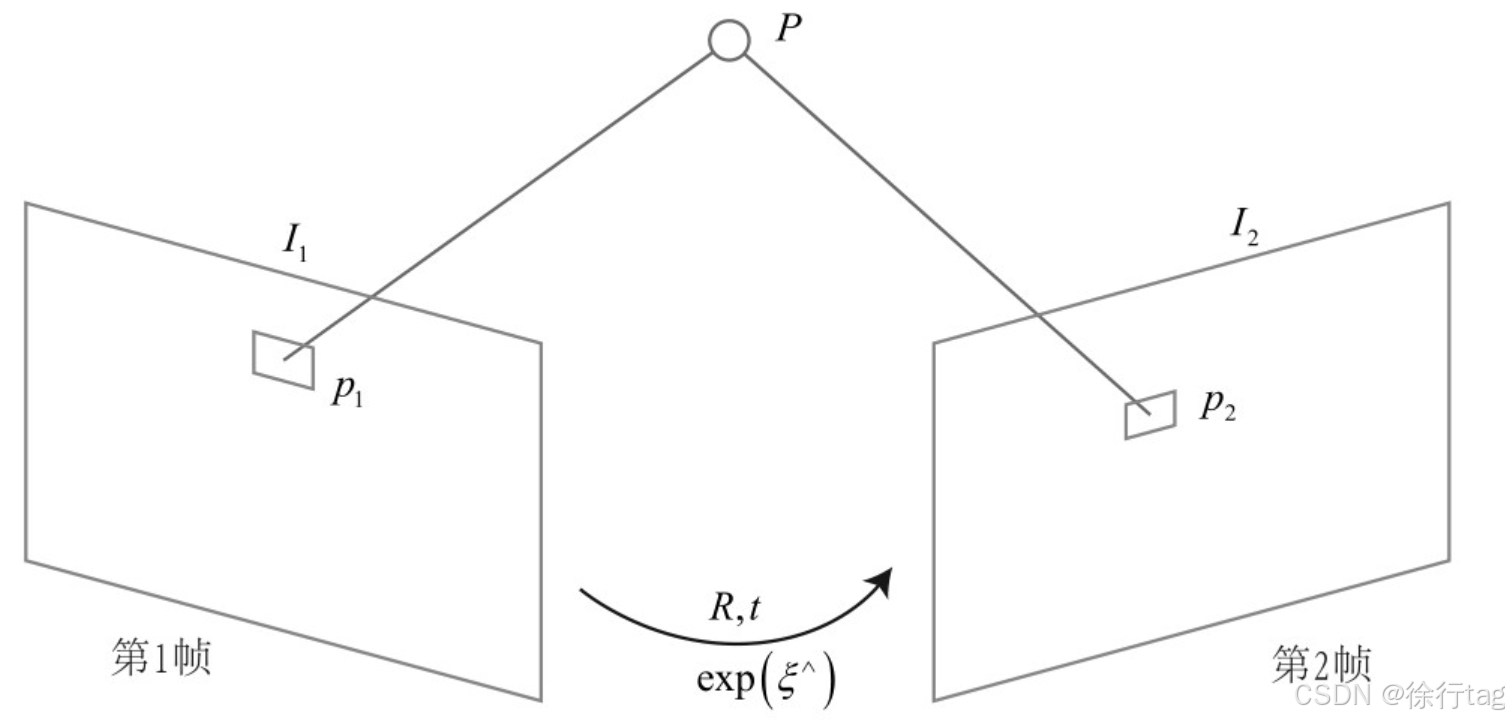
直接法估计相机位姿
引入 在前面的文章:运动跟踪——Lucas-Kanade光流中,我们了解到特征点法存在一些缺陷,并且用光流法追踪像素点的运动来替代特征点法进行特征点匹配的过程来解决这些缺陷。而这篇文章要介绍的直接法则是通过计算特征点在下一时刻图像中的位置…...

PHP动态网站建设
如何配置虚拟主机 1. 学习提纲 本地发布与互联网发布:介绍了如何通过本地IP地址和互联网域名发布网站。 虚拟主机配置与访问:讲解了如何配置虚拟主机,并通过自定义域名访问不同的站点目录。 Web服务器配置:详细说明了如何配置A…...

【gRPC】Java高性能远程调用之gRPC详解
gRPC详解 一、什么是gRPC?二、用proto生成代码2.1、前期准备2.2、protobuf插件安装 三、简单 RPC3.1、开发gRPC服务端3.2、开发gRPC客户端3.3、验证gRPC服务 四、服务器端流式 RPC4.1、开发一个gRPC服务,类型是服务端流4.2、开发一个客户端,调…...

原创丨全球主流开源模型及其衍生生态解析
作者:李媛媛 本文约4800字,建议阅读15分钟本文介绍了全球主流开源基座模型及衍生模型的特点、应用与趋势。在人工智能技术产业化落地加速的当下,开源模型已成为推动行业创新的核心力量,其开放、可定制的特性打破了技术壁垒&#x…...

基于MSP430的太阳能追踪与智能调光系统设计与实现
1. 项目概述与设计初衷最近在折腾一个挺有意思的小项目,起因是看到小区里那些太阳能路灯,总觉得它们有点“傻”。大白天太阳都斜到西边了,电池板还傻愣愣地朝着东边;晚上天都黑透了,灯还亮得晃眼,后半夜路上…...

自制AVR ISP批量编程器:从ZIF插座到AVRDUDE一键烧录全攻略
1. 项目概述:为什么你需要一个批量编程器?如果你玩过Arduino或者自己做过一些基于AVR单片机的小项目,那么对“烧录程序”这个步骤一定不陌生。通常,我们是用一根USB线,或者一个USBasp、USBtinyISP这样的小编程器&#…...

终极英雄联盟工具箱:5个核心功能快速提升你的游戏体验
终极英雄联盟工具箱:5个核心功能快速提升你的游戏体验 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款专为英雄…...

TVA模型适配FPC材料疲劳差异
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

面试题详解:Agent 记忆管理全解析——历史对话获取、摘要记忆、事实记忆、知识图谱记忆一次讲透
1. 什么是 Agent 记忆管理?为什么这件事越来越重要?1.1 如果没有记忆,Agent 就只能“活在当下”很多人第一次接触 Agent 时,会觉得记忆似乎就是保存聊天记录。可一旦系统要跨多轮、多天、甚至跨任务持续工作,就会发现单…...

MOOTDX:Python通达信数据接口的完整指南
MOOTDX:Python通达信数据接口的完整指南 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一个专为量化投资和股票数据分析设计的Python通达信数据接口封装库,它提供…...

深度解析AzurLaneAutoScript:碧蓝航线自动化脚本的技术架构与应用实践
深度解析AzurLaneAutoScript:碧蓝航线自动化脚本的技术架构与应用实践 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript…...

RakkasJS深度解析:基于Bun的全栈React框架性能与迁移实践
1. 项目概述:下一代全栈React框架的探索如果你和我一样,在过去几年里深度使用过Next.js、Remix或者SvelteKit这类全栈框架,那你肯定对它们带来的开发体验又爱又恨。爱的是它们统一了前后端,让全栈开发变得前所未有的顺畅ÿ…...
)
手把手教你用Vivado 2019.1和Tri Mode Ethernet MAC IP,在Artix-7上搞定千兆UDP通信(附RTL8211E/YT8531C/KSZ9031配置)
基于Artix-7的千兆以太网UDP通信实战指南 在嵌入式系统开发中,实现稳定可靠的网络通信一直是工程师面临的挑战之一。特别是当项目需要高速数据传输时,如何选择合适的硬件平台和协议栈就显得尤为重要。本文将聚焦Xilinx Artix-7 FPGA平台,详细…...