第二个机器学习应用:乳腺癌数据集在决策树模型上的挖掘
目录
决策树优化与可视化
1 决策树分类
2 决策树可视化
3 显示树的特征重要性
特征重要性可视化
决策树回归
1 决策树回归
决策树优化与可视化
1 决策树分类
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as npcancer = datasets.load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state = 42)
tree = DecisionTreeClassifier(random_state=0)tree.fit(X_train, y_train)
print("Accuracy on traning set:{:.3f}".format(tree.score(X_train, y_train)))
print("Accuracy on test set:{:.3f}".format(tree.score(X_test, y_test)))
print("tree max depth:{}".format(tree. tree_.max_depth))
# 报错:AttributeError: 'function' object has no attribute 'data' function对象没有data属性
# 解决之后:
#Accuracy on traning set:1.000
#Accuracy on test set:0.937
#tree max depth:7可以得到,训练集的精度是100%,这是因为叶子结点都是纯的,树的深度为7,足以完美地记住训练数据的所有标签,测试集泛化精度只有93.7%,明显过拟合。
不限制决策树的深度,它的深度和复杂度都可以变得特别大。故未剪枝的树容易过拟合,对新数据的泛化性能不佳。
现在将预剪枝应用在决策树上,可以阻止树的完全生长。
设置max_depth=4,这表明构造的决策树只有4层,限制树的深度可以减少过拟合,这会降低训练集的精度,但可以提高测试集的精度。
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as npcancer = datasets.load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state = 42)
tree = DecisionTreeClassifier(max_depth=4, random_state=0)
tree.fit(X_train, y_train)
print("Accuracy on traning set:{:.3f}".format(tree.score(X_train, y_train)))
print("Accuracy on test set:{:.3f}".format(tree.score(X_test, y_test)))Accuracy on traning set:0.988
Accuracy on test set:0.951训练精度为98.8%,测试精度为95.1%,树的最大深度只有4层,降低了训练精度,但提高了泛化(测试)精度,改善了过拟合的状况。
2 决策树可视化

使用 pip3 install graphviz 后, import graphviz 仍然报错:
ModuleNotFoundError: No module named 'graphviz'使用命令:conda install python-graphviz;
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
import graphviz
from sklearn.tree import export_graphviz
cancer = datasets.load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state = 42)
tree = DecisionTreeClassifier(max_depth=4, random_state=0)
tree.fit(X_train, y_train)
export_graphviz(tree,out_file="tree.dot",class_names=["malignat","benign"],feature_names=cancer.feature_names,impurity=False,filled=True)with open("tree.dot") as f:dot_graph = f.read()
graphviz.Source(dot_graph)# out:ModuleNotFoundError: No module named 'graphviz'尝试了很多种方法并没有解决问题‼️
http://t.csdn.cn/wAVEK ⬅️可用此方法再次验证
3 显示树的特征重要性
其中最常用的是特征重要性(Feature Importance),每个特征对树决策的重要性进行排序, 其中0表示“根本没用到”,1表示“完美预测目标值”,特征重要性的求和始终为1。
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as npcancer = datasets.load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state = 42)
tree = DecisionTreeClassifier(max_depth=4, random_state=0)
tree.fit(X_train, y_train)
print("Feature imprtance:\n{}".format(tree.feature_importances_))
Feature imprtance:
[0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0.01019737 0.048398250. 0. 0.0024156 0. 0. 0.0. 0. 0.72682851 0.0458159 0. 0.0.0141577 0. 0.018188 0.1221132 0.01188548 0. ]特征重要性可视化
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as npcancer = datasets.load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state = 42)
tree = DecisionTreeClassifier(max_depth=4, random_state=0)
tree.fit(X_train, y_train)
print("Feature imprtance:\n{}".format(tree.feature_importances_))def plot_feature_importances_cancer(model):n_features = cancer.data.shape[1]plt.barh(range(n_features),model.feature_importances_,align='center')plt.yticks(np.arange(n_features),cancer.feature_names)plt.xlabel("Feature importance")plt.ylabel("Feature")plot_feature_importances_cancer(tree)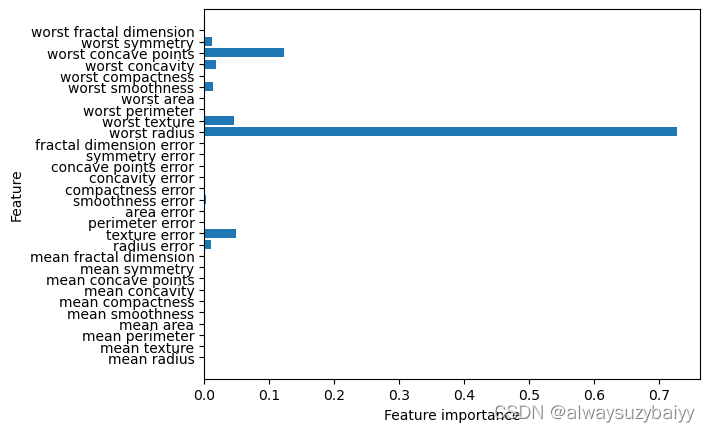
决策树回归
1 决策树回归
#决策树回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()X = boston.data
y = boston.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, random_state=666)# DecisionTreeRegressor决策树的回归器
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor( max_depth= 11 )
dt_reg.fit(X_train, y_train)
print(dt_reg.score(X_test,y_test))
print(dt_reg.score(X_train,y_train))
# 0.6005800948958887
# 1.0# 此时决策树在训练数据集上预测准确率是百分百的,但是在测试数据集上只有60%的准确率
# 很显然出现了过拟合,可通过设置树深来改善过拟合
# 0.6908496704356424
# 0.9918292293652428此时决策树在训练数据集上预测准确率是百分百的,但是在测试数据集上只有60%的准确率,很显然出现了过拟合,可通过设置树深来改善过拟合。
相关文章:
第二个机器学习应用:乳腺癌数据集在决策树模型上的挖掘
目录 决策树优化与可视化 1 决策树分类 2 决策树可视化 3 显示树的特征重要性 特征重要性可视化 决策树回归 1 决策树回归 决策树优化与可视化 1 决策树分类 from sklearn.datasets import load_breast_cancer from sklearn.tree import DecisionTreeClassifier from sk…...
前端canvas截图酷游地址的方法!
前情提要 想在在JavaScript中,酷游专员KW9㍠ㄇEㄒ提供用HTML5的Canvas元素来剪取画面并存成SVG或PNG。 程式写法(一) 首先,需要在HTML中创建一个Canvas元素<canvas id"myCanvas"></canvas> 在JavaScript中,使用canv…...

2018年入学,2021年入职
2018年的春天,凌晨紧张地查着考研成绩,运气好,384,远远超出了我的预期“能进复试就行”,秉承着“尽人事,知天命”的格言,坚持复习完,坚持到考试最后一秒。 在考试之前,我…...
python+nodejs+ssm+vue 基于协同过滤的旅游推荐系统
本文首先介绍了旅游推荐的发展背景与发展现状,然后遵循软件常规开发流程,首先针对系统选取适用的语言和开发平台,根据需求分析制定模块并设计数据库结构,再根据系统总体功能模块的设计绘制系统的功能模块图,流程图以及…...
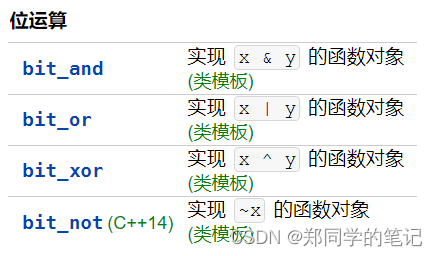
【STL十四】函数对象(function object)_仿函数(functor)——lambda表达式
【STL十四】函数对象(function object)_仿函数(functor)——lambda表达式 一、函数对象(function object)二、函数对象优点三、分类四、头文件五、用户定义函数对象demo六、std::内建函数对象1、 算术运算函…...

如何写出高质量的前端代码
写出高质量的前端代码是每个前端开发人员的追求。在一个复杂的项目中,代码质量对于项目的可维护性、可扩展性和可读性都有很大的影响。本文将介绍一些如何写出高质量前端代码的技巧和最佳实践。 一、注重代码结构和组织 1.1 遵循一致的命名规范 命名规范是编写高…...

YOLOv7如何提高目标检测的速度和精度,基于优化算法提高目标检测速度
目录 一、学习率调度二、权重衰减和正则化三、梯度累积和分布式训练1、梯度累积2、分布式训练 四、自适应梯度裁剪 大家好,我是哪吒。 上一篇介绍了YOLOv7如何提高目标检测的速度和精度,基于模型结构提高目标检测速度,本篇介绍一下基于优化算…...

CentOS 7中安装配置Nginx的教程指南
1. 安装Nginx 在终端中执行以下命令以安装Nginx: sudo yum install epel-release sudo yum install nginx安装完成后的 Nginx 内容通常会被安装在以下目录下: /etc/nginx: 该目录包含 Nginx 的配置文件,包括 nginx.conf 和 conf.d 目录下的…...

Vicuna- 一个类 ChatGPT开源 模型
Meta 开源 LLaMA(大羊驼)系列模型为起点,研究人员逐渐研发出基于LLaMA的Alpaca(羊驼)、Alpaca-Lora、Luotuo(骆驼)等轻量级类 ChatGPT 模型并开源。 google提出了一个新的模型:Vicuna(小羊驼)。该模型基于LLaMA,参数量13B。Vicuna-13B 通过微调 LLaMA 实现了高性能…...

5.1 数值微分
学习目标: 作为数值分析的基础内容,我建议你可以采取以下步骤来学习数值微分: 掌握微积分基础:数值微分是微积分中的一个分支,需要先掌握微积分基础知识,包括导数、极限、微分等。 学习数值微分的概念和方…...
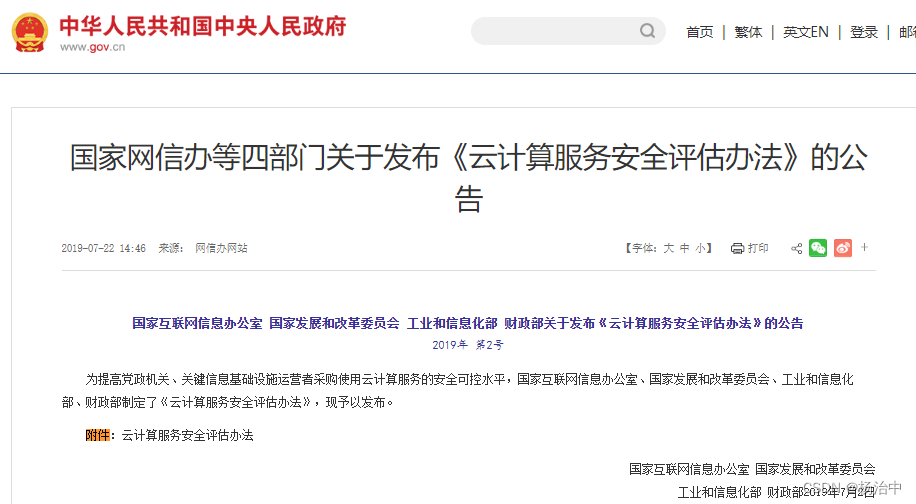
云计算服务安全评估办法
云计算服务安全评估办法 2019-07-22 14:46 来源: 网信办网站【字体:大 中 小】打印 国家互联网信息办公室 国家发展和改革委员会 工业和信息化部 财政部关于发布《云计算服务安全评估办法》的公告 2019年 第2号 为提高党政机关、关键信息基础设施运营者…...
laravel5.6.* + vue2 创建后台
本地已经安装好了composer 1.新建 Laravel5.6.*项目 composer create-project --prefer-dist laravel/laravel laravel5vue2demo 5.6.* 2. cd laravel5vue2demo 3. npm install /routes/web.php 路由文件中, 修改 Route::get(/, function () {return view(index); });新建…...
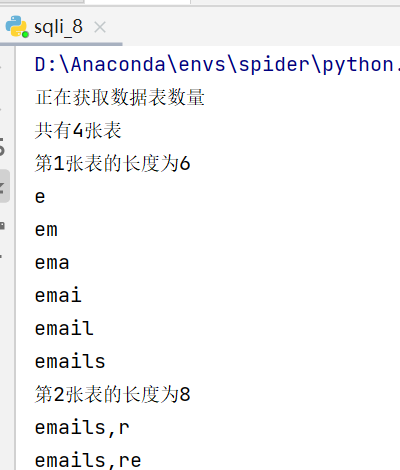
Python自动化sql注入:布尔盲注
在sql注入时,使用python脚本可以大大提高注入效率,这里演示一下编写python脚本实现布尔盲注的基本流程: 演示靶场:sqli-labs 布尔盲注 特点:没有回显没有报错,但根据sql语句正常与否返回不同结果&#x…...

Microsoft Defender for Office 365部署方案
目录 前言 一、Microsoft Defender for Office 365 部署架构 1、部署环境 2、Microsoft Defender for Office 365 核心服务...

字节岗位薪酬体系曝光,看完感叹:不服真不行
曾经的互联网是PC的时代,随着智能手机的普及,移动互联网开始飞速崛起。而字节跳动抓住了这波机遇,2015年,字节跳动全面加码短视频,从那以后,抖音成为了字节跳动用户、收入和估值的最大增长引擎。 自从字节…...

华为OD机试-高性能AI处理器-2022Q4 A卷-Py/Java/JS
某公司研发了一款高性能AI处理器。每台物理设备具备8颗AI处理器,编号分别为0、1、2、3、4、5、6、7。 编号0-3的处理器处于同一个链路中,编号4-7的处理器处于另外一个链路中,不同链路中的处理器不能通信。 现给定服务器可用的处理器编号数组…...
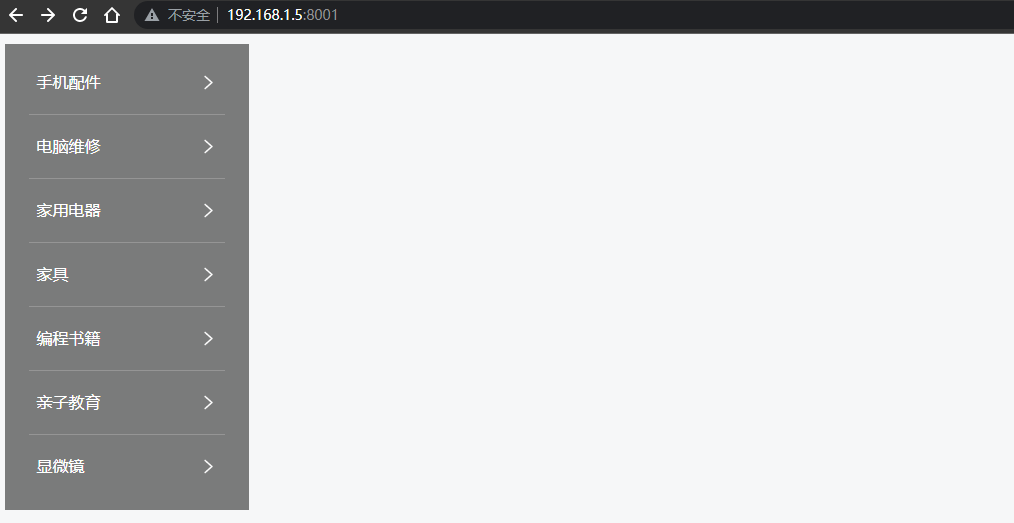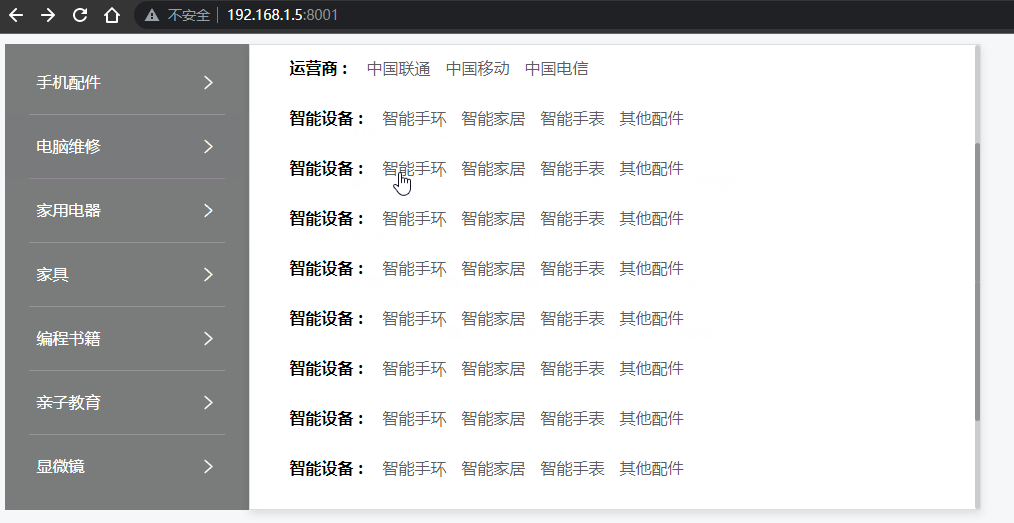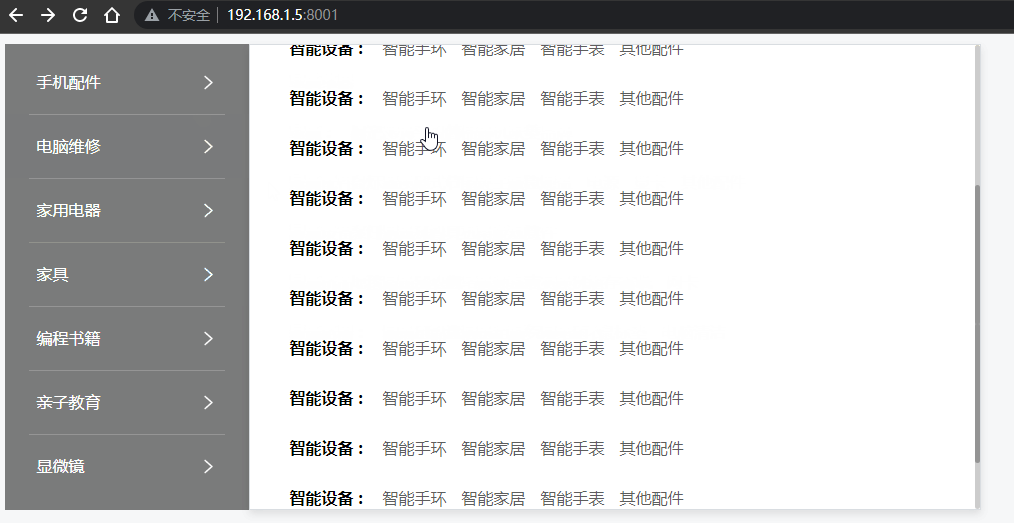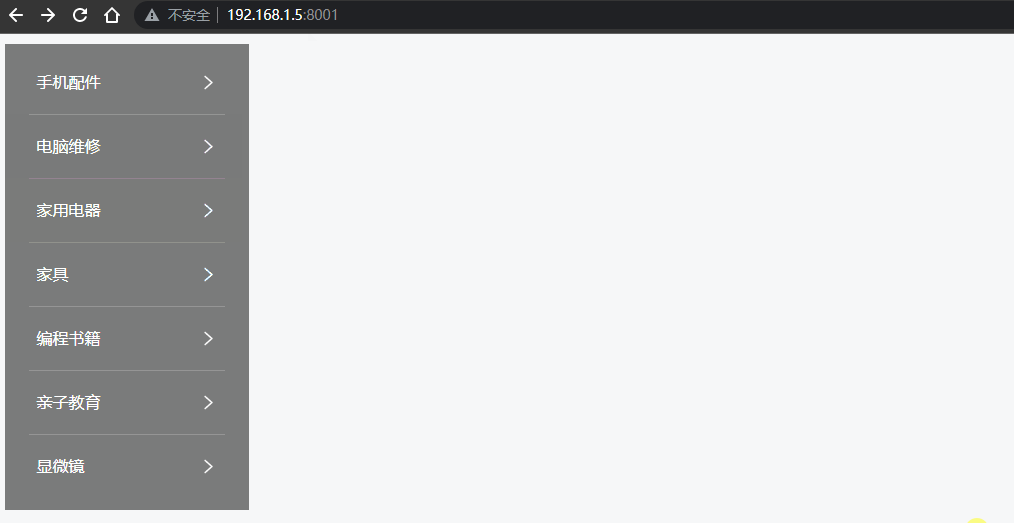
Vue - 实现垂直菜单分类栏目,鼠标移入后右侧出现悬浮二级菜单容器效果(完整示例源码,详细代码注释,一键复制开箱即用)
前言 网上的教程都太乱了,各种杂乱无注释代码、图片资源丢失、一堆样式代码,根本无法改造后应用到自己的项目中。 本文实现了 在 Vue / Nuxt 项目中,垂直分类菜单项,当用户鼠标移入菜单后,右侧自动出现二级分类悬浮容器盒子效果, 您可以直接复制源码,然后按照您的需求再…...
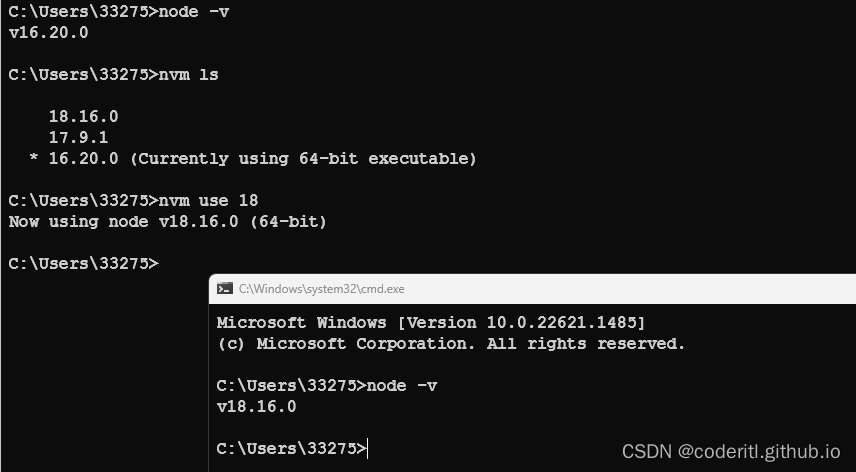
NVM-无缝切换Node版本
NVM-无缝切换Node版本 如果未使用nvm之前已经下载了node,并且配置了环境变量,那么此时删除这些配置(Node的环境以及Node软件),使用nvm是为了在某些项目中使用低版本的node NVM下载 进入github的nvm readme: https://github.com/coreybutler/nvm-windows…...

CCF-CSP真题《202303-1 田地丈量》思路+python,c++满分题解
想查看其他题的真题及题解的同学可以前往查看:CCF-CSP真题附题解大全 试题编号:202303-1试题名称:田地丈量时间限制:1.0s内存限制:512.0MB问题描述: 问题描述 西西艾弗岛上散落着 n 块田地。每块田地可视为…...

Autosar-软件架构
文章目录 一、Autosar软件架构分层图二、应用层三、RTE层四、BSW层1、微控制器抽象层2、ECU抽象层I/O硬件抽象COM硬件抽象Memory硬件抽象Onboard Device Abstraction3、复杂驱动层4、服务层系统服务通信服务CAN一、Autosar软件架构分层图 架构分层是实现软硬件分离的关键,它也…...

ChanlunX:为通达信注入缠论智能分析引擎
ChanlunX:为通达信注入缠论智能分析引擎 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 在技术分析领域,缠论以其严谨的逻辑体系和独特的市场结构认知而备受推崇。然而,…...

动物森友会存档编辑神器:NHSE新手完全入门指南
动物森友会存档编辑神器:NHSE新手完全入门指南 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 你是否曾经梦想过在《集合啦!动物森友会》中拥有无限铃钱、稀有家具…...

龙芯LS2K PMON启动全景:从mainbus到U盘识别
【龙芯LS2K PMON终极干货】整机设备启动全景图:从 mainbus 开机到 U 盘识别全流程 大家好,本篇是PMON/BSD内核设备模型大结局。 我将把你所有文件: mainbus、localbus、pci、pcibr、pcilotg、lotg、dwc2、usb、ioconf.c、cfdata 全部串成一张从开机上电到U盘识别的终极全景…...

知识图谱与推荐系统实战
一、传统推荐系统的“天花板”协同过滤的困境你刷电商、看视频时,推荐系统总在猜你喜欢什么。最经典的协同过滤思路是“物以类聚、人以群分”:你买过A,那么买过A的人也常买B,于是把B推给你。这套方法简单有效,但也有硬…...

零基础掌握罗技鼠标宏:让你的PUBG压枪更稳定
零基础掌握罗技鼠标宏:让你的PUBG压枪更稳定 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的武器后坐…...
)
2026年精选AI写作辅助网站合集(实测甄选版)
为解决学术写作中效率与合规两大核心痛点,以下精选8款高适配性 AI 论文写作工具(按综合优先级排序),围绕中文学术规范适配、真实参考文献生成、格式标准化、高性价比四大核心维度筛选,同时配套分场景精准选型方案与学术…...
glTF-Transform:现代3D应用中的glTF模型优化与处理实战指南
glTF-Transform:现代3D应用中的glTF模型优化与处理实战指南 【免费下载链接】glTF-Transform glTF 2.0 SDK for JavaScript and TypeScript, on Web and Node.js. 项目地址: https://gitcode.com/gh_mirrors/gl/glTF-Transform 在当今的3D应用开发中…...

厦门大学:语音大模型——从语音识别到全双工语音交互 2026
这份文档由厦门大学洪青阳于 2026 年 5 月撰写,围绕语音大模型从语音识别到全双工语音交互展开,从背景、技术、模型、交互到应用系统梳理行业进展,核心总结如下:一、背景:语种、方言与交互范式演进语言基础:…...

HarmonyOS 6 Chip 组件:设置默认后缀图标使用文档
文章目录代码默认后缀图标核心配置1. 启用默认关闭图标2. 显示优先级规则3. 关联配置项代码解析1. 启用默认后缀图标2. 不冲突条件3. 整体结构总结默认后缀图标即 Chip 内置关闭图标,由系统提供样式、尺寸、交互逻辑,无需配置图片资源,只需开…...

Spring Boot Actuator生产级监控与管理工具包
Spring Boot Actuator 是 Spring Boot 提供的生产级监控与管理工具包,帮你把应用“可观测化”。它提供了一系列内置的端点(Endpoint),用来查看应用的内部状态,比如健康情况、配置信息、内存指标等。你可以把它理解成为…...