Neural Network学习笔记4
完整的模型训练套路
train.py
import torch
import torchvision
from torch.utils.data import DataLoader
# 引入自定义的网络模型
from torch.utils.tensorboard import SummaryWriterfrom model import *# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="dataset_transform", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset_transform", train=False, transform=torchvision.transforms.ToTensor(),download=True)
# length 长度 获取数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 搭建神经网络:
# 一般情况下我们会把网络放到单独的python文件里,通常命名为model.py,然后再本文件头部引入就可以了
# class Zrf(nn.Module):
# def __init__(self):
# super(Zrf, self).__init__()
# # Sequential 序列
# self.model = Sequential(
# # padding=2 是根据输入输出的H,W计算出来的
# Conv2d(3, 32, 5, 1, padding=2), 输入通道,输出通道,卷积核尺寸,步长,padding要用公式算
# MaxPool2d(2),
# Conv2d(32, 32, 5, 1, padding=2),
# MaxPool2d(2),
# Conv2d(32, 64, 5, 1, padding=2),
# MaxPool2d(2),
# Flatten(),
# Linear(1024, 64),
# Linear(64, 10)
# )
#
# def forward(self, x):
# x = self.model(x)
# return x# 创建网络模型
zrf = Zrf()# 损失函数
loss_fn = nn.CrossEntropyLoss()# 优化器
# learning_rate = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(zrf.parameters(), lr=learning_rate)# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10# 添加tensorboard
writer = SummaryWriter("../log_train")for i in range(epoch):print("--------第 {} 轮训练开始--------".format(i+1))# 训练步骤开始zrf.train() # 设置训练模式(本模型中这一行可以不写)for data in train_dataloader:imgs, targets = dataoutputs = zrf(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad() # 在进行反向传播来计算梯度时,要先将梯度置为0,防止之前计算出来的梯度的影响loss.backward() # 计算梯度optimizer.step() # 根据梯度对卷积核参数进行调优total_train_step = total_train_step + 1if total_train_step % 100 == 0:print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 为了看模型有没有训练好,所以在训练完一轮之后,在测试数据集上进行测试# 以测试数据集上的损失来判断# 以下部分没有梯度,测试时不需要调优# 测试步骤开始zrf.eval() # 设置评估模式(本模型中这一行可以不写)total_test_loss = 0# 计算整体正确率total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, targets = dataoutputs = zrf(imgs)loss = loss_fn(outputs, targets)# 计算整体正确率accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracytotal_test_loss = total_test_loss + loss.item()print("整体测试集上的Loss:{}",format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))total_test_step = total_test_step + 1writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)torch.save(zrf, "zrf_{}.pth".format(i)) # torch.save(zrf.state_dict(), "zrf_{}.pth".format(i))print("模型已保存")
writer.close()ssssssssaaaassxcscwqmodel.py
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential# 搭建神经网络class Zrf(nn.Module):def __init__(self):super(Zrf, self).__init__()# Sequential 序列self.model = Sequential(# padding=2 是根据输入输出的H,W计算出来的Conv2d(3, 32, 5, 1, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, 1, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, 1, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model(x)return xif __name__ == '__main__':# 一般在这里测试网络的正确性zrf = Zrf()input = torch.ones((64, 3, 32, 32)) # 64batch_size,3通道,32x32output = zrf(input)print(output.shape)关于正确率计算的一点说明
import torchoutputs = torch.tensor([[0.1, 0.2],[0.3, 0.4]])
print(outputs.argmax(1)) # 1或0代表着方向,1是横向看
# tensor([1, 1]) 最大值是0.3 0.4
print(outputs.argmax(0)) # 0是纵向看
# tensor([1, 1]) 最大值是0.2 0.4
# outputs = torch.tensor([[0.1, 0.2],
# [0.05, 0.4]])
# print(outputs.argmax(0))
# # tensor([0, 1]) 最大值是0.1 0.4
preds = outputs.argmax(1)
targets = torch.tensor([0, 1])
print((preds == targets).sum())利用GPU进行训练train_gpu
train_gpu.py
第一种GPU训练方法
# 对模型,数据(输入、标注),损失函数的后面,加 .cuda()import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="dataset_transform", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset_transform", train=False, transform=torchvision.transforms.ToTensor(),download=True)
# length 长度 获取数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)class Zrf(nn.Module):def __init__(self):super(Zrf, self).__init__()# Sequential 序列self.model = Sequential(Conv2d(3, 32, 5, 1, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, 1, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, 1, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model(x)return x# 创建网络模型
zrf = Zrf()
# -------------------利用GPU训练-------------------#
if torch.cuda.is_available():zrf = zrf.cuda()# 损失函数
loss_fn = nn.CrossEntropyLoss()
# -------------------利用GPU训练-------------------#
if torch.cuda.is_available():loss_fn = loss_fn.cuda()# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(zrf.parameters(), lr=learning_rate)# 设置训练网络的一些参数
total_train_step = 0
total_test_step = 0
epoch = 10# 添加tensorboard
writer = SummaryWriter("../log_train")start_time = time.time()for i in range(epoch):print("--------第 {} 轮训练开始--------".format(i+1))# 训练步骤开始zrf.train()for data in train_dataloader:imgs, targets = data# -------------------利用GPU训练-------------------#if torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = zrf(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time()print(end_time - start_time)print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始zrf.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, targets = data# -------------------利用GPU训练-------------------#if torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = zrf(imgs)loss = loss_fn(outputs, targets)accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracytotal_test_loss = total_test_loss + loss.item()print("整体测试集上的Loss:{}",format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))total_test_step = total_test_step + 1writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)torch.save(zrf, "zrf_{}.pth".format(i))print("模型已保存")
writer.close()第二种GPU训练方法
# .to(device)
# device = torch.device("cpu")
# torch.device("cuda")
# torch.device("cuda:0")
# torch.device("cuda:1")import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time# 定义训练的设备
# device = torch.device("cpu")
# device = torch.device("cuda")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="dataset_transform", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset_transform", train=False, transform=torchvision.transforms.ToTensor(),download=True)
# length 长度 获取数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)class Zrf(nn.Module):def __init__(self):super(Zrf, self).__init__()# Sequential 序列self.model = Sequential(Conv2d(3, 32, 5, 1, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, 1, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, 1, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model(x)return x# 创建网络模型
zrf = Zrf()
# -------------------利用GPU训练-------------------#
zrf.to(device) # 可以不重新赋值
# zrf = zrf.to(device)# 损失函数
loss_fn = nn.CrossEntropyLoss()
# -------------------利用GPU训练-------------------#
loss_fn.to(device) # 可以不重新赋值
# loss_fn = loss_fn.to(device)# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(zrf.parameters(), lr=learning_rate)# 设置训练网络的一些参数
total_train_step = 0
total_test_step = 0
epoch = 10# 添加tensorboard
writer = SummaryWriter("../log_train")start_time = time.time()for i in range(epoch):print("--------第 {} 轮训练开始--------".format(i+1))# 训练步骤开始zrf.train()for data in train_dataloader:imgs, targets = data# -------------------利用GPU训练-------------------## 必须重新赋值imgs = imgs.to(device)targets = targets.to(device)outputs = zrf(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time()print(end_time - start_time)print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始zrf.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, targets = data# -------------------利用GPU训练-------------------#imgs = imgs.to(device)targets = targets.to(device)outputs = zrf(imgs)loss = loss_fn(outputs, targets)accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracytotal_test_loss = total_test_loss + loss.item()print("整体测试集上的Loss:{}",format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))total_test_step = total_test_step + 1writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)torch.save(zrf, "zrf_{}.pth".format(i))print("模型已保存")
writer.close()利用GPU训练前一百次的时间: 4.680064678192139
没有GPU: 6.723153114318848
完整的模型验证套路
(测试、demo)利用已经训练好的模型,然后给他提供输入
相关文章:
Neural Network学习笔记4
完整的模型训练套路 train.py import torch import torchvision from torch.utils.data import DataLoader # 引入自定义的网络模型 from torch.utils.tensorboard import SummaryWriterfrom model import *# 准备数据集 train_data torchvision.datasets.CIFAR10(root"…...

[转]关于cmake --build .的理解
https://blog.csdn.net/qq_38563206/article/details/126486183 https://blog.csdn.net/HandsomeHong/article/details/120170219 cmake --build . 该命令的含义是:执行当前目录下的构建系统,生成构建目标。 cmake项目构建过程简述: 1. 首先…...
【Linux下6818开发板(ARM)】硬件空间挂载
(꒪ꇴ꒪ ),hello我是祐言博客主页:C语言基础,Linux基础,软件配置领域博主🌍快上🚘,一起学习!送给读者的一句鸡汤🤔:集中起来的意志可以击穿顽石!作者水平很有限,如果发现错误&#x…...

剑指offer 动态规划篇
题目由入门往上递增 入门 斐波那契数列_牛客题霸_牛客网 (nowcoder.com) 动态规划甚至于算法的入门题目 方法一:按照斐波那契的公式fnfn-1fn-2,从1-n求出结果。 class Solution { public:int Fibonacci(int n) {vector<int>f{0,1,1};for(int …...
自动化部署的一些笔记)
关于Linux中前端负载均衡之VIP(LVS+Keepalived)自动化部署的一些笔记
写在前面 整理一些 LVS 相关的笔记理解不足小伙伴帮忙指正 傍晚时分,你坐在屋檐下,看着天慢慢地黑下去,心里寂寞而凄凉,感到自己的生命被剥夺了。当时我是个年轻人,但我害怕这样生活下去,衰老下去。在我看来…...

C++ 拷贝交换技术示例
拷贝交换技术(copy and swap)是什么,网上估计能查到很多。但网上有点难找到完整的演示代码,所以这里记录一下。难点在于: 如果要满足 5 的原则,我到底要写那些函数? 默认构造函数、复制构造函数…...
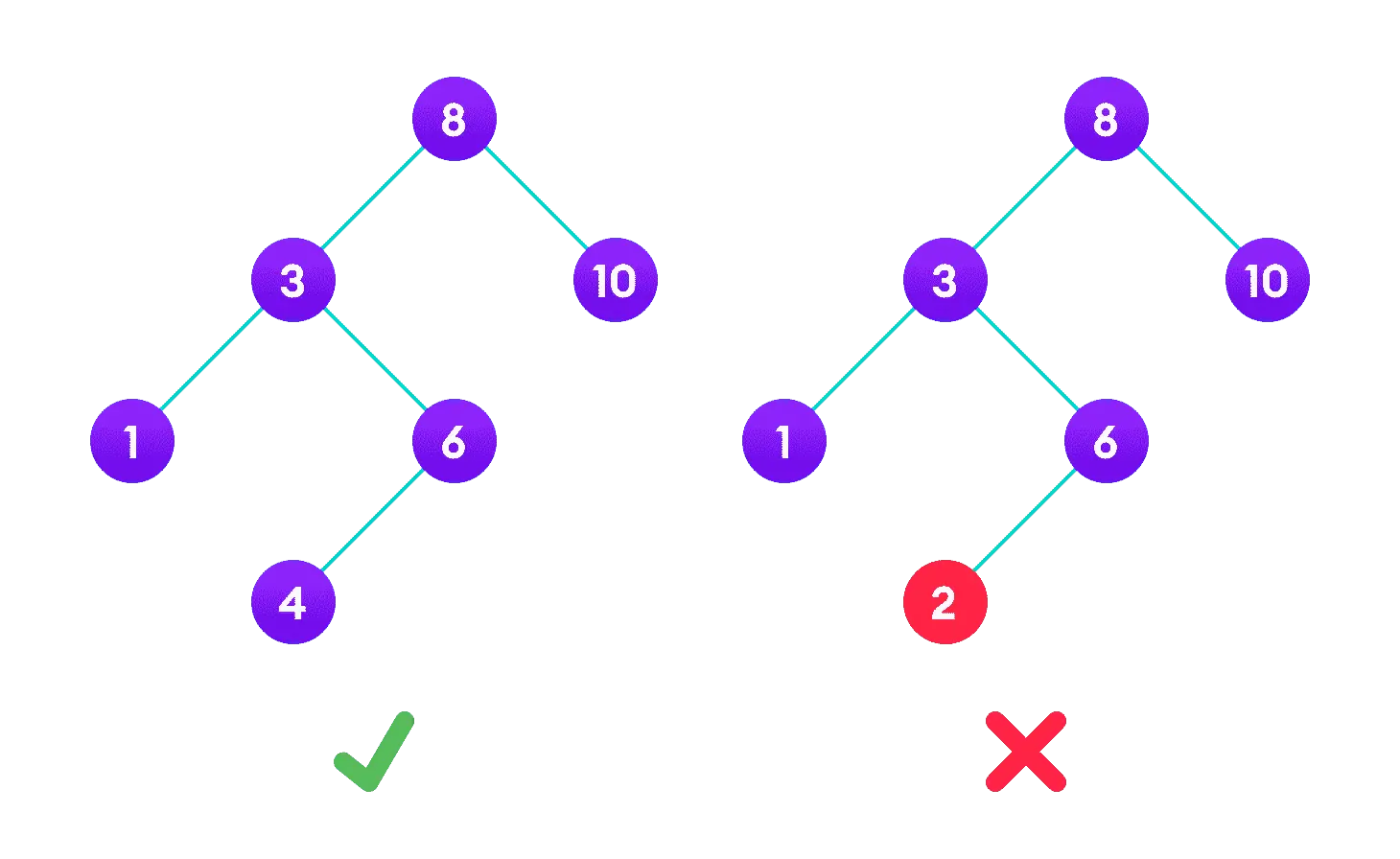
使用 Go 语言实现二叉搜索树
原文链接: 使用 Go 语言实现二叉搜索树 二叉树是一种常见并且非常重要的数据结构,在很多项目中都能看到二叉树的身影。 它有很多变种,比如红黑树,常被用作 std::map 和 std::set 的底层实现;B 树和 B 树,…...

系统接口自动化测试方案
XXX接口自动化测试方案 1、引言 1.1 文档版本 版本 作者 审批 备注 V1.0 XXXX 创建测试方案文档 1.2 项目情况 项目名称 XXX 项目版本 V1.0 项目经理 XX 测试人员 XXXXX,XXX 所属部门 XX 备注 1.3 文档目的 本文档主要用于指导XXX-Y…...
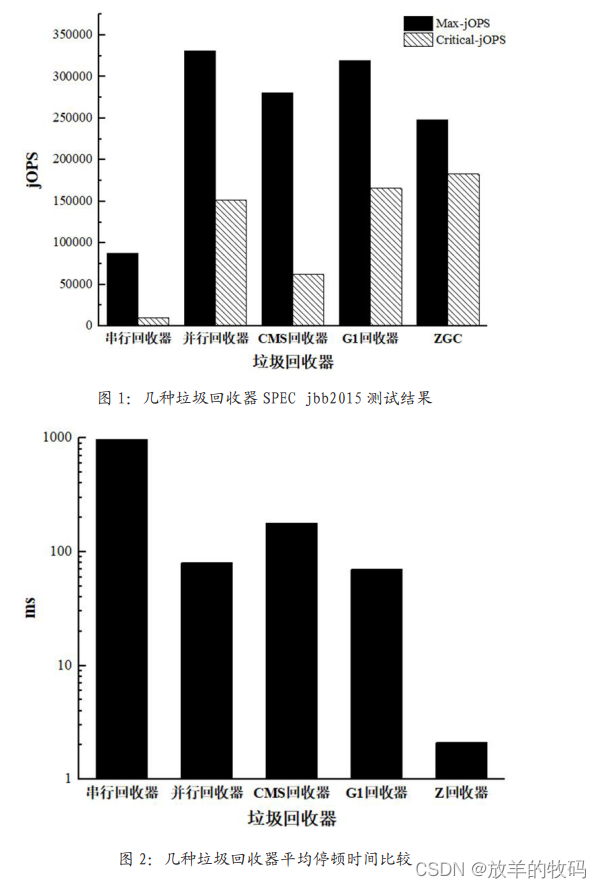
小研究 - JVM 垃圾回收方式性能研究(一)
本文从几种JVM垃圾回收方式及原理出发,研究了在 SPEC jbb2015基准测试中不同垃圾回收方式对于JVM 性能的影响,并通过最终测试数据对比,给出了不同应用场景下如何选择垃圾回收策略的方法。 目录 1 引言 2 垃圾回收算法 2.1 标记清除法 2.2…...
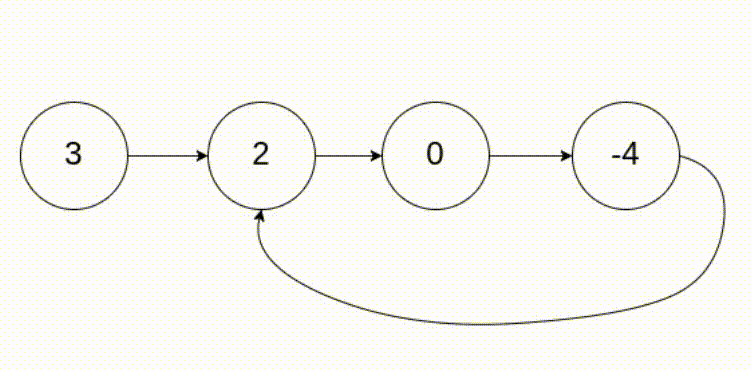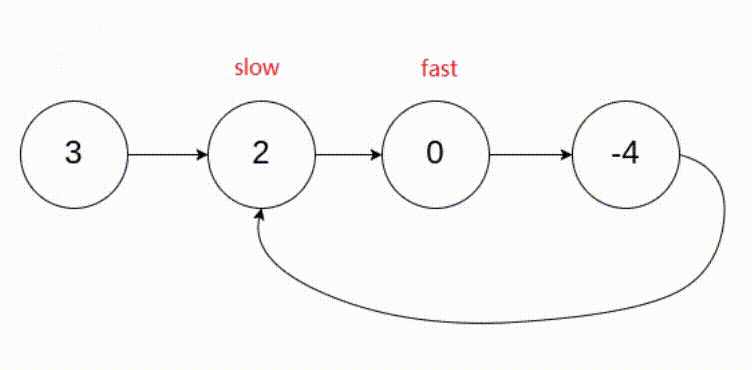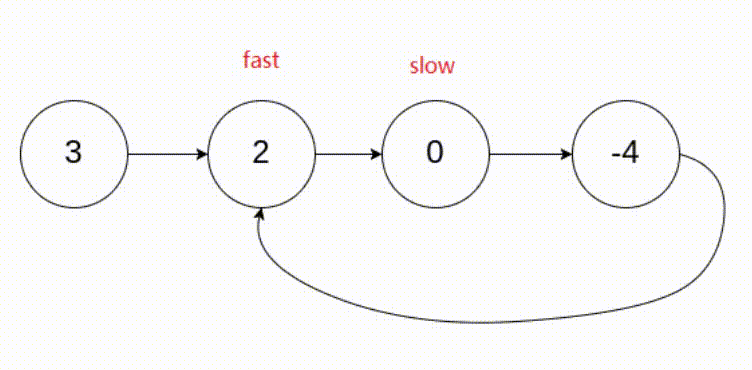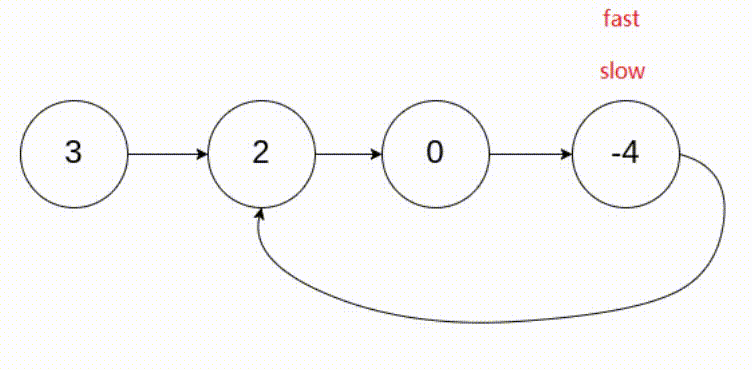
[LeetCode]链表相关题目(c语言实现)
文章目录 LeetCode203. 移除链表元素LeetCode237. 删除链表中的节点LeetCode206. 反转链表ⅠLeetCode92. 反转链表 II思路 1思路 2 LeetCode876. 链表的中间结点剑指 Offer 22. 链表中倒数第k个节点LeetCode21. 合并两个有序链表LeetCode86. 分隔链表LeetCode234. 回文链表Leet…...
] NAND 初始化常用命令:复位 (Reset) 和 Read ID 和 Read UID 操作和代码实现)
[深入理解NAND Flash (操作篇)] NAND 初始化常用命令:复位 (Reset) 和 Read ID 和 Read UID 操作和代码实现
依JEDEC eMMC及经验辛苦整理,原创保护,禁止转载。 专栏 《深入理解Flash:闪存特性与实践》 内容摘要 全文 4400 字,主要内容 复位的目的和作用? NAND Reset 种类:FFh, FCh, FAh, FDh 区别 Reset 操作步骤 和 代码实现 Read ID 操作步骤 和 代码实现 Read Uni…...

RxJava 复刻简版之二,调用流程分析之案例实现
接上篇:https://blog.csdn.net/da_ma_dai/article/details/131878516 代码节点:https://gitee.com/bobidali/lite-rx-java/commit/05199792ce75a80147c822336b46837f09229e46 java 类型转换 kt 类型: Any Object泛型: 协变: …...

SpringMVC中Model和ModelAndView的区别
SpringMVC中Model和ModelAndView的区别 两者的区别: 在SpringMVC中,Model和ModelAndView都是用于将数据传递到视图层的对象 Model是”模型“的意思,是MVC架构中的”M“部分,是用来传输数据的。 理解成MVC架构中的”M“和”V“…...
Tomcat安装与管理
文章目录 Tomcat安装及管理Tomcat gz包安装:JDK安装:Tomcat安装:修改配置文件(如下):服务启动配置: Tomcat-管理(部署jpress):修改允许访问的主机修改允许管理APP的主机进入管理&…...

React之路由
React之路由 背景: react: 18.2.0 路由:react-router-dom: 6.14.2 1、路由表配置 src下新建router/index.ts import React, { lazy } from react import { Navigate } from react-router-dom import Layout from /layout/Index import { JSX } from rea…...
机器学习深度学习——非NVIDIA显卡怎么做深度学习(坑点排查)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——数值稳定性和模型化参数(详细数学推导) 📚订阅专栏:机器…...

2021 Robocom 决赛 第四题
原题链接: PTA | 程序设计类实验辅助教学平台 题面: 在一个名叫刀塔的国家里,有一只猛犸正在到处跑着,希望能够用它的长角抛物技能来撞飞别人。已知刀塔国有 N 座城市,城市之间由 M 条道路互相连接,为了拦…...
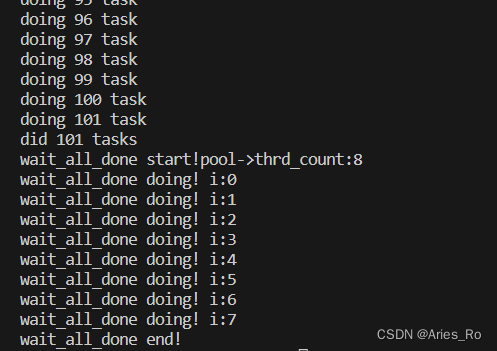
线程池-手写线程池Linux C简单版本(生产者-消费者模型)
目录 简介手写线程池线程池结构体分析task_ttask_queue_tthread_pool_t 线程池函数分析thread_pool_createthread_pool_postthread_workerthread_pool_destroywait_all_donethread_pool_free 主函数调用 运行结果 简介 本线程池采用C语言实现 线程池的场景: 当某些…...

05-向量的意义_n维欧式空间
线性代数 什么是向量?究竟为什么引入向量? 为什么线性代数这么重要?从研究一个数拓展到研究一组数 一组数的基本表示方法——向量(Vector) 向量是线性代数研究的基本元素 e.g. 一个数: 666,…...

交通运输安全大数据分析解决方案
当前运输市场竞争激烈,道路运输企业受传统经营观念影响,企业管理者安全意识淡薄,从业人员规范化、流程化的管理水平较低,导致制度规范在落实过程中未能有效监督与管理,执行过程中出现较严重的偏差,其营运车…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

解决Claude Code Token不足问题并享受Taotoken活动价
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code Token不足问题并享受Taotoken活动价 应用场景类,聚焦于使用Claude Code时遇到Token配额紧张的开发者&…...
)
CentOS服务器上VNC连接失败?手把手教你排查并修复个人端口问题(附重启命令)
CentOS服务器VNC连接故障深度排查指南:从原理到实战当你在深夜赶项目时,突然发现VNC连接不上服务器,那种焦虑感我深有体会。去年参与半导体器件仿真项目时,我也曾被这个问题困扰整整两天。本文将分享一套经过实战检验的排查方法论…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

企业内统一API网关与Taotoken聚合平台对接方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一API网关与Taotoken聚合平台对接方案 在推进AI应用落地的过程中,许多中大型企业面临一个共同挑战:…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...