用LangChain开源框架实现知识机器人

前言
Large Language Models (LLMs)在2020年OpenAI 的 GPT-3 的发布而进入世界舞台 。从那时起,他们稳步增长进入公众视野。
众所周知 OpenAI 的 API 无法联网,所以大家如果想通过它的API实现联网搜索并给出回答、总结 PDF 文档、基于某个 Youtube 视频进行问答等等的功能肯定是无法实现的。所以,我们来介绍一个非常强大的第三方开源库:LangChain 。
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。他主要拥有 2 个能力:可以将 LLM 模型与外部数据源进行连接&允许与 LLM 模型进行交互。
项目地址:https://github.com/langchain-ai/langchain
LangChain 是一个开发由语言模型驱动的应用程序的框架。
框架是设计原则:
数据感知 : 将语言模型连接到其他数据源
具有代理性质 : 允许语言模型与其环境交互
Langchain的核心思想
将不同的组件“链接”在一起,以围绕LLM创建更高级的用例。
LangChain 核心模块支持
模型(models) : LangChain 支持的各种模型类型和模型集成。
提示(prompts) : 包括提示管理、提示优化和提示序列化。
内存(memory) : 内存是在链/代理调用之间保持状态的概念。LangChain 提供了一个标准的内存接口、一组内存实现及使用内存的链/代理示例。
索引(indexes) : 与您自己的文本数据结合使用时,语言模型往往更加强大——此模块涵盖了执行此操作的最佳实践。
链(chains) : 链不仅仅是单个 LLM 调用,还包括一系列调用(无论是调用 LLM 还是不同的实用工具)。LangChain 提供了一种标准的链接口、许多与其他工具的集成。LangChain 提供了用于常见应用程序的端到端的链调用。
代理(agents) : 代理涉及 LLM 做出行动决策、执行该行动、查看一个观察结果,并重复该过程直到完成。LangChain 提供了一个标准的代理接口,一系列可供选择的代理,以及端到端代理的示例。
###LangChain工作原理
LangChain就是把大量的数据组合起来,让LLM能够尽可能少地消耗计算力就能轻松地引用。它的工作原理是把一个大的数据源,比如一个50页的PDF文件,分成一块一块的,然后把它们嵌入到一个向量存储(Vector Store)里。
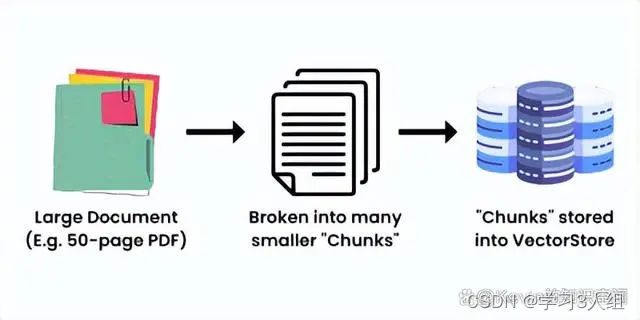
创建向量存储的简单示意图
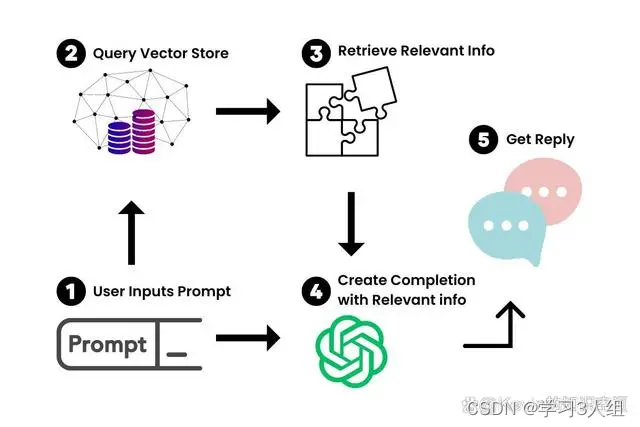
现在我们有了大文档的向量化表示,我们就可以用它和LLM一起工作,只检索我们需要引用的信息,来创建一个提示-完成(prompt-completion)对。
当我们把一个提示输入到我们新的聊天机器人里,LangChain就会在向量存储里查询相关的信息。你可以把它想象成一个专门为你的文档服务的小型谷歌。一旦找到了相关的信息,我们就用它和提示一起喂给LLM,生成我们的答案。
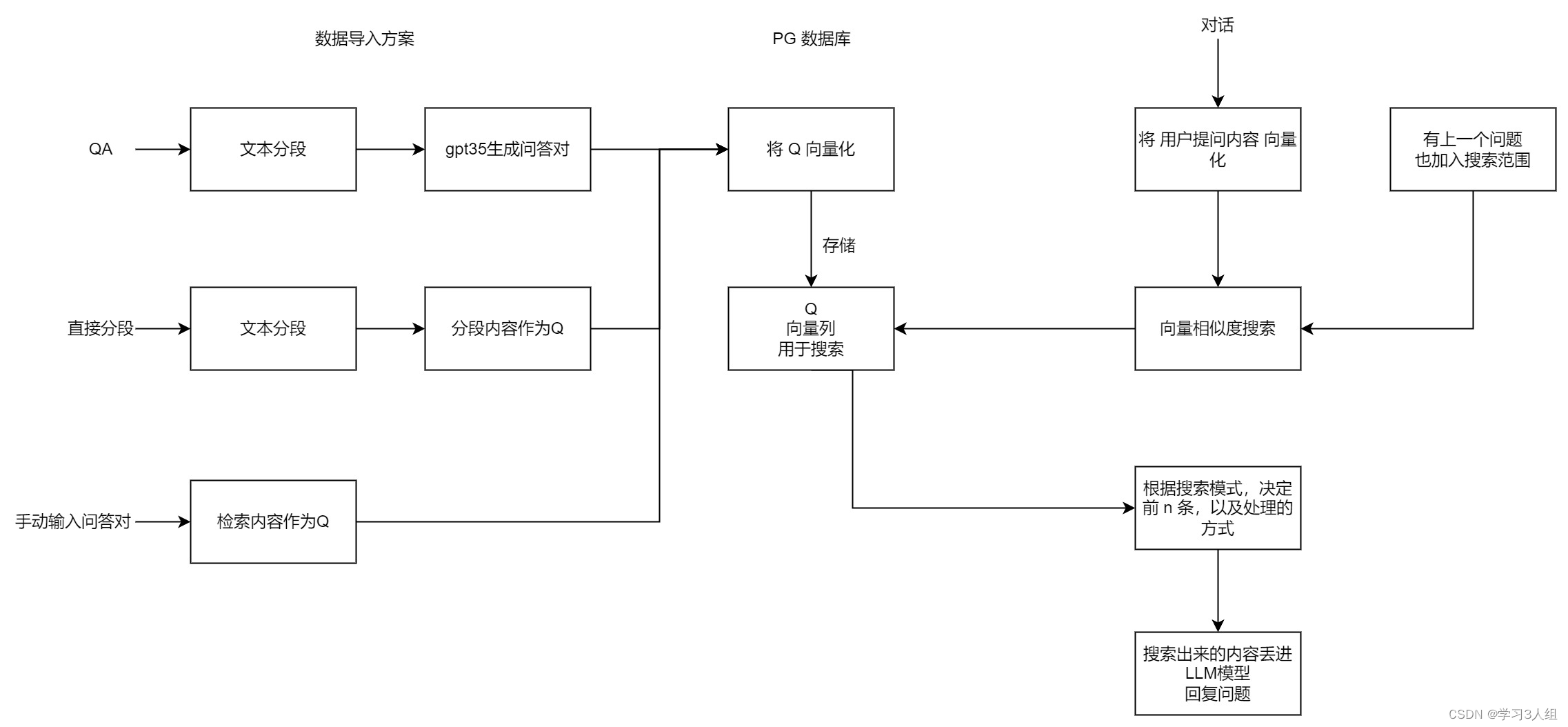
使用场景用例
自治代理(autonomous agents)
长时间运行的代理会采取多步操作以尝试完成目标。 AutoGPT 和 BabyAGI就是典型代表。
代理模拟(agent simulations)
将代理置于封闭环境中观察它们如何相互作用,如何对事件作出反应,是观察它们长期记忆能力的有趣方法。
个人助理(personal assistants)
主要的 LangChain 使用用例。个人助理需要采取行动、记住交互并具有您的有关数据的知识。
问答(question answering)
第二个重大的 LangChain 使用用例。仅利用这些文档中的信息来构建答案,回答特定文档中的问题。
聊天机器人(chatbots)
由于语言模型擅长生成文本,因此它们非常适合创建聊天机器人。
查询表格数据(tabular)
如果您想了解如何使用 LLM 查询存储在表格格式中的数据(csv、SQL、数据框等),请阅读此页面。
代码理解(code) : 如果您想了解如何使用 LLM 查询来自 GitHub 的源代码,请阅读此页面。
与 API 交互(apis)
使LLM 能够与 API 交互非常强大,以便为它们提供更实时的信息并允许它们采取行动。
提取(extraction)
从文本中提取结构化信息。
摘要(summarization)
将较长的文档汇总为更短、更简洁的信息块。一种数据增强生成的类型。
评估(evaluation)
生成模型是极难用传统度量方法评估的。 一种新的评估方式是使用语言模型本身进行评估。 LangChain 提供一些用于辅助评估的提示/链。
Langchian生态
实战举例
模型(LLM包装器)
提示
链
嵌入和向量存储
代理
我会给你分别来介绍每个部分,让你能够对LangChain的工作原理有一个高层次的理解。接下来,你应该能够运用这些概念,开始设计你自己的用例和创建你自己的应用程序。
接下来我会用Rabbitmetrics(Github)的一些简短的代码片段来进行介绍。他提供了有关此主题的精彩教程。这些代码片段应该能让你准备好使用LangChain。
首先,让我们设置我们的环境。你可以用pip安装3个你需要的库:
pip install -r requirements.txt
python-dotenv==1.0.0 langchain==0.0.137 pinecone-client==2.2.1
Pinecone是我们将要和LangChain一起使用的向量存储(Vector Store)。在这里,你要把你的OpenAI、Pinecone环境和Pinecone API的API密钥存储到你的环境配置文件里。你可以在它们各自的网站上找到这些信息。然后我们就用下面的代码来加载那个环境文件:
现在,我们准备好开始了!
# 加载环境变量
from dotenv import loaddotenv,finddotenv loaddotenv(finddotenv())
3.1、模型(LLM包装器)
为了和我们的LLM交互,我们要实例化一个OpenAI的GPT模型的包装器。在这里,我们要用OpenAI的GPT-3.5-turbo,因为它是最划算的。但是如果你有权限,你可以随意使用更强大的GPT4。
要导入这些,我们可以用下面的代码:
# 为了查询聊天模型GPT-3.5-turbo或GPT-4,导入聊天消息和ChatOpenAI的模式(schema)。
from langchain.schema import ( AIMessage, HumanMessage, SystemMessage)
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0.3)
messages = [ SystemMessage(content="你是一个专业的数据科学家"), HumanMessage(content="写一个Python脚本,用模拟数据训练一个神经网络")]
response=chat(messages)print(response.content,end='\n')
实际上,SystemMessage为GPT-3.5-turbo模块提供了每个提示-完成对的上下文信息。HumanMessage是指您在ChatGPT界面中输入的内容,也就是您的提示。
但是对于一个自定义知识的聊天机器人,我们通常会将提示中重复的部分抽象出来。例如,如果我要创建一个推特生成器应用程序,我不想一直输入“给我写一条关于…的推特”。
因此,让我们来看看如何使用提示模板(PromptTemplates)来将这些内容抽象出来。
3.2、提示
LangChain提供了PromptTemplates,允许你可以根据用户输入动态地更改提示,类似于正则表达式(regex)的用法。
# 导入提示并定义
PromptTemplatefrom langchain
import PromptTemplatetemplate = """您是一位专业的数据科学家,擅长构建深度学习模型。用几行话解释{concept}的概念"""
prompt = PromptTemplate( input_variables=["concept"], template=template,)
# 用PromptTemplate运行LLM
llm(prompt.format(concept="autoencoder"))
llm(prompt.format(concept="regularization"))
你可以用不同的方式来改变这些提示模板,让它们适合你的应用场景。如果你熟练使用ChatGPT,这应该对你来说很简单。
3.3、链
链可以让你在简单的提示模板上面构建功能。本质上,链就像复合函数,让你可以把你的提示模板和LLM结合起来。
使用之前的包装器和提示模板,我们可以用一个单一的链来运行相同的提示,它接受一个提示模板,并把它和一个LLM组合起来:
# 导入LLMChain并定义一个链,用语言模型和提示作为参数。
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# 只指定输入变量来运行链。
print(chain.run("autoencoder"))
除此之外,顾名思义,我们还可以把这些链连起来,创建更大的组合。
比如,我可以把一个链的结果传递给另一个链。在这个代码片段里,Rabbitmetrics把第一个链的完成结果传递给第二个链,让它用500字向一个五岁的孩子解释。
你可以把这些链组合成一个更大的链,然后运行它。
# 定义一个第二个提示
second_prompt = PromptTemplate( input_variables=["ml_concept"], template="把{ml_concept}的概念描述转换成用500字向我解释,就像我是一个五岁的孩子一样",)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# 用上面的两个链定义一个顺序链:第二个链把第一个链的输出作为输入
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# 只指定第一个链的输入变量来运行链。
explanation = overall_chain.run("autoencoder")print(explanation)
有了链,你可以创建很多功能,这就是LangChain功能强大的原因。但是它真正发挥作用的地方是和前面提到的向量存储一起使用。接下来我们开始介绍一下这个部分。
3.4、嵌入和向量存储
这里我们将结合LangChain进行自定义数据存储。如前所述,嵌入和向量存储的思想是把大数据分成小块,并存储起来。
LangChain有一个文本分割函数来做这个:
# 导入分割文本的工具,并把上面给出的解释分成文档块
from langchain.text_splitter import RecursiveCharacter
TextSplittertext_splitter = RecursiveCharacterTextSplitter( chunk_size = 100, chunk_overlap = 0,)
texts = text_splitter.create_documents([explanation])
分割文本需要两个参数:每个块有多大(chunksize)和每个块有多少重叠(chunkoverlap)。让每个块之间有重叠是很重要的,可以帮助识别相关的相邻块。
每个块都可以这样获取:
texts[0].page_content
在我们有了这些块之后,我们需要把它们变成嵌入。这样向量存储就能在查询时找到并返回每个块。我们将使用OpenAI的嵌入模型来做这个。
# 导入并实例化 OpenAI embeddingsfrom langchain.embeddings import OpenAIEmbeddingsembeddings = OpenAIEmbeddings(model_name="ada") # 用嵌入把第一个文本块变成一个向量query_result = embeddings.embed_query(texts[0].page_content)print(query_result)
最后,我们需要有一个地方来存储这些向量化的嵌入。如前所述,我们将使用Pinecone来做这个。使用之前环境文件里的API密钥,我们可以初始化Pinecone来存储我们的嵌入。
# 导入并初始化Pinecone客户端
import osimport pineconefrom langchain.vectorstores
import Pineconepinecone.init( api_key=os.getenv('PINECONE_API_KEY'), environment=os.getenv('PINECONE_ENV') )
# 上传向量到
Pineconeindex_name = "langchain-quickstart"
search = Pinecone.from_documents(texts, embeddings, index_name=index_name) # 做一个简单的向量相似度搜索query = "What is magical about an autoencoder?"result = search.similarity_search(query)print(result)
现在我们能够从我们的Pinecone向量存储里查询相关的信息了!剩下要做的就是把我们学到的东西结合起来,创建我们特定的用例,给我们一个专门的AI“代理”。
3.5、代理
一个智能代理就是一个能够自主行动的AI,它可以根据输入,依次完成一系列的任务,直到达成最终的目标。这就意味着我们的AI可以利用其他的API,来实现一些功能,比如发送邮件或做数学题。如果我们再加上我们的LLM+提示链,我们就可以打造出一个适合我们需求的AI应用程序。
这部分的原理可能有点复杂,所以让我们来看一个简单的例子,来演示如何用LangChain中的一个Python代理来解决一个简单的数学问题。这个代理是通过调用我们的LLM来执行Python代码,并用NumPy来求解方程的根:
# 导入Python REPL工具并实例化Python代理
from langchain.agents.agent_toolkits
import create_python_agent from langchain.tools.python.tool
import PythonREPLToolfrom langchain.python
import PythonREPLfrom langchain.llms.openai
import OpenAI
agent_executor = create_python_agent( llm=OpenAI(temperature=0, max_tokens=1000), tool=PythonREPLTool(), verbose=True)
# 执行Python代理
agent_executor.run("找到二次函数3 * x ** 2 + 2 * x - 1的根(零点)。")
一个定制知识的聊天机器人,其实就是一个能够把问题和动作串起来的智能代理。它会把问题发送给向量化存储,然后把得到的结果和原来的问题结合起来,给出答案!
其它参考
10个最流行的向量数据库【AI】
相关文章:
用LangChain开源框架实现知识机器人
前言 Large Language Models (LLMs)在2020年OpenAI 的 GPT-3 的发布而进入世界舞台 。从那时起,他们稳步增长进入公众视野。 众所周知 OpenAI 的 API 无法联网,所以大家如果想通过它的API实现联网搜索并给出回答、总结 PDF 文档、基于某个 Youtube 视频…...
HCIP——前期综合实验
前期综合实验 一、实验拓扑二、实验要求三、实验思路四、实验步骤1、配置接口IP地址2、交换机配置划分vlan10以及vlan203、总部分部,骨干网配置OSPF分部总部骨干网 4、配置BGP建立邻居关系总部骨干网分部 5、发布用户网段6、将下一跳改为本地7、允许AS重复8、重发布…...
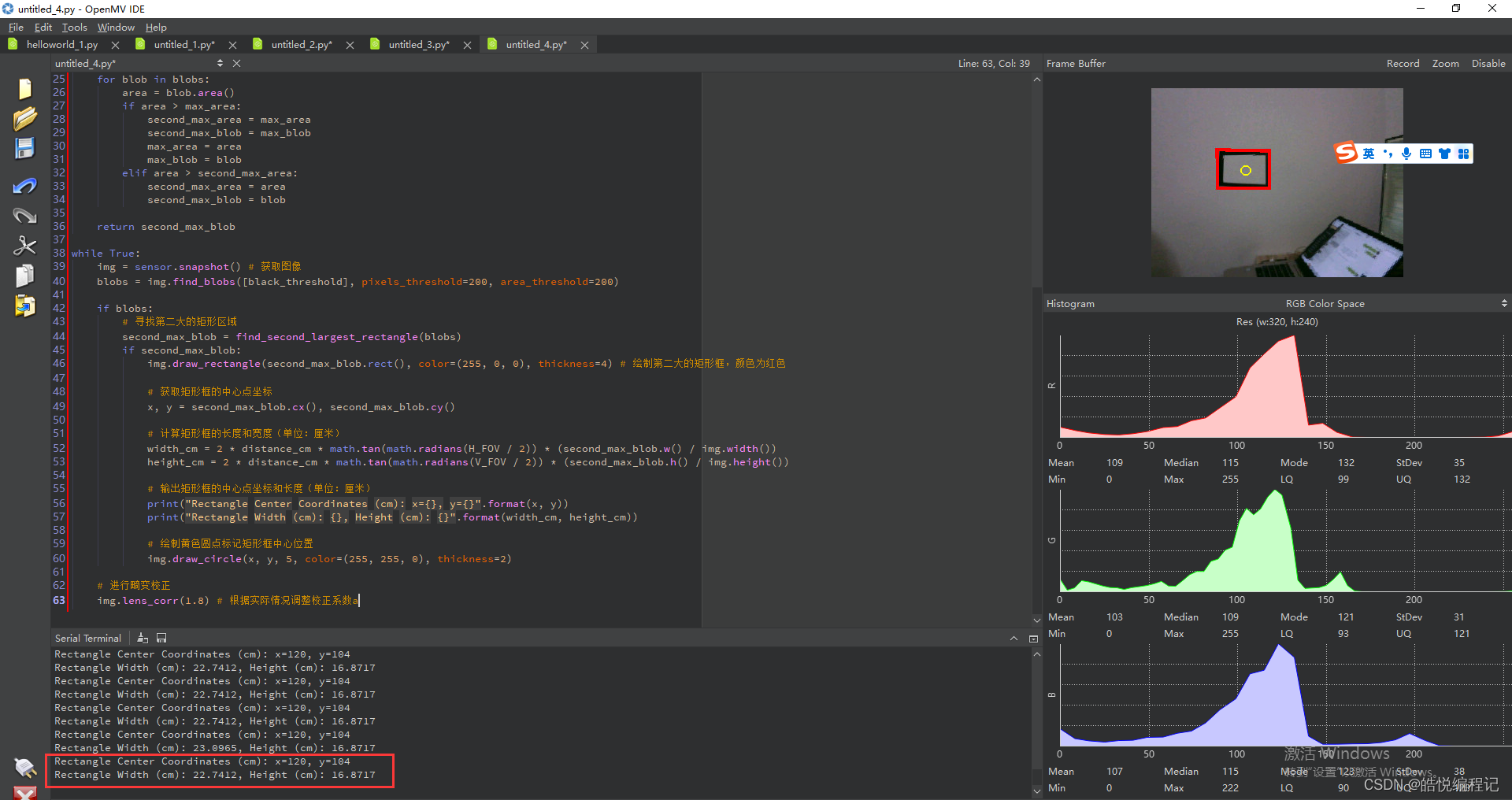
【2023年电赛】运动目标控制与自动追踪系统(E 题)最简单实现
本方案的思路是最简单的不涉及复杂算法:识别矩形框,标记矩形框,输出坐标和中心点,计算长度,控制舵机移动固定长度!仅供完成基础功能参考,不喜勿喷! # 实现运动目标控制与自动追踪系…...

【IMX6ULL驱动开发学习】22.IMX6ULL开发板读取ADC(以MQ-135为例)
IMX6ULL一共有两个ADC,每个ADC都有八个通道,但他们共用一个ADC控制器 1.设备树 在imx6ull.dtsi文件中已经帮我们定义好了adc1的节点部分信息 adc1: adc02198000 {compatible "fsl,imx6ul-adc", "fsl,vf610-adc";reg <0x0219…...

宝塔安装ModStart,快速开启高效开发之旅!
宝塔面板是一款强大的服务器管理工具,而ModStart则是基于Laravel的模块化快速开发框架,二者的结合将为您的项目开发带来前所未有的便利和高效。在这篇文章中,我们将为您详细介绍如何在宝塔面板上安装ModStart,让您快速搭建功能丰富…...
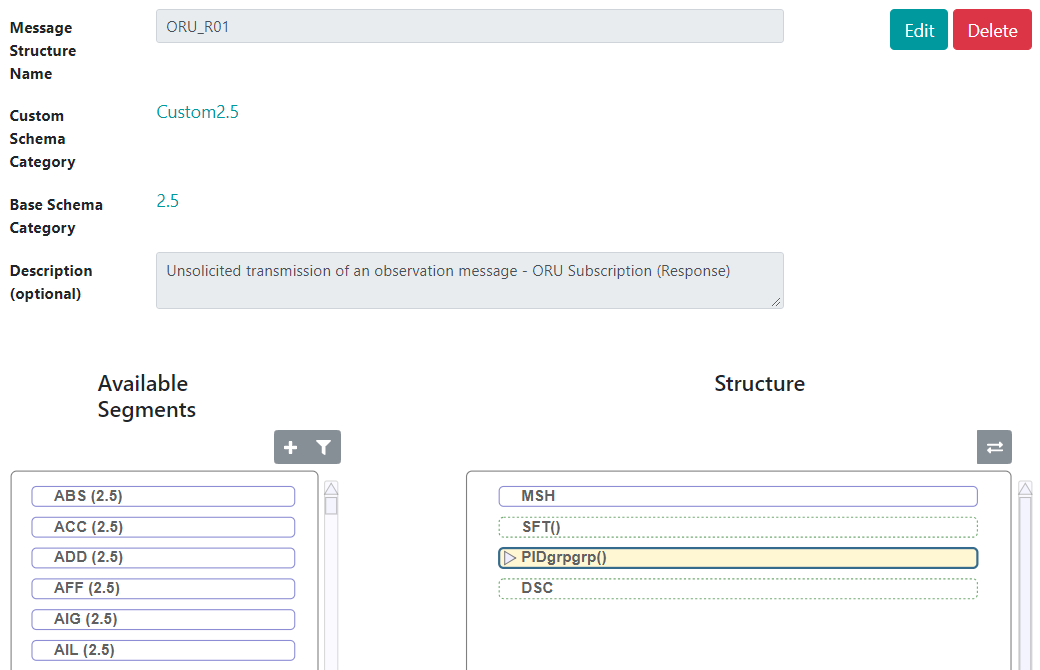
第六章 HL7 架构和可用工具 - 定义新的消息类型和结构类型
文章目录 第六章 HL7 架构和可用工具 - 定义新的消息类型和结构类型编辑数据结构和代码表 第六章 HL7 架构和可用工具 - 定义新的消息类型和结构类型 消息类型标识消息并与 HL7 MSH:9 字段中的值匹配。定义消息类型时,指定发送消息结构类型(可能与消息类…...

通向架构师的道路之Tomcat性能调优
一、总结前一天的学习 从“第三天”的性能测试一节中,我们得知了决定性能测试的几个重要指标,它们是: 吞吐量 Responsetime Cpuload MemoryUsage 我 们也在第三天的学习中对Apache做过了一定的优化,使其最优化上…...

vue03 es6中对数组的操作,vue对数据监控的原理(分别对对象和数组的监控)
在js中,对数组的操作一般都是固定的模式:常用的函数,具体的方法在这个文章中去看: http://t.csdn.cn/Fn1Ik 一般会用到的函数有: pop() 这个函数是表示把数组中的元素(数组ÿ…...

微信小程序 - 解析富文本插件版们
一、html2wxml 插件版 https://gitee.com/qwqoffice/html2wxml 申请使用注意事项 插件版本解析服务是由 QwqOffice 完成,存在不稳定因素,如对稳定性有很高的要求,请自行搭建解析服务,或在自家服务器上直接完成解析。对于有关插…...
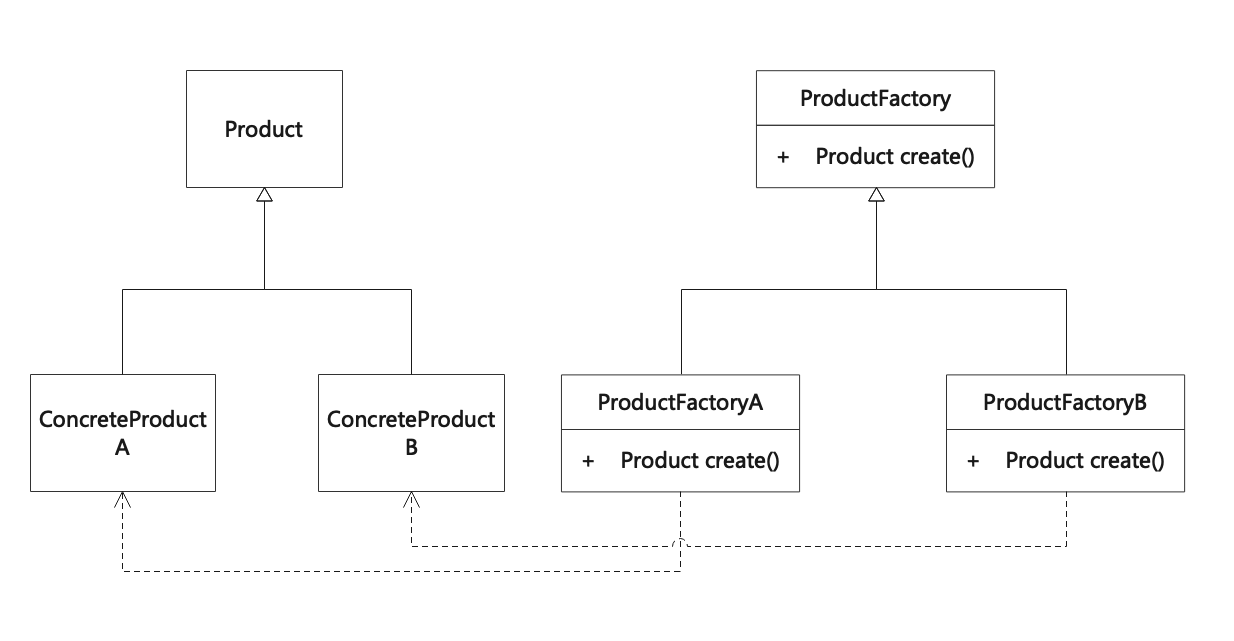
工厂方法模式(Factory Method)
工厂方法模式就是定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法模式将类的实例化(具体产品的创建)延迟到工厂类的子类(具体工厂)中完成,即由子工厂类来决定该实例化哪一个类。 Define a…...

js如何将图片转成BASE64编码,网页跟uniapp开发的app的区别?
Base64是一种用64个字符来表示任意二进制数据的方法,这篇文章主要为大家介绍了如何实现将图片转为base64格式,感兴趣的小伙伴可以学习一下 前言 前段时间在写我的VUE全栈项目的时候,遇到要把前端的照片上传到后端,再由后端存到数…...

1400*C. Computer Game
Example input 6 15 5 3 2 15 5 4 3 15 5 2 1 15 5 5 1 16 7 5 2 20 5 7 3 output 4 -1 5 2 0 1 解析: k个电, 第一种为 k>a 时,只玩游戏 k-a; 第二种,k>b,一边玩一边充电 k-b 问完成n轮游戏的情况下,优先第…...
)
windows10访问Ubuntu 18.04共享目录(已验证)
1、Ubuntu 18.04安装samba sudo apt-get install samba 2、创建一个共享目录文件夹,并设置777权限 ubt1804是用户名 mkdir/home/ubt1804/lsk sudo chmod 777 /home/ubt1804/lsk 3、添加用户及密码 sudo smbpasswd -a [用户名] 比如用户名为test sudo sm…...

Linux安装redis执行make命令报错:gcc not found和*** [adlist.o] Error 1
目录 第一章、问题分析与解决1.1)报错11.2)报错2 友情提醒 先看文章目录,大致了解文章知识点结构,点击文章目录可直接跳转到文章指定位置。 第一章、问题分析与解决 1.1)报错1 报错问题1:gcc: Command n…...

R语言glmnet包详解:横截面数据建模
R语言glmnet包详解:横截面数据建模 glmnet适用的模型glmnet建模补充glmnet适用的模型 glmnet程序包即适用于线性模型,也适用于添加惩罚项项的线性模型。如果数据中的变量个数大于样本量并且想用线性模型解决问题,那么glmnet再合适不过了! 根据glmnet函数中参数family的指定…...
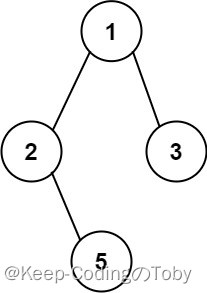
LeetCode257. 二叉树的所有路径
257. 二叉树的所有路径 文章目录 257. 二叉树的所有路径一、题目二、题解方法一:深度优先搜索递归方法二:迭代 一、题目 给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。 叶子节点 是指没有子节点…...

ajax、axios、fetch的区别
ajax、axios、fetch 的区别 参考答案: ajax 是指一种创建交互式网页应用的网页开发技术,并且可以做到无需重新加载整个网页的情况下,能够更新部分网页,也叫作局部更新。 使用 ajax 发送请求是依靠于一个对象,叫 XmlHtt…...

Liunx开发工具
Liunx开发工具 1.Linux编辑器-vim使用1.1vim的基本概念1.2vim的基本操作1.3命令模式命令集1.3.1光标定位1.3.2光标移动1.3.3文本复制1.3.4文本操作 1.4插入模式命令集1.5底行模式命令集 2.vim配置3.sudo配置4.Linux编辑器-gcc/g使用4.1背景知识4.2gcc如何操作 5.函数库5.1函数库…...

Docker入门之运行Nginx案例
运行镜像 如果你直接安装会比较慢, 建议参照附录内容配置镜像之后再执行 # 执行命令过程一:下载容器镜像 docker run -d nginx:latest 命令解释 docker run 启动一个容器 -d 把容器镜像中需要执行的命令以daemon(守护进程)的方式运行 nginx…...
【深度学习环境】安装anaconda、tensorflow、pycharm
目录 1.安装anaconda 2.安装tensorflow-gpu 3.安装pycharm 4.VNC操作 5.安装Pytorch PS: linux下常见的操作: 1.Linux下强制关闭程序: 2.导出环境 2.1.pip导出 2.2.conda导出 2.3.其他 3.windows下的环境安装 & pycharm远程配置 4.bash…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...
)
第 2 期:广告视觉提效:FastAPI+LangChain 对接豆包图片模型(附完整代码)
https://mp.weixin.qq.com/s/El8_eV3wYCW-OPungbt7ng...

ncmdumpGUI终极指南:3分钟搞定网易云音乐NCM文件转换
ncmdumpGUI终极指南:3分钟搞定网易云音乐NCM文件转换 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐的NCM加密格式而烦恼吗&…...
)
独家首发|DeepSeek官方未公开的IP检查API接口文档(含沙箱环境调用密钥获取路径)
更多请点击: https://kaifayun.com 第一章:DeepSeek知识产权检查 DeepSeek系列大模型(如DeepSeek-V2、DeepSeek-Coder、DeepSeek-MoE)由深度求索(DeepSeek)公司自主研发,其权重、训练代码、推…...