AIX360-CEMExplainer: MNIST Example
CEMExplainer: MNIST Example
- 这一部分屁话有点多,导包没问题的话可以跳过
- 加载MNIST数据集
- 加载经过训练的MNIST模型
- 加载经过训练的卷积自动编码器模型(可选)
- 初始化CEM解释程序以解释模型预测
- 解释输入实例
- 获得相关否定(Pertinent Negative,PN)解释
- 获得相关的肯定(Pertinent Positive,PP)解释
- 相关负(PN)和相关正(PP)解释图
CEMBexplainer:MNIST示例
- 本文了如何使用AIX360的CEMBexplainer来获得对比解释的示例,即对MNIST数据训练的模型所做预测的相关否定(PN)和相关肯定(PP)。
- CEMBexplainer是对比解释方法的一种实现。
- 此案例使用经过训练的模型,这些模型可从aix360/models/CEM/文件夹访问。
官方代码在https://github.com/Trusted-AI/AIX360/blob/master/examples/contrastive/CEM-MNIST.ipynb
这一部分屁话有点多,导包没问题的话可以跳过
pip install keras
pip install --user tensorflow
import os
import sys
from keras.models import model_from_json
from PIL import Image
from matplotlib import pyplot as plt
import numpy as npfrom aix360.algorithms.contrastive import CEMExplainer, KerasClassifier
from aix360.datasets import MNISTDataset
经典一步一bug,眼睛一睁一闭,休眠升天修仙。。。

TensorFlow 2.0中contrib被弃用,尝试安装旧版tensorflow
conda install tensorflow==1.14.0

看到这我真的高兴坏了,之前不小心把python版本装高了,没办法,就是这么倒霉,推倒重来,官网怎么喜欢用那么老的版本,为什么我的眼里常含泪水,因为对知识爱得深沉。。。
重新创建个虚拟环境,
python3.6python3.6python3.6python3.6python3.6python3.6python3.6python3.6python3.6python3.6python3.6python3.6
https://blog.csdn.net/weixin_45735391/article/details/133197625
python3.6python3.6python3.6python3.6python3.6python3.6python3.6python3.6python3.6python3.6python3.6python3.6
清华源似乎没有这个古老的版本。。。

emmmm,又是一个坑。。。
python3.7python3.7python3.7python3.7python3.7python3.7python3.7python3.7python3.7python3.7python3.7python3.7
https://blog.csdn.net/weixin_45735391/article/details/133197625
python3.7python3.7python3.7python3.7python3.7python3.7python3.7python3.7python3.7python3.7python3.7python3.7
此倒霉蛋已疯。。。
tensorflow装好了,又多活了一天,欧耶!!!

可是

此人g了。。。那就pip吧。。。
pip install aix360

看着它那么红,就让它红这吧。。。
人生嘛,惊喜不断,不然多无聊,哈哈哈。。。

pip install skimage


pip install scikit-image
还差亿点点。。。

conda install pytorch
还差亿点点。。。

conda install requests
不想看见这坨警告的话,可以加上
import warnings
warnings.filterwarnings("ignore")

好了,导包这块终于结束了。
又多活了一天,真不错,今天是个好日子。。。
加载MNIST数据集
# load MNIST data and normalize it in the range [-0.5, 0.5]
data = MNISTDataset()
花的时间有亿点点久。。。真的等不下去了。。。脑子已经在修仙了。。。
看看源码写的啥
class MNISTDataset():def __init__(self, custom_preprocessing=None, dirpath=None): self._dirpath = dirpathif not self._dirpath:self._dirpath = os.path.join(os.path.dirname(os.path.abspath(__file__)),'..', 'data','mnist_data')files = ["train-images-idx3-ubyte.gz","t10k-images-idx3-ubyte.gz","train-labels-idx1-ubyte.gz","t10k-labels-idx1-ubyte.gz"]for name in files:if not os.path.exists(self._dirpath + "/" + name):print("retrieving file", name)urllib.request.urlretrieve('http://yann.lecun.com/exdb/mnist/' + name, self._dirpath + "/" + name)print("retrieved")train_data = extract_data(self._dirpath + "/train-images-idx3-ubyte.gz", 60000)train_labels = extract_labels(self._dirpath + "/train-labels-idx1-ubyte.gz", 60000)self.test_data = extract_data(self._dirpath + "/t10k-images-idx3-ubyte.gz", 10000)self.test_labels = extract_labels(self._dirpath + "/t10k-labels-idx1-ubyte.gz", 10000)VALIDATION_SIZE = 5000self.validation_data = train_data[:VALIDATION_SIZE, :, :, :]self.validation_labels = train_labels[:VALIDATION_SIZE]self.train_data = train_data[VALIDATION_SIZE:, :, :, :]self.train_labels = train_labels[VALIDATION_SIZE:]
直接百度搜一下下载MNIST数据集,找到别人分享的资源,把这四个文件["train-images-idx3-ubyte.gz","t10k-images-idx3-ubyte.gz","train-labels-idx1-ubyte.gz", "t10k-labels-idx1-ubyte.gz"]下载下来。
然后代码改一下,dirpath就是那四个文件的保存路径。
dirpath = r'C:\Users\gxx\Desktop\jupter\aix360\MNIST'
data = MNISTDataset(dirpath=dirpath)
# print the shape of train and test data
print("MNIST train data range :", "(", np.min(data.train_data), ",", np.max(data.train_data), ")")
print("MNIST test data range :", "(", np.min(data.train_data), ",", np.max(data.train_data), ")")
print("MNIST train data shape :", data.train_data.shape)
print("MNIST test data shape :", data.test_data.shape)
print("MNIST train labels shape:", data.test_labels.shape)
print("MNIST test labels shape :", data.test_labels.shape)
输出结果
MNIST train data range : ( -0.5 , 0.5 )
MNIST test data range : ( -0.5 , 0.5 )
MNIST train data shape : (55000, 28, 28, 1)
MNIST test data shape : (10000, 28, 28, 1)
MNIST train labels shape: (10000, 10)
MNIST test labels shape : (10000, 10)
加载经过训练的MNIST模型
此notebook使用经过训练的MNIST模型。此处提供了训练此模型的代码。请注意,该模型输出logits,并且不使用softmax函数。
把官网上的文件复制到本地,改一下路径。
# path to mnist related models
# model_path = '../../aix360/models/CEM'
model_path = r'C:\Users\gxx\Desktop\jupter\aix360\CEM'def load_model(model_json_file, model_wt_file):# read model json filewith open(model_json_file, 'r') as f:model = model_from_json(f.read())# read model weights filemodel.load_weights(model_wt_file)return model# load MNIST model using its json and wt files
mnist_model = load_model(os.path.join(model_path, 'mnist.json'), os.path.join(model_path, 'mnist'))# print model summary
mnist_model.summary()
不出意外,bug又来了。。。


在安装 tensorflow 时,默认安装 h5py 为3.7.0,而报错是因为安装的 TF 不支持过高版本的 h5py。
卸 载 h5py 3.7.0版本,安装 h5py 2.10.0 版本。
pip uninstall --user h5py
pip install --user h5py==2.10.0
结果输出:

加载经过训练的卷积自动编码器模型(可选)
这个notebook使用了一个经过训练的卷积自动编码器模型。此处提供了训练此模型的代码。
# load the trained convolutional autoencoder model
ae_model = load_model(os.path.join(model_path, 'mnist_AE_1_decoder.json'), os.path.join(model_path, 'mnist_AE_1_decoder.h5'))
# print model summary
ae_model.summary()

初始化CEM解释程序以解释模型预测
# wrap mnist_model into a framework independent class structure
mymodel = KerasClassifier(mnist_model)# initialize explainer object
explainer = CEMExplainer(mymodel)
解释输入实例
# choose an input image
image_id = 340
input_image = data.test_data[image_id]# rescale values from [-0.5, 0.5] to [0, 255] for plotting
plt.imshow((input_image[:,:,0] + 0.5)*255, cmap="gray")# check model prediction
print("Predicted class:", mymodel.predict_classes(np.expand_dims(input_image, axis=0)))
print("Predicted logits:", mymodel.predict(np.expand_dims(input_image, axis=0)))
结果输出:

观察结果:
尽管上面的图像被模型分类为数字3,但是由于它与数字5具有相似性,所以它也可以被分类为数字5。我们现在使用AIX360的CEMBexplainer来计算相关的正面和负面解释,这有助于我们理解为什么图像被模型分类为数字3而不是数字5。
获得相关否定(Pertinent Negative,PN)解释
arg_mode = "PN" # Find pertinent negativearg_max_iter = 1000 # Maximum number of iterations to search for the optimal PN for given parameter settings
arg_init_const = 10.0 # Initial coefficient value for main loss term that encourages class change
arg_b = 9 # No. of updates to the coefficient of the main loss termarg_kappa = 0.9 # Minimum confidence gap between the PNs (changed) class probability and original class' probability
arg_beta = 1.0 # Controls sparsity of the solution (L1 loss)
arg_gamma = 100 # Controls how much to adhere to a (optionally trained) autoencoder
arg_alpha = 0.01 # Penalizes L2 norm of the solution
arg_threshold = 0.05 # Automatically turn off features <= arg_threshold if arg_threshold < 1
arg_offset = 0.5 # the model assumes classifier trained on data normalized# in [-arg_offset, arg_offset] range, where arg_offset is 0 or 0.5(adv_pn, delta_pn, info_pn) = explainer.explain_instance(np.expand_dims(input_image, axis=0), arg_mode, ae_model, arg_kappa, arg_b, arg_max_iter, arg_init_const, arg_beta, arg_gamma, arg_alpha, arg_threshold, arg_offset)
结果输出:
WARNING:tensorflow:From C:\Users\gxx\anaconda3\envs\tf-py37\lib\site-packages\aix360\algorithms\contrastive\CEM_aen.py:60: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.WARNING:tensorflow:From C:\Users\gxx\anaconda3\envs\tf-py37\lib\site-packages\aix360\algorithms\contrastive\CEM_aen.py:151: The name tf.assign is deprecated. Please use tf.compat.v1.assign instead.WARNING:tensorflow:From C:\Users\gxx\anaconda3\envs\tf-py37\lib\site-packages\aix360\algorithms\contrastive\CEM_aen.py:213: The name tf.train.polynomial_decay is deprecated. Please use tf.compat.v1.train.polynomial_decay instead.WARNING:tensorflow:From C:\Users\gxx\anaconda3\envs\tf-py37\lib\site-packages\tensorflow\python\keras\optimizer_v2\learning_rate_schedule.py:409: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Deprecated in favor of operator or tf.math.divide.
WARNING:tensorflow:From C:\Users\gxx\anaconda3\envs\tf-py37\lib\site-packages\aix360\algorithms\contrastive\CEM_aen.py:216: The name tf.train.GradientDescentOptimizer is deprecated. Please use tf.compat.v1.train.GradientDescentOptimizer instead.WARNING:tensorflow:From C:\Users\gxx\anaconda3\envs\tf-py37\lib\site-packages\tensorflow\python\ops\math_grad.py:1250: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
WARNING:tensorflow:From C:\Users\gxx\anaconda3\envs\tf-py37\lib\site-packages\aix360\algorithms\contrastive\CEM_aen.py:230: The name tf.variables_initializer is deprecated. Please use tf.compat.v1.variables_initializer instead.iter:0 const:[10.]
Loss_Overall:2737.2244, Loss_Attack:58.5389
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:2678.685546875
target_lab_score:19.3967, max_nontarget_lab_score:14.4428iter:500 const:[10.]
Loss_Overall:2737.2244, Loss_Attack:58.5389
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:2678.685546875
target_lab_score:19.3967, max_nontarget_lab_score:14.4428iter:0 const:[100.]
Loss_Overall:3152.3984, Loss_Attack:0.0000
Loss_L2Dist:12.6054, Loss_L1Dist:16.5280, AE_loss:3123.264892578125
target_lab_score:9.0004, max_nontarget_lab_score:29.0375iter:500 const:[100.]
Loss_Overall:2977.4854, Loss_Attack:0.0000
Loss_L2Dist:7.0313, Loss_L1Dist:10.1030, AE_loss:2960.35107421875
target_lab_score:9.2486, max_nontarget_lab_score:28.5018iter:0 const:[55.]
Loss_Overall:2840.0422, Loss_Attack:0.0000
Loss_L2Dist:4.8674, Loss_L1Dist:7.2291, AE_loss:2827.94580078125
target_lab_score:9.7374, max_nontarget_lab_score:27.1471iter:500 const:[55.]
Loss_Overall:2670.4844, Loss_Attack:0.0000
Loss_L2Dist:0.8409, Loss_L1Dist:2.1313, AE_loss:2667.51220703125
target_lab_score:15.5937, max_nontarget_lab_score:19.4013iter:0 const:[32.5]
Loss_Overall:2644.0203, Loss_Attack:2.0429
Loss_L2Dist:0.5595, Loss_L1Dist:1.8527, AE_loss:2639.565185546875
target_lab_score:16.7141, max_nontarget_lab_score:17.5513iter:500 const:[32.5]
Loss_Overall:2868.9368, Loss_Attack:190.2513
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:2678.685546875
target_lab_score:19.3967, max_nontarget_lab_score:14.4428iter:0 const:[21.25]
Loss_Overall:2782.8979, Loss_Attack:117.1809
Loss_L2Dist:0.0176, Loss_L1Dist:0.2093, AE_loss:2665.490234375
target_lab_score:19.1928, max_nontarget_lab_score:14.5784iter:500 const:[21.25]
Loss_Overall:2803.0806, Loss_Attack:124.3951
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:2678.685546875
target_lab_score:19.3967, max_nontarget_lab_score:14.4428iter:0 const:[26.875]
Loss_Overall:2738.9089, Loss_Attack:91.5858
Loss_L2Dist:0.1530, Loss_L1Dist:0.9359, AE_loss:2646.234130859375
target_lab_score:18.1907, max_nontarget_lab_score:15.6829iter:500 const:[26.875]
Loss_Overall:2836.0088, Loss_Attack:157.3232
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:2678.685546875
target_lab_score:19.3967, max_nontarget_lab_score:14.4428iter:0 const:[24.0625]
Loss_Overall:2774.3594, Loss_Attack:117.5742
Loss_L2Dist:0.0524, Loss_L1Dist:0.4683, AE_loss:2656.2646484375
target_lab_score:18.8622, max_nontarget_lab_score:14.8760iter:500 const:[24.0625]
Loss_Overall:2819.5447, Loss_Attack:140.8591
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:2678.685546875
target_lab_score:19.3967, max_nontarget_lab_score:14.4428iter:0 const:[25.46875]
Loss_Overall:2754.6963, Loss_Attack:104.3005
Loss_L2Dist:0.0950, Loss_L1Dist:0.7232, AE_loss:2649.57763671875
target_lab_score:18.5058, max_nontarget_lab_score:15.3106iter:500 const:[25.46875]
Loss_Overall:2827.7766, Loss_Attack:149.0911
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:2678.685546875
target_lab_score:19.3967, max_nontarget_lab_score:14.4428iter:0 const:[24.765625]
Loss_Overall:2762.2129, Loss_Attack:109.3322
Loss_L2Dist:0.0725, Loss_L1Dist:0.6168, AE_loss:2652.191650390625
target_lab_score:18.6550, max_nontarget_lab_score:15.1403iter:500 const:[24.765625]
Loss_Overall:2823.6606, Loss_Attack:144.9751
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:2678.685546875
target_lab_score:19.3967, max_nontarget_lab_score:14.4428
print(info_pn)
结果输出:
[INFO]kappa:0.9, Orig class:3, Perturbed class:5, Delta class: 1, Orig prob:[[-11.279339 0.73625 -9.008647 19.396711 -8.286123 14.442826 -1.3170443 -11.587322 -0.992185 1.0182207]], Perturbed prob:[[ -6.6607647 -1.9869652 -7.4231925 13.461045 -6.341817 13.8300295 1.2803447 -11.60892 0.31489015 1.1112802 ]], Delta prob:[[-0.11039171 1.0537697 -0.0954444 -0.2623107 -0.3357536 0.24241148 -0.0948096 -0.00691785 -0.31975082 -0.56200165]]
获得相关的肯定(Pertinent Positive,PP)解释
arg_mode = "PP" # Find pertinent positive
arg_beta = 0.1 # Controls sparsity of the solution (L1 loss)
(adv_pp, delta_pp, info_pp) = explainer.explain_instance(np.expand_dims(input_image, axis=0), arg_mode, ae_model, arg_kappa, arg_b, arg_max_iter, arg_init_const, arg_beta, arg_gamma, arg_alpha, arg_threshold, arg_offset)
结果输出:
iter:0 const:[10.]
Loss_Overall:1186.7114, Loss_Attack:20.4772
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:1166.2342529296875
target_lab_score:-0.1036, max_nontarget_lab_score:1.0441iter:500 const:[10.]
Loss_Overall:1186.7114, Loss_Attack:20.4772
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:1166.2342529296875
target_lab_score:-0.1036, max_nontarget_lab_score:1.0441iter:0 const:[100.]
Loss_Overall:1374.8175, Loss_Attack:224.8764
Loss_L2Dist:0.0581, Loss_L1Dist:0.5667, AE_loss:1149.8262939453125
target_lab_score:-0.1908, max_nontarget_lab_score:1.1579iter:500 const:[100.]
Loss_Overall:1177.7847, Loss_Attack:0.0000
Loss_L2Dist:9.0615, Loss_L1Dist:26.9499, AE_loss:1166.0281982421875
target_lab_score:9.1723, max_nontarget_lab_score:5.3354iter:0 const:[55.]
Loss_Overall:1278.8588, Loss_Attack:112.6245
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:1166.2342529296875
target_lab_score:-0.1036, max_nontarget_lab_score:1.0441iter:500 const:[55.]
Loss_Overall:1278.8588, Loss_Attack:112.6245
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:1166.2342529296875
target_lab_score:-0.1036, max_nontarget_lab_score:1.0441iter:0 const:[77.5]
Loss_Overall:1324.9324, Loss_Attack:158.6981
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:1166.2342529296875
target_lab_score:-0.1036, max_nontarget_lab_score:1.0441iter:500 const:[77.5]
Loss_Overall:1324.9324, Loss_Attack:158.6981
Loss_L2Dist:0.0000, Loss_L1Dist:0.0000, AE_loss:1166.2342529296875
target_lab_score:-0.1036, max_nontarget_lab_score:1.0441iter:0 const:[88.75]
Loss_Overall:1347.3350, Loss_Attack:190.4548
Loss_L2Dist:0.0195, Loss_L1Dist:0.2384, AE_loss:1156.8367919921875
target_lab_score:-0.1378, max_nontarget_lab_score:1.1082iter:500 const:[88.75]
Loss_Overall:1182.4167, Loss_Attack:0.0000
Loss_L2Dist:10.1261, Loss_L1Dist:29.5733, AE_loss:1169.3333740234375
target_lab_score:10.9503, max_nontarget_lab_score:8.5652iter:0 const:[83.125]
Loss_Overall:1336.9946, Loss_Attack:176.8078
Loss_L2Dist:0.0096, Loss_L1Dist:0.1385, AE_loss:1160.1634521484375
target_lab_score:-0.1352, max_nontarget_lab_score:1.0918iter:500 const:[83.125]
Loss_Overall:1177.7847, Loss_Attack:0.0000
Loss_L2Dist:9.0615, Loss_L1Dist:26.9499, AE_loss:1166.0281982421875
target_lab_score:9.1723, max_nontarget_lab_score:5.3355iter:0 const:[80.3125]
Loss_Overall:1330.7108, Loss_Attack:169.8772
Loss_L2Dist:0.0070, Loss_L1Dist:0.1182, AE_loss:1160.8148193359375
target_lab_score:-0.1306, max_nontarget_lab_score:1.0846iter:500 const:[80.3125]
Loss_Overall:1187.8037, Loss_Attack:0.0000
Loss_L2Dist:9.0935, Loss_L1Dist:26.5365, AE_loss:1176.0565185546875
target_lab_score:10.0619, max_nontarget_lab_score:2.9340iter:0 const:[78.90625]
Loss_Overall:1327.5865, Loss_Attack:166.4040
Loss_L2Dist:0.0058, Loss_L1Dist:0.1080, AE_loss:1161.1658935546875
target_lab_score:-0.1282, max_nontarget_lab_score:1.0807iter:500 const:[78.90625]
Loss_Overall:1176.6401, Loss_Attack:0.0000
Loss_L2Dist:8.3147, Loss_L1Dist:24.4263, AE_loss:1165.8828125
target_lab_score:8.1241, max_nontarget_lab_score:4.7113iter:0 const:[78.203125]
Loss_Overall:1326.0416, Loss_Attack:164.6752
Loss_L2Dist:0.0053, Loss_L1Dist:0.1030, AE_loss:1161.350830078125
target_lab_score:-0.1270, max_nontarget_lab_score:1.0788iter:500 const:[78.203125]
Loss_Overall:1180.0135, Loss_Attack:0.0000
Loss_L2Dist:9.0324, Loss_L1Dist:26.5381, AE_loss:1168.327392578125
target_lab_score:9.0967, max_nontarget_lab_score:5.0136
print(info_pp)
结果输出:
[INFO]kappa:0.9, Orig class:3, Perturbed class:3, Delta class: 3, Orig prob:[[-11.279339 0.73625 -9.008647 19.396711 -8.286123 14.442826 -1.3170443 -11.587322 -0.992185 1.0182207]], Perturbed prob:[[ -6.0453925 -0.16173983 -6.025815 11.575153 -3.0273986 11.318211 4.259432 -11.328725 -1.0278873 -2.3766122 ]], Delta prob:[[-2.3122752 0.60199463 -0.6148693 4.709517 -2.2623286 1.0073487 -2.2190797 -0.83646446 -1.5357832 0.9802128 ]]
相关负(PN)和相关正(PP)解释图
# rescale values from [-0.5, 0.5] to [0, 255] for plotting
fig0 = (input_image[:,:,0] + 0.5)*255fig1 = (adv_pn[0,:,:,0] + 0.5) * 255
fig2 = (fig1 - fig0) #rescaled delta_pn
fig3 = (adv_pp[0,:,:,0] + 0.5) * 255
fig4 = (delta_pp[0,:,:,0] + 0.5) * 255 #rescaled delta_ppf, axarr = plt.subplots(1, 5, figsize=(10,10))
axarr[0].set_title("Original" + "(" + str(mymodel.predict_classes(np.expand_dims(input_image, axis=0))[0]) + ")")
axarr[1].set_title("Original + PN" + "(" + str(mymodel.predict_classes(adv_pn)[0]) + ")")
axarr[2].set_title("PN")
axarr[3].set_title("Original + PP")
axarr[4].set_title("PP" + "(" + str(mymodel.predict_classes(delta_pp)[0]) + ")")axarr[0].imshow(fig0, cmap="gray")
axarr[1].imshow(fig1, cmap="gray")
axarr[2].imshow(fig2, cmap="gray")
axarr[3].imshow(fig3, cmap="gray")
axarr[4].imshow(fig4, cmap="gray")
plt.show()
结果输出:

说明:
- PP突出显示图像中存在的最小像素集,以便将其分类为数字3。注意,原始图像和PP都被分类器分类为数字3。
- PN在顶部突出显示一条小水平线,该水平线的存在会将原始图像的分类改变为数字5,因此应该不存在,以便分类保持为数字3。
相关文章:
AIX360-CEMExplainer: MNIST Example
CEMExplainer: MNIST Example 这一部分屁话有点多,导包没问题的话可以跳过加载MNIST数据集加载经过训练的MNIST模型加载经过训练的卷积自动编码器模型(可选)初始化CEM解释程序以解释模型预测解释输入实例获得相关否定(Pertinent N…...

TouchGFX之自定义控件
在创建应用时,您可能需要TouchGFX中没有包含的控件。在创建应用时,您可能需要TouchGFX中没有包含的控件。但有时此法并不够用,当您需要全面控制帧缓冲时,您需要使用自定义控件法。 TouchGFX Designer目前不支持自定义控件的创建。…...

Python中match...case的用法
在C语言中有switch...case语句,Pthon3.10之前应该是没有类似语法,从Python3.10开始引入match...case与switch分支语句用法类似,但有细微差别,总结如下: 1.语法 肉眼可见的是关键词从switch变成了match,同…...
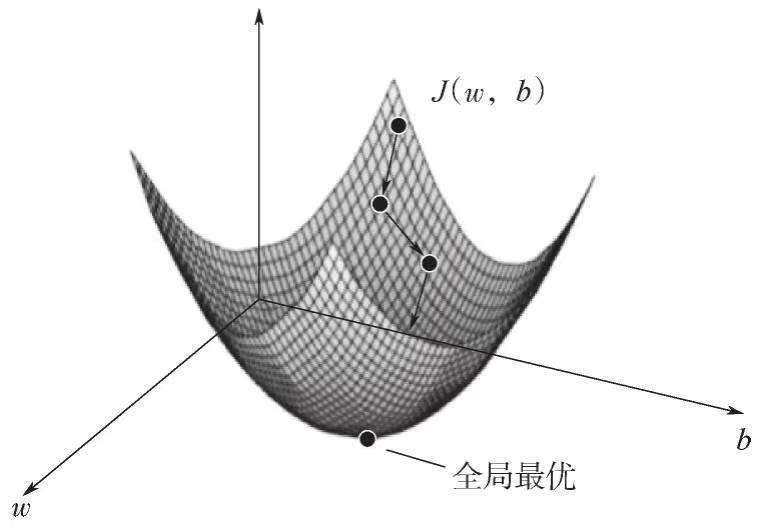
深度学习自学笔记二:逻辑回归和梯度下降法
目录 一、逻辑回归 二、逻辑回归的代价函数 三、梯度下降法 一、逻辑回归 逻辑回归是一种常用的二分类算法,用于将输入数据映射到一个概率输出,表示为属于某个类别的概率。它基于线性回归模型,并使用了sigmoid函数作为激活函数。 假设我们…...
【Element】通知 Notification
ElementUI 弹出通知 created() {const h this.$createElementconst that thisthis.$notify({onClose: function () {that.do()},type: warning,duration: 5000, // 5秒后隐藏offset: 0, // 距离顶部dangerouslyUseHTMLString: false, showClose: false,customClass: notify-…...
vue+express、gitee pm2部署轻量服务器(20230923)
一、代码配置 前后端接口都保持 127.0.0.1:3000 vue 项目 创建文件 pm2.config.cjs module.exports {apps: [{name: xin-web, // 应用程序的名称script: npm, // 启动脚本args: run dev, // 启动脚本的参数cwd: /home/vue/xin_web, // Vite 项目的根目录interpreter: none,…...

前端教程-H5游戏开发
Egret EGRETIA RC 版本正式发布 从端到云一站式区块链游戏开发工作流 官网 Laya Air 在渲染模式上,LayaAir 支持 Canvas 和 WebGL 两种方式;在工具流的支持程度上,主要是提供了 LayaAir IDE。LayaAir IDE 包括代码模式与设计模式ÿ…...
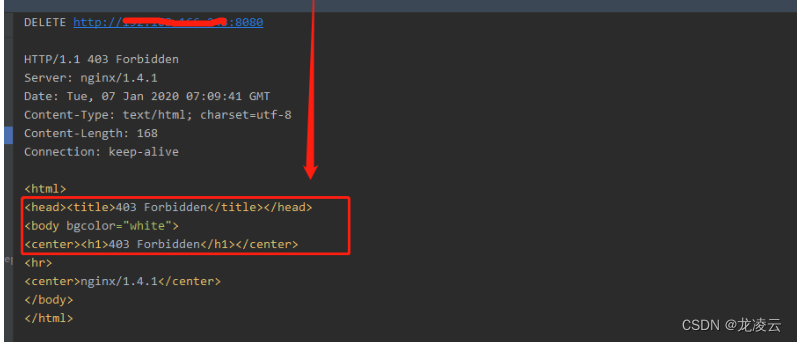
Nginx 关闭/屏蔽 PUT、DELETE、OPTIONS 请求
1、修改 nginx 配置 在 nginx 配置文件中,增加如下配置内容: if ($request_method !~* GET|POST|HEAD) {return 403; }修改效果如下: 2、重启 nginx 服务 systemctl restart nginx或者 service nginx restart3、功能验证 使用如下方式…...

【React】React概念、特点和Jsx基础语法
React是什么? React 是一个用于构建用户界面的 JavaScript 库。 是一个将数据渲染为 HTML 视图的开源 JS 库它遵循基于组件的方法,有助于构建可重用的 UI 组件它用于开发复杂的交互式的 web 和移动 UI React有什么特点 使用虚拟 DOM 而不是真正的 DO…...

大数据的崭露头角:数据湖与数据仓库的融合之道
文章目录 数据湖与数据仓库的基本概念数据湖(Data Lake)数据仓库(Data Warehouse) 数据湖和数据仓库的优势和劣势数据湖的优势数据湖的劣势数据仓库的优势数据仓库的劣势 数据湖与数据仓库的融合之道1. 数据分类和标记2. 元数据管…...

用go实现cors中间件
目录 一、概述 二、简单请求和预检请求 简单请求 预检请求 三、使用go的gin框架实现cors配置 1、安装 2、函数 一、概述 CORS(Cross-Origin Resource Sharing)是一种浏览器安全机制,用于控制在Web应用程序中不同源(Origin&a…...
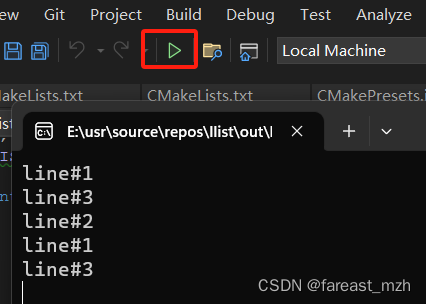
Linux 链表示例 LIST_INIT LIST_INSERT_HEAD
list(3) — Linux manual page 用Visual Studio 2022创建CMake项目 * CmakeLists.txt # CMakeList.txt : Top-level CMake project file, do global configuration # and include sub-projects here. # cmake_minimum_required (VERSION 3.12)project ("llist")# I…...
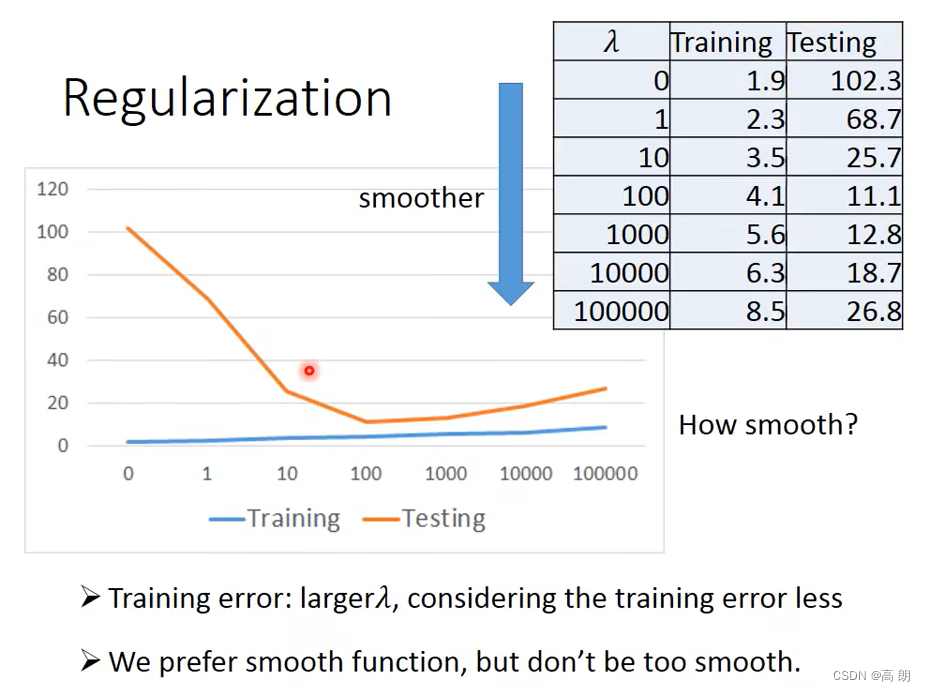
【机器学习】详解回归(Regression)
文章目录 是什么的问题案例说明 是什么的问题 回归分析(Regression Analysis) 是研究自变量与因变量之间数量变化关系的一种分析方法,它主要是通过因变量Y与影响它的自变量 X i ( i 1 , 2 , 3 … ) X_i(i1…...
mac 配置 httpd nginx php-fpm 详细记录 已解决
在日常mac电脑 开发php项目一直是 httpd 方式 运行,由于有 多版本 运行的需求,docker不想用,索性用 php-fpm进行 功能处理。上次配置 是好的,但是感觉马马虎虎,这次 配置底朝天。因为配置服务器,几乎也都是…...

Angular 项目升级需要注意什么?
升级Angular项目是一个重要的任务,因为它可以帮助你获得新的功能、性能改进和安全性增强。然而,Angular的版本升级可能会涉及到一些潜在的问题和挑战。以下是升级Angular项目时需要注意的一些重要事项: 备份项目:在升级之前&…...

开发高性能知识付费平台:关键技术策略
引言 在构建知识付费平台时,高性能是确保用户满意度和平台成功的关键因素之一。本文将探讨一些关键的技术策略,帮助开发者打造高性能的知识付费平台。 1. 前端性能优化 使用CDN加速资源加载 使用内容分发网络(CDN)来托管和加…...

python图像匹配:如何使用Python进行图像匹配
Python图像匹配是指使用Python编写的程序来进行图像匹配。它可以在两幅图像之间找到相似的部分,从而实现图像检索、图像比较、图像拼接等功能。 Python图像匹配是指使用Python编写的程序来进行图像匹配。它可以在两幅图像之间找到相似的部分,从而实现图…...
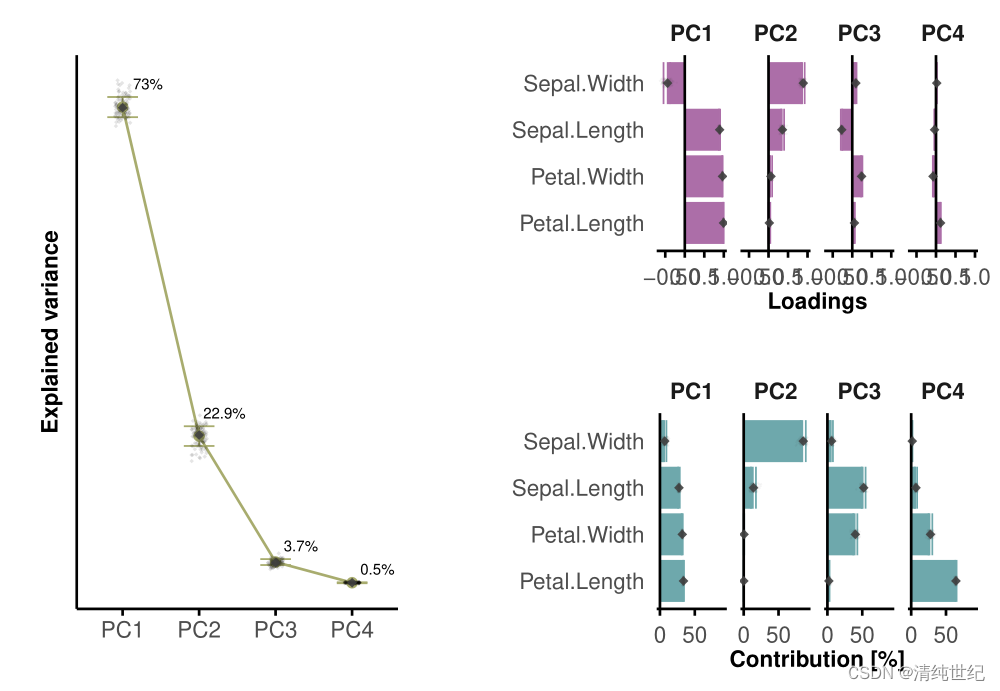
R语言绘制PCA双标图、碎石图、变量载荷图和变量贡献图
1、原论文数据双标图 代码: setwd("D:/Desktop/0000/R") #更改路径#导入数据 df <- read.table("Input data.csv", header T, sep ",")# ----------------------------------- #所需的包: packages <- c("ggplot2&quo…...
)
Jolokia 笔记 (Kafka/start/stop)
目录 1. Jolokia 笔记 (Kafka/start/stop) 1. Jolokia 笔记 (Kafka/start/stop) java -javaagent:agent.jarport8778,hostlocalhostJolokia 是作为 Kafka 的 Java agent, 基于 HTTP 协议提供了一个使用 JSON 作为数据格式的外部接口, 提供给 DataKit 使用。 Kafka 启动时, 先配…...
Qt5开发及实例V2.0-第十九章-Qt.QML编程基础
Qt5开发及实例V2.0-第十九章-Qt.QML编程基础 第19章 QML编程基础19.1 QML概述19.1.1 第一个QML程序19.1.2 QML文档构成19.1.3 QML基本语法 19.2 QML可视元素19.2.1 Rectangle(矩形)元素19.2.2 Image(图像)元素19.2.3 Text…...

告别网络调试焦虑:用STM32CubeMX+FreeRTOS,给LAN8720A和LWIP做个“健康检查”与性能小优化
STM32网络子系统深度优化:从连通性测试到工业级稳定性实战 当你熬夜调试的嵌入式设备终于能Ping通时,那种喜悦感堪比程序员第一次写出"Hello World"。但很快你会发现,真正的挑战才刚刚开始——那些在演示视频里永远不会出现的诡异断…...

Android音频设备切换背后的秘密:AudioPolicyService与HAL交互全解析
Android音频设备切换机制深度解析:从AudioPolicyService到HAL的完整链路 在移动设备的多媒体体验中,音频设备切换的流畅性直接影响用户体验。当用户插入耳机、连接蓝牙设备或切换扬声器时,系统如何在毫秒级完成音频路由的重构?本文…...

如何在Windows 11上高效配置三指拖拽功能:完整实用指南
如何在Windows 11上高效配置三指拖拽功能:完整实用指南 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/ThreeFingersDragO…...

高并发场景下的B2B对公支付方案:聚合支付、错付拦截与自动化对账
在B2B交易场景中,大额对公支付一直是一个绕不开的技术难题。与C端支付不同,B2B交易涉及百万级甚至千万级资金流转,传统的线下转账模式不仅流程繁琐,还带来了财务对账耗时、错付退款难、客户付款流失率高等一系列问题。本文将从技术…...

别再让广播闪退!Android 14广播安全新规RECEIVER_EXPORTED的保姆级避坑指南
Android 14广播安全新规:RECEIVER_EXPORTED的深度解析与实战指南 去年秋天,当Google正式发布Android 14时,许多开发者发现原本运行良好的广播注册代码突然开始抛出SecurityException。这个看似简单的API变更背后,其实是Android团队…...

Phi-4-mini-reasoning企业应用:替代传统规则引擎做逻辑校验服务
Phi-4-mini-reasoning企业应用:替代传统规则引擎做逻辑校验服务 1. 为什么企业需要逻辑校验服务 在现代企业系统中,逻辑校验无处不在。从电商平台的优惠券规则验证,到金融系统的风控审核,再到制造业的工艺流程检查,都…...

零代码构建智能安防平台:WVP-GB28181-Pro的5个技术突破
零代码构建智能安防平台:WVP-GB28181-Pro的5个技术突破 【免费下载链接】wvp-GB28181-pro 基于GB28181-2016、部标808、部标1078标准实现的开箱即用的网络视频平台。自带管理页面,支持NAT穿透,支持海康、大华、宇视等品牌的IPC、NVR接入。支持…...
)
VASP表面建模进阶:利用现代脚本工具实现Slab模型原子选择性固定(POSCAR高效处理)
1. 为什么需要自动化处理POSCAR文件 在计算材料学领域,VASP作为第一性原理计算的黄金标准工具,其输入文件POSCAR的准确性直接决定了计算结果的可靠性。传统手动处理方式存在几个致命缺陷:首先,用Excel手工标记原子固定状态极易出错…...

深度解析猫抓浏览器扩展资源嗅探机制与性能优化策略
深度解析猫抓浏览器扩展资源嗅探机制与性能优化策略 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat Catch)作为一…...

FreeRTOS任务优先级怎么设?从智能健康助手项目看LVGL、传感器、看门狗任务的调度实战
FreeRTOS任务优先级设计实战:智能健康助手的调度艺术 在嵌入式系统开发中,任务优先级设置往往决定了整个系统的响应性和稳定性。我曾在一个智能健康监测设备项目中,面对LVGL界面、多传感器数据采集和系统监控等多任务协同工作的挑战…...