Transformer 模型:入门详解(1)
动动发财的小手,点个赞吧!
简介
众所周知,transformer 架构是自然语言处理 (NLP) 领域的一项突破。它克服了 seq-to-seq 模型(如 RNN 等)无法捕获文本中的长期依赖性的局限性。事实证明,transformer 架构是 BERT、GPT 和 T5 及其变体等革命性架构的基石。正如许多人所说,NLP 正处于黄金时代,可以说 transformer 模型是一切的起点。
1. Transformer 架构
如前所述,需要是发明之母。传统的 seq-to-seq 模型在处理长文本时表现不佳。这意味着模型在处理输入序列的后半部分时,往往会忘记从输入序列的前半部分学到的知识。这种信息丢失是不可取的。
尽管像 LSTM 和 GRU 这样的门控架构通过丢弃在记忆重要信息的过程中无用的信息,在处理长期依赖性方面表现出了一些性能改进,但这仍然不够。世界需要更强大的东西,2015 年,Bahdanau 等人引入了“注意力机制”。它们与 RNN/LSTM 结合使用来模仿人类行为,以专注于有选择的事物而忽略其余的事物。 Bahdanau 建议为句子中的每个词分配相对重要性,以便模型关注重要词而忽略其余词。对于神经机器翻译任务,它是对编码器-解码器模型的巨大改进,很快,注意力机制的应用也被推广到其他任务中。
2. Transformer 时代
Transformer 模型完全基于注意力机制,也称为“自注意力”。这种架构在 2017 年的论文“Attention is All You Need”中被介绍给世界。它由一个编码器-解码器架构组成。

在高层次上,
编码器负责接受输入语句并将其转换为隐藏表示,并丢弃所有无用信息。 解码器接受这个隐藏表示并尝试生成目标句子。
在本文[1]中,我们将深入分析 Transformer 模型的编码器组件。在下一篇文章中,我们将详细介绍解码器组件。开始吧!
3. Encoder of Transformer
Transformer 的编码器块由一堆按顺序工作的 N 个编码器组成。一个编码器的输出是下一个编码器的输入,依此类推。最后一个编码器的输出是馈送到解码器块的输入句子的最终表示。

每个编码器块可以进一步拆分为两个组件,如下图所示。

让我们一一详细研究这些组件中的每一个,以了解编码器块是如何工作的。编码器块中的第一个组件是多头注意力,但在我们深入细节之前,让我们先了解一个基本概念:自注意力。
4. Self-Attention 机制
大家脑海中可能会浮现出第一个问题:attention和self-attention是不同的概念吗?是的,他们是。
传统上,如前一节所述,注意力机制是为神经机器翻译任务而存在的。所以本质上是应用注意力机制来映射源句和目标句。由于 seq-to-seq 模型逐个标记地执行翻译任务,注意力机制帮助我们在为目标句子生成标记 x 时识别源句子中的哪些标记需要更多关注。为此,它利用来自编码器和解码器的隐藏状态表示来计算注意力分数,并根据这些分数生成上下文向量作为解码器的输入。
回到自注意力,主要思想是在将源句子映射到自身的同时计算注意力分数。如果你有这样的句子,
★“The boy did not cross the *road* because *it* was too wide.”
”
我们人类很容易理解上面句子中“它”这个词指的是“路”,但是我们如何让我们的语言模型也理解这种关系呢?这就是 self-attention 发挥作用的地方!
在高层次上,将句子中的每个单词与句子中的每个其他单词进行比较,以量化关系并理解上下文。出于代表性的目的,您可以参考下图。
让我们详细看看这种自注意力是如何计算的(实际)。
为输入句子生成嵌入
找到所有单词的嵌入并将它们转换为输入矩阵。这些嵌入可以通过简单的标记化和单热编码生成,也可以通过 BERT 等嵌入算法生成。输入矩阵的维度将等于句子长度 x 嵌入维度。让我们将此输入矩阵称为 X 以供将来参考。
将输入矩阵转换为 Q、K 和 V
为了计算自注意力,我们需要将 X(输入矩阵)转换为三个新矩阵:
- Query (Q) - Key (K) - Value (V)
为了计算这三个矩阵,我们将随机初始化三个权重矩阵,即 Wq、Wk 和 Wv。输入矩阵 X 将与这些权重矩阵 Wq、Wk 和 Wv 相乘,分别获得 Q、K 和 V 的值。在此过程中将学习权重矩阵的最佳值,以获得更准确的 Q、K 和 V 值。
计算Q和K转置的点积
从上图可以看出,qi、ki、vi 代表了句子中第 i 个词的 Q、K、V 的值。

输出矩阵的第一行将使用点积告诉您 q1 表示的 word1 与句子中其余单词的关系。点积的值越高,单词越相关。直觉上为什么要计算这个点积,可以从信息检索的角度理解Q(query)和K(key)矩阵。所以在这里,
Q 或 Query = 您正在搜索的术语
K 或 Key = 您的搜索引擎中的一组关键字,Q 将与这些关键字进行比较和匹配。
缩放点积
与上一步一样,我们正在计算两个矩阵的点积,即执行乘法运算,该值可能会爆炸。为了确保不会发生这种情况并稳定梯度,我们将 Q 和 K-转置的点积除以嵌入维度 (dk) 的平方根。
使用 softmax 规范化值
使用 softmax 函数的归一化将导致值介于 0 和 1 之间。具有高尺度点积的单元格将进一步提高,而低值将减少,从而使匹配的词对之间的区别更加清晰。得到的输出矩阵可以看作是分数矩阵 S。
计算注意力矩阵Z
将值矩阵或V乘以从上一步获得的分数矩阵S来计算注意力矩阵Z。
为什么要乘法?
假设,Si = [0.9, 0.07, 0.03] 是句子中第 i 个词的得分矩阵值。该向量与 V 矩阵相乘以计算 Zi(第 i 个词的注意力矩阵)。
*Zi = [0.9 * V1 + 0.07 * V2 + 0.03 * V3]*
我们是否可以说为了理解第 i 个词的上下文,我们应该只关注词 1(即 V1),因为 90% 的注意力分数值来自 V1?我们可以清楚地定义重要的词,应该更加注意理解第 i 个词的上下文。
因此,我们可以得出结论,一个词在 Zi 表示中的贡献越高,这些词之间的关键性和相关性就越高。
现在我们知道如何计算自注意力矩阵,让我们了解多头注意力机制的概念。
5. Multi-head attention 机制
如果你的分数矩阵偏向于特定的词表示会发生什么?它会误导你的模型,结果不会像我们预期的那样准确。让我们看一个例子来更好地理解这一点。
S1: “All is well”
Z(well) = 0.6 * V(all) + 0.0 * v(is) + 0.4 * V(well)
S2: “The dog ate the food because it was hungry”
Z(it) = 0.0 * V(the) + 1.0 * V(dog) + 0.0 * V(ate) + …… + 0.0 * V(hungry)
在 S1 情况下,在计算 Z(well) 时,更重视 V(all)。它甚至超过了 V(well) 本身。无法保证这将有多准确。
在 S2 的情况下,在计算 Z(it) 时,所有重要性都赋予 V(dog),而其余单词的分数为 0.0,包括 V(it)。这看起来可以接受,因为“它”这个词是模棱两可的。将它更多地与另一个词相关联而不是与该词本身相关联是有意义的。这就是计算自我注意力的练习的全部目的。处理输入句子中歧义词的上下文。
换句话说,我们可以说,如果当前词是有歧义的,那么在计算自注意力时给予其他词更多的重要性是可以的,但在其他情况下,它可能会对模型产生误导。所以我们现在怎么办?
如果我们计算多个注意力矩阵而不是计算一个注意力矩阵并从中推导出最终的注意力矩阵会怎么样?
这正是多头注意力的全部意义所在!我们计算注意力矩阵 z1、z2、z3、…..、zm 的多个版本并将它们连接起来以得出最终的注意力矩阵。这样我们就可以对我们的注意力矩阵更有信心。
6. 位置编码
在 seq-to-seq 模型中,输入句子被逐字输入网络,这使得模型能够跟踪单词相对于其他单词的位置。
但在变压器模型中,我们采用不同的方法。它们不是逐字输入,而是并行输入,这有助于减少训练时间和学习长期依赖性。但是用这种方法,词序就丢失了。然而,要正确理解句子的意思,词序是极其重要的。为了克服这个问题,引入了一种称为“位置编码”(P)的新矩阵。
该矩阵 P 与输入矩阵 X 一起发送,以包含与词序相关的信息。由于显而易见的原因,X 和 P 矩阵的维数相同。
为了计算位置编码,使用下面给出的公式。

在上面的公式中,
pos = 单词在句子中的位置 d = 单词/标记嵌入的维度 i = 表示嵌入中的每个维度
在计算中,d 是固定的,但 pos 和 i 是变化的。如果 d=512,则 i ∈ [0, 255],因为我们取 2i。
使用一些视觉效果来解释这个概念。

上图显示了一个位置编码向量的示例以及不同的变量值。


上图显示了如果 i 不变且只有 pos 变化,PE(pos, 2i) 的值将如何变化。正如我们所知,正弦波是一种周期性函数,往往会在固定间隔后自行重复。我们可以看到 pos = 0 和 pos = 6 的编码向量是相同的。这是不可取的,因为我们希望对不同的 pos 值使用不同的位置编码向量。
这可以通过改变正弦波的频率来实现。

随着 i 值的变化,正弦波的频率也会发生变化,从而导致不同的波,从而导致每个位置编码向量的值不同。这正是我们想要实现的。
位置编码矩阵 (P) 添加到输入矩阵 (X) 并馈送到编码器。

编码器的下一个组件是前馈网络。
7. 前馈网络
编码器块中的这个子层是具有两个密集层和 ReLU 激活的经典神经网络。它接受来自多头注意力层的输入,对其执行一些非线性变换,最后生成上下文向量。全连接层负责考虑每个注意力头并从中学习相关信息。由于注意力向量彼此独立,因此可以以并行方式将它们传递给变换器网络。
8. Add & Norm
这是一个残差层,然后是层归一化。残差层确保在处理过程中不会丢失与子层输入相关的重要信息。而规范化层促进更快的模型训练并防止值发生重大变化。

在编码器中,有两个add & norm:
将多头注意力子层的输入连接到它的输出 将前馈网络子层的输入连接到它的输出
总结
至此,我们总结了编码器的内部工作。让我们快速回顾一下编码器使用的步骤:
生成输入句子的嵌入或标记化表示。这将是我们的输入矩阵 X。 生成位置嵌入以保留与输入句子的词序相关的信息,并将其添加到输入矩阵 X。 随机初始化三个矩阵:Wq、Wk 和 Wv,即查询、键和值的权重。这些权重将在 transformer 模型的训练过程中更新。 将输入矩阵 X 与 Wq、Wk 和 Wv 中的每一个相乘以生成 Q(查询)、K(键)和 V(值)矩阵。 计算 Q 和 K-transpose 的点积,通过将乘积除以 dk 的平方根或嵌入维度来缩放乘积,最后使用 softmax 函数对其进行归一化。 通过将 V 或值矩阵与 softmax 函数的输出相乘来计算注意力矩阵 Z。 将此注意力矩阵传递给前馈网络以执行非线性转换并生成上下文嵌入。
参考资料
Source: https://towardsdatascience.com/transformer-models-101-getting-started-part-1-b3a77ccfa14d
本文由 mdnice 多平台发布
相关文章:
Transformer 模型:入门详解(1)
动动发财的小手,点个赞吧! 简介 众所周知,transformer 架构是自然语言处理 (NLP) 领域的一项突破。它克服了 seq-to-seq 模型(如 RNN 等)无法捕获文本中的长期依赖性的局限性。事实证明,transformer 架构是…...

深入理解js中的new关键字
在js中我们经常会使用到new关键字,那我们在使用new关键字的时候,new到底做了什么呢?今天我们就来深入探究一下 1.初步使用 我们先来使用一下,这是一个正常操作 function Person() {this.name "John";}let person new…...
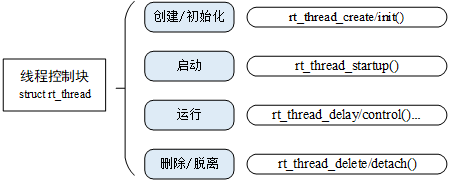
RT-Thread Nano(2) - 线程
参考:RT-Thread API参考手册: 线程管理 线程的分类:动态线程,静态线程 动态线程是系统自动从动态内存堆上分配栈空间的线程句柄(程序运行时再分配空间),静态线程是由用户分配栈空间与线程句柄(可以说是程序编译时已经分配好空间) 1.创建线程 创建一个动态线程 rt_thread_t …...
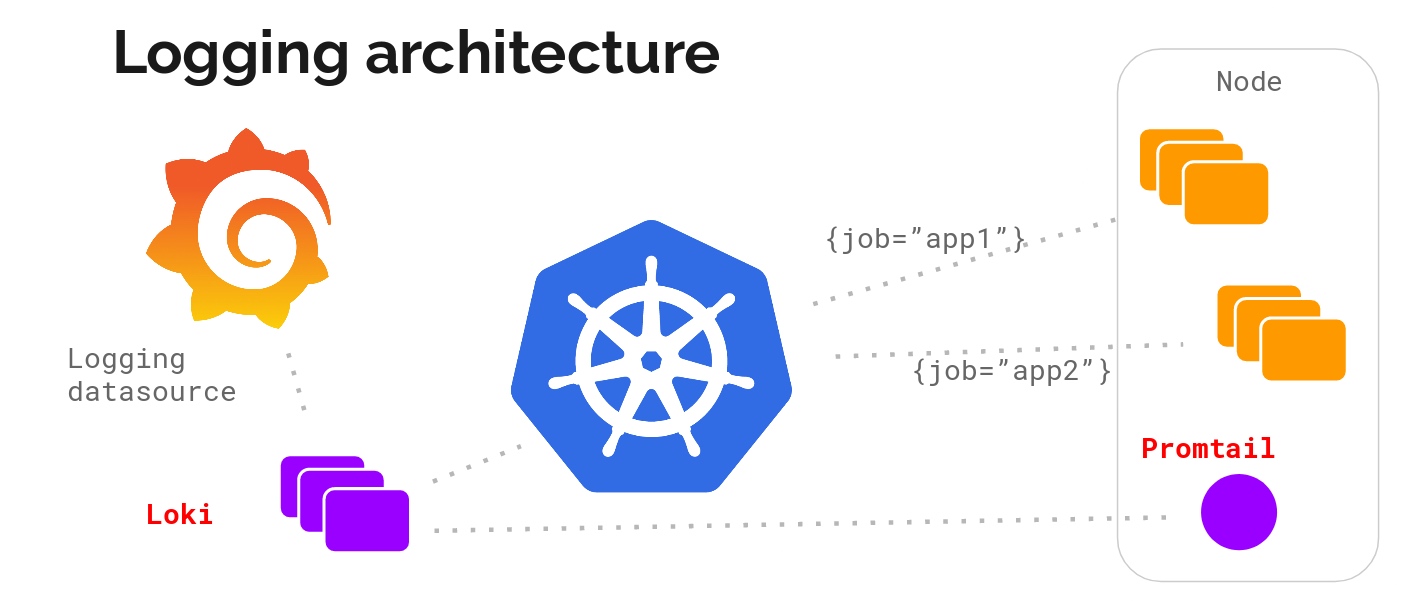
真香,Grafana开源Loki日志系统取代ELK?
一、Loki是什么? Loki是由Grafana Labs开源的一个水平可扩展、高可用性,多租户的日志聚合系统的日志聚合系统。它的设计初衷是为了解决在大规模分布式系统中,处理海量日志的问题。Loki采用了分布式的架构,并且与Prometheus、Graf…...

机器学习|多变量线性回归 | 吴恩达学习笔记
前文回顾:机器学习 | 线性回归(单变量) 目录 📚多维特征 📚多变量梯度下降 📚梯度下降法实践 🐇特征缩放 🐇学习率 📚特征和多项式回归 📚正规方程 &…...

高并发内存池
按照threadcache,centralcache,pagecache顺序所列 这里还需要一定的前期准备工作 首先是可以设计一个定长内存池 ObjectPool.h #pragma once #include<iostream> #include"Common.h" using std::cout; using std::endl; using std::…...

springboot mybatis-plus 对接 sqlserver 数据库 批处理的问题
问题: 在对接 sqlserver数据库的时候 主子表 保存的时候 子表批量保存 使用的 mybatis-plus提供的saveOrUpdateBatch 这个方法 但是 报错 报错内容为 : com.microsoft.sqlserver.jdbc.SQLServerException: 必须执行该语句才能获得结果。 框架版本 sprin…...
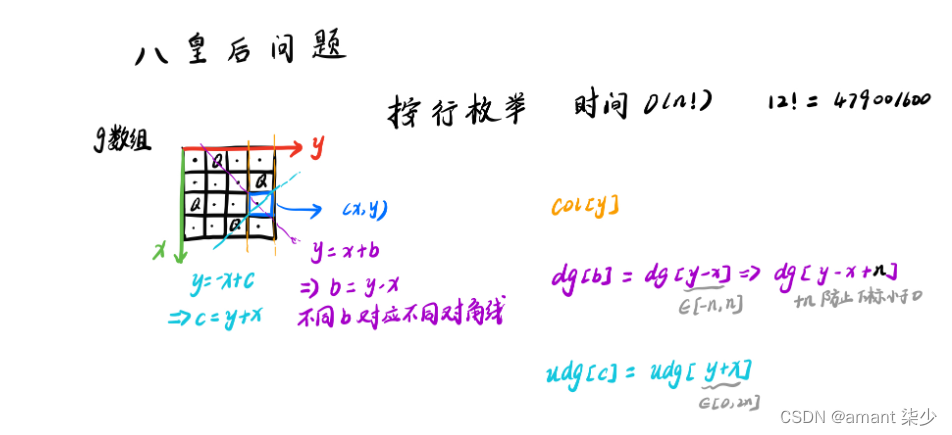
Acwing---843. n-皇后问题——DFS
n-皇后问题1.题目2.基本思想3.代码实现1.题目 n−皇后问题是指将 n 个皇后放在 nn 的国际象棋棋盘上,使得皇后不能相互攻击到,即任意两个皇后都不能处于同一行、同一列或同一斜线上。 现在给定整数 n,请你输出所有的满足条件的棋子摆法。 …...

Android事件分发机制
文章目录Android View事件分发机制:事件分发中的核心方法onTouchListener和onClickListener的优先级事件分发DOWN,MOVE,UP 事件分发CANCEL代码实践requestdisallowIntereptTouchEvent作用Android View事件分发机制: 事件分发中的核心方法 Android中事件…...

python版协同过滤算法图书管理系统
基于协同过滤算法的图书管理系统 一、简介(v信:1257309054) 本系统基于推荐算法给用户实现精准推荐图书。 根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然…...
Redis基础入门
文章目录前言一、redis是什么?二、安装步骤1.下载安装包2.安装三、Redis的数据类型redis是一种高级的key-value的存储系统,其中的key是字符串类型,尽可能满足如下几点:字符串(String)列表(List)集合(Set,不允许出现重复…...

【微服务】Feign实现远程调用和负载均衡
目录 1.什么是Feign 2 订单微服务集成Feign 2.1.引入依赖 2.2添加注解 2.3编写Feign的客户端 2.4修改OrderServiceImpl.java的远程调用方法 2.5重启订单服务,并验证 总结 1.什么是Feign Feign是Spring Cloud提供的⼀个声明式的伪Http客户端, 它…...

Windows使用QEMU搭建arm64 ubuntu 环境
1. 下载 QEMU: https://qemu.weilnetz.de/w64/ QEMU UEFI固件文件: https://releases.linaro.org/components/kernel/uefi-linaro/latest/release/qemu64/QEMU_EFI.fd arm64 Ubuntu镜像: http://cdimage.ubuntu.com/releases/20.04.3/rel…...

NodeJS安装
一、简介Node.js是一个让JavaScript运行在服务端的开发平台,Node.js不是一种独立的语言,简单的说 Node.js 就是运行在服务端的 JavaScript。npm其实是Node.js的包管理工具(package manager),类似与 maven。二、安装步骤…...

Gin 优雅打印请求与回包内容
文章目录1.Gin 的 Middleware2.使用 Middleware 打印请求与回包内容3.多次读取请求 Body 的问题4.多次读取响应 Body 的问题5.小结参考文献在开发 Web 应用程序时,难免不会遇到功能或性能等问题。为了快速定位问题,需要打印请求和响应的内容。本文将介绍…...

关于k8s中ETCD集群备份灾难恢复的一些笔记
写在前面 集群电源不稳定,或者节点动不动就 宕机,一定要做好备份,ETCD 的快照文件很容易受影响损坏。重置了很多次集群,才认识到备份的重要博文内容涉及 etcd 运维基础知识了解静态 Pod 方式 etcd 集群灾备与恢复 Demo定时备份的任务编写二进…...

【设计模式之美 设计原则与思想:设计原则】19 | 理论五:控制反转、依赖反转、依赖注入,这三者有何区别和联系?
关于 SOLID 原则,我们已经学过单一职责、开闭、里式替换、接口隔离这四个原则。今天,我们再来学习最后一个原则:依赖反转原则。在前面几节课中,我们讲到,单一职责原则和开闭原则的原理比较简单,但是&#x…...

2023年全国最新高校辅导员精选真题及答案13
百分百题库提供高校辅导员考试试题、辅导员考试预测题、高校辅导员考试真题、辅导员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 一、单选题 131.下列不属于我国国土空间具有的特点的是() A.水资…...

【XXL-JOB】XXL-JOB定时处理视频转码
【XXL-JOB】XXL-JOB定时处理视频转码 文章目录【XXL-JOB】XXL-JOB定时处理视频转码1. 准备工作1.1 高级配置1.2 分片广播2. 需求分析2.1 作业分片方案2.2 保证任务不重复执行2.2.1 保证幂等性3. 视频处理业务流程3.1 添加待处理任务3.2 查询待处理任务3.3 更新任务状态3.4 工具…...

optuna用于pytorch的轻量级调参场景和grid search的自定义设计
文章目录0. 背景:why optuna0.1 插播一个简单的grid search0.2 参考1. Optuna1.1 a basic demo与部分参数释义1.2 random的问题1.3 Objective方法类2. Optuna与grid search4. optuna的剪枝prune5. optuna与可视化6. 未完待续0. 背景:why optuna 小模型参…...

永磁同步电机参数辨识:EKF算法的奇妙之旅
卡尔曼滤波EKF算法,针对于永磁同步电机的电阻、电感等参数的辨识,辨识速度快,效果好,适合入门童鞋参考学习:本商品 包含以下内容: (1)采用SVPWM矢量控制; (2&…...

轨道桥梁与列车这对CP,到底怎么互相伤害
车桥耦合动力学模型,轮轨耦合动力学模型,采用二自由度列车模型,可以改为FF梁SF梁,采用德国轨道谱,采用积分算法,可以输出桥梁任意位置的响应。玩轨道桥梁动力学的老铁们都知道,车桥耦合这玩意儿…...

罗技鼠标宏压枪脚本终极指南:3步实现绝地求生精准射击
罗技鼠标宏压枪脚本终极指南:3步实现绝地求生精准射击 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为绝地求生中枪口乱跳而烦…...

OpenClaw局域网访问配置
根据OpenClaw最新官方文档(截至2026年3月),以下是更新后的局域网访问配置指南,整合了网络架构、安全加固和自动化配对等新特性:一、核心配置命令(基于新版网关协议)启用LAN多接口监听 使用新参数…...

8.3ES-OAS-ERP-电子政务-企业信息化
一、专家系统 00:00 定义:基于知识的专家系统是人工智能的重要分支,其能力来源于专家知识,通过知识表示和推理方法实现应用。与传统程序区别: 属于AI范畴,解决半结构化/非结构化问题模拟专家推理而非问题本…...

Zemax优化别再乱点‘锤子’了!一个光学新手的真实踩坑与避坑指南
Zemax优化实战:从新手误区到高效操作的进阶指南 刚接触Zemax的光学设计师们,往往会被软件中那个神秘的"锤形优化"按钮所吸引——看似简单的点击就能自动改善设计,这种诱惑难以抗拒。但很快就会发现,盲目依赖这个功能可能…...

OpenClaw+nanobot备份方案:自动化配置与数据同步
OpenClawnanobot备份方案:自动化配置与数据同步 1. 为什么需要备份nanobot环境 上周我的开发机突然硬盘故障,导致辛苦配置了两个月的nanobot环境全部丢失。那一刻我才深刻意识到,对于这种高度定制化的AI自动化系统,没有备份方案…...

FastAdmin二次开发指南:如何基于这套开源CMS源码定制你的专属内容模型?
FastAdmin二次开发实战:从零构建自定义内容模型 在开源CMS领域,FastAdmin以其基于ThinkPHP的优雅架构和丰富的功能模块,成为众多开发者快速构建后台管理系统的首选。但真正体现其价值的,往往是在面对个性化业务需求时的二次开发能…...

GreptimeDB高可用架构深度解析:5大核心策略保障业务连续性
GreptimeDB高可用架构深度解析:5大核心策略保障业务连续性 【免费下载链接】greptimedb An open-source, cloud-native, distributed time-series database with PromQL/SQL/Python supported. 项目地址: https://gitcode.com/GitHub_Trending/gr/greptimedb …...

基于PyTorch Geometric的交通网络流量预测与优化
基于PyTorch Geometric的交通网络流量预测与优化 【免费下载链接】pytorch_geometric Graph Neural Network Library for PyTorch 项目地址: https://gitcode.com/GitHub_Trending/py/pytorch_geometric 问题定义:破解城市交通网络的复杂性挑战 交通网络的图…...