【AIGC】Stable Diffusion的采样器入门

在 Stable Diffusion 中,采样器(Sampler)是指用于生成图像的一种技术或方法,它决定了模型如何从潜在空间中抽样并生成图像。采样器在生成图像的过程中起着重要作用,影响着生成图像的多样性、质量和创造性。以下是对 Stable Diffusion 采样器的详细解释:
潜在空间抽样:
采样器负责从潜在空间中抽样,并将这些样本输入到生成器中以生成图像。潜在空间是一个高维向量空间,其中每个向量代表一个潜在的图像表示。通过从潜在空间中抽样不同的向量,采样器可以生成不同的图像样本。
采样策略:
采样器决定了从潜在空间中抽样的方式和策略。不同的采样策略可能会导致生成图像的多样性和质量不同。例如,随机采样器可以随机地从潜在空间中抽取样本,而插值采样器可以在潜在空间中进行线性插值以生成连续变化的图像。
温度参数:
一些采样器可能会引入温度参数,用于控制采样过程中的随机性。通过调整温度参数,可以影响生成图像的多样性和创造性。较高的温度值会增加随机性,导致生成更多样化的图像,而较低的温度值则会减少随机性,使生成图像更加稳定。
采样方法:
采样器还可以采用不同的方法来选择从潜在空间中抽样的样本。常见的方法包括随机采样、插值采样、聚类采样等。每种方法都有其优缺点,适用于不同的应用场景和需求。

Stable Diffusion 的 Web UI 提供了大量的采样器供用户选择,这些采样器基于不同的算法、数学模型或生成模型,具有不同的特点:
Euler A 和 Euler:这两种采样器基于 Euler 方法,是一种简单而直接的数值积分方法。它们在计算速度上较快,但可能会产生较大的误差,导致生成图像的质量较低。
Heun:Heun 采样器是一种改进的数值积分方法,具有较高的数值精度和稳定性。它通常能够生成较高质量、较清晰的图像,但可能稍微增加计算成本。
DDIM:DDIM(Denoising Diffusion Implicit Model)采样器基于去噪扩散过程,通过迭代去噪来生成逼真的图像。它可能具有较高的图像质量和清晰度,但计算成本较高。
DPM++ 2M Karras 和 DPM++ SDE Karras:这些采样器基于 Karras 或 SDE 模型,通常用于生成高质量、逼真的图像。它们可能结合了复杂的生成模型和算法,适用于要求较高的图像生成任务。
DPM++ 2M SDE Exponential:这是基于指数型随机微分方程(SDE)的采样器,用于控制图像生成过程中的噪声和多样性。它可能提供了一种不同的生成策略,可用于生成具有特定特征的图像。
PLMS:PLMS(Power-Law Mean Squared)采样器是一种改进的隐式模型,用于生成图像。它可能具有更好的数值稳定性和收敛性,适用于生成质量较高的图像。
UniPC:UniPC 采样器是一种基于单个预测器的采样器,可能具有较低的计算成本和较快的生成速度,但可能会牺牲一些图像质量。
Restart:Restart 采样器可能使用了一种特殊的重新启动机制,用于提高生成过程的稳定性和收敛性。
DPM adaptive:这是一种自适应的采样器,可能根据生成过程中的反馈信息动态调整参数和策略,以优化生成结果。
##############################################################################################
经典ODE求解器
Euler采样器:欧拉采样方法。
Heun采样器:欧拉的一个更准确但是较慢的版本。
LMS采样器:线性多步法,与欧拉采样器速度相仿,但是更准确。
祖先采样器
名称中带有a标识的采样器表示这一类采样器是祖先采样器。这一类采样器在每个采样步骤中都会向图像添加噪声,采样结果具有一定的随机性。
Euler a
DPM2 a
DPM++ 2S a
DPM++ 2S a Karras
由于这一类采样器的特性,图像不会收敛。因此为了保证重现性,例如在通过多帧组合构建动画时,应当尽量避免采用具有随机性的采样器。需要注意的是,部分采样器的名字中虽然没有明确标识属于祖先采样器,但也属于随机采样器。如果希望生成的图像具有细微的变化,推荐使用variation seed进行调整。
DDIM与PLMS(已过时,不再使用)
DDIM(去噪扩散隐式模型)和PLMS(伪线性多步方法)是伴随Stable Diffusion v1提出的采样方法,DDIM也是最早被用于扩散模型的采样器。PLMS是DDIM的一种更快的替代方案。当前这两种采样方法都不再广泛使用。
DPM与DPM++
DPM(扩散概率模型求解器)这一系列的采样器于2022年发布,代表了具有类似体系结构的求解器系列。
由于DPM会自适应调整步长,不能保证在约定的采样步骤内完成任务,整体速度可能会比较慢。对Tag的利用率较高,在使用时建议适当放大采样的步骤数以获得较好的效果。
DPM++是对DPM的改进,DPM2采用二阶方法,其结果更准确,但是相应的也会更慢一些。
UniPC
UniPC(统一预测校正器),一种可以在5-10个步骤中实现高质量图像生成的方法。
采样器的选择推荐使用网上另一个大佬的结论
1、如果只是想得到一些较为简单的结果,选用欧拉(Eular)或者Heun,并可适当减少Heun的步骤数以减少时间
2、对于侧重于速度、融合、新颖且质量不错的结果,建议选择:
DPM++ 2M Karras, Step Range:20-30
UniPc, Step Range: 20-30
3、期望得到高质量的图像,且不关心图像是否收敛:
DPM ++ SDE Karras, Step Range:8-12
DDIM, Step Range:10-15
4、如果期望得到稳定、可重现的图像,避免采用任何祖先采样器
图像收敛通常指的是生成的图像在训练或优化过程中逐渐变得稳定和一致,不再发生显著变化的过程。在图像生成任务中,收敛是指生成模型学习到的图像分布逼近真实图像分布的过程。在 Stable Diffusion或其他图像生成模型中,图像收敛通常意味着生成的图像质量和逼真度逐渐提高,同时图像的多样性和噪声减少。这可能是通过调整模型参数、增加训练数据、改进生成算法等方式实现的。当生成的图像在训练过程中达到稳定状态,不再发生显著的变化时,我们可以说模型已经收敛。 图像收敛是图像生成任务中的一个重要目标,它表示模型学习到了数据的重要特征和分布规律,并能够生成与真实数据相似的图像。在使用 Stable Diffusion 或其他图像生成模型时,了解和监控图像的收敛过程是评估模型性能和训练进度的重要指标之一。
相关文章:
【AIGC】Stable Diffusion的采样器入门
在 Stable Diffusion 中,采样器(Sampler)是指用于生成图像的一种技术或方法,它决定了模型如何从潜在空间中抽样并生成图像。采样器在生成图像的过程中起着重要作用,影响着生成图像的多样性、质量和创造性。以下是对 St…...
【Python】通过conda安装Python的IDE
背景 系统:win11 软件:anaconda Navigator 问题现象:①使用Navigator安装jupyter notebook以及Spyder IDE 一直转圈。②然后进入anaconda prompt执行conda install jupyter notebook一直卡在Solving environment/-\。 类似问题: …...

基于HTML5实现动态烟花秀效果(含音效和文字)实战
目录 前言 一、烟花秀效果功能分解 1、功能分解 2、界面分解 二、HTML功能实现 1、html界面设计 2、背景音乐和燃放触发 3、燃放控制 4、对联展示 5、脚本引用即文本展示 三、脚本调用及实现 1、烟花燃放 2、燃放响应 3、烟花canvas创建 4、燃放声音控制 5、实际…...

「数据结构」栈和队列
栈 栈的基本概念 定义 栈是只允许在一端进行插入或删除操作的线性表栈顶:线性表允许进行插入删除的那一端栈底:固定的,不允许进行插入和删除的另一端空栈:不含任何元素特点:后进先出(LIFO) 基…...

【机器学习笔记】5 机器学习实践
数据集划分 子集划分 训练集(Training Set):帮助我们训练模型,简单的说就是通过训练集的数据让我们确定拟合曲线的参数。 验证集(Validation Set):也叫做开发集( Dev Set …...

C++ //练习 7.5 在你的Person类中提供一些操作使其能够返回姓名和住址。这些函数是否应该是const的呢?解释原因。
C Primer(第5版) 练习 7.5 练习 7.5 在你的Person类中提供一些操作使其能够返回姓名和住址。这些函数是否应该是const的呢?解释原因。 环境:Linux Ubuntu(云服务器) 工具:vim 解释 姓名大概…...
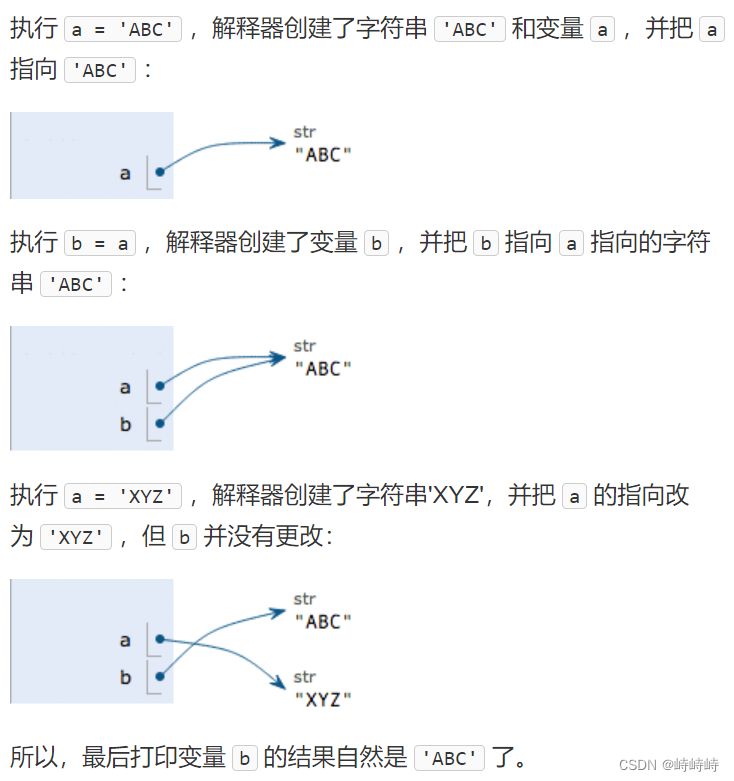
python系统学习Day2
section3 python Foudamentals part one:data types and variables 数据类型:整数、浮点数、字符串、布尔值、空值 #整型,没有大小限制 >>>9 / 3 #3.0 >>>10 // 3 #3 地板除 >>>10 % 3 #1 取余#浮点型ÿ…...

学习笔记——ENM模拟
学习笔记——ENM模拟 文章目录 前言一、文献一1. 材料与方法1.1. 大致概念1.2. 生态模型的构建1.2.1. 数据来源:1.2.2. 数据处理:1.2.3. 模型参数优化: 1.3. 适生情况预测1.3.1. 预测模型构建1.3.2. 适生区划分 1.4. 模型的评估与验证 2. 结果…...

数值类型的运算方式总结
提纲1:常见的位运算使用场景 提纲2:整数类型运算时的类型溢出问题,产生原因以及解决办法 提纲3:浮点类型运算时的精度丢失问题,产生原因以及解决办法 数值类型(6种)分为: 整型&…...

【Redis快速入门】Redis三种集群搭建配置(主从集群、哨兵集群、分片集群)
个人名片: 🐼作者简介:一名大三在校生,喜欢AI编程🎋 🐻❄️个人主页🥇:落798. 🐼个人WeChat:hmmwx53 🕊️系列专栏:🖼️…...

[嵌入式系统-14]:常见实时嵌入式操作系统比较:RT-Thread、uC/OS-II和FreeRTOS、Linux
目录 一、实时嵌入式操作系统 1.1 概述 1.2 什么“实时” 1.3 什么是硬实时和软实时 1.4 什么是嵌入式 1.5 什么操作系统 二、常见重量级操作系统 三、常见轻量级嵌入式操作系统 3.1 概述 3.2 FreeRTOS 3.3 uC/OS-II 3.4 RT-Thread 3.5 RT-Thread、uC/OS-II、Free…...
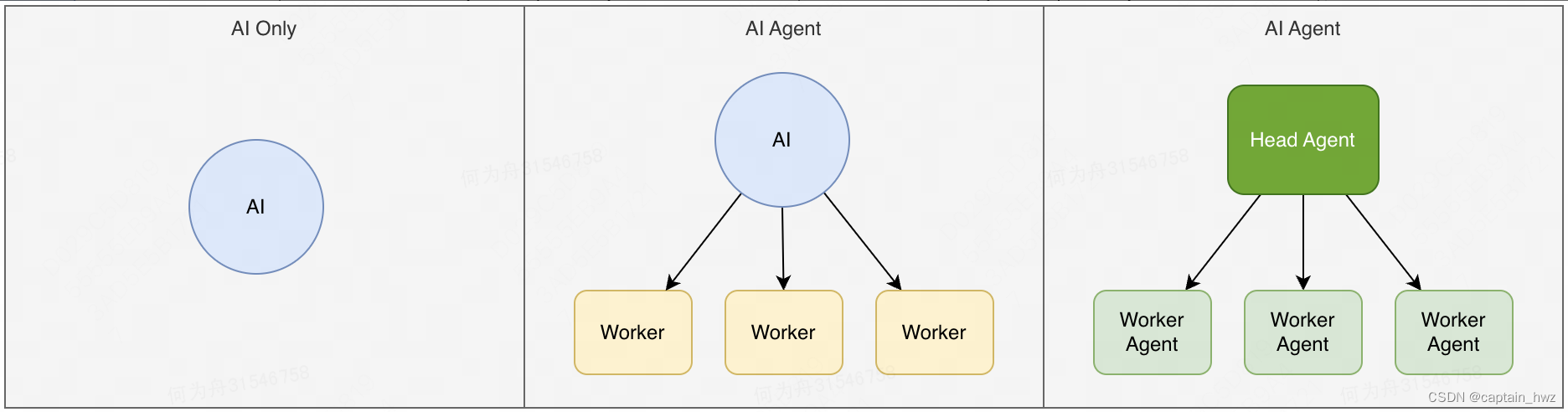
基于AI Agent探讨:安全领域下的AI应用范式
先说观点:关于AI应用,通常都会聊准召。但在安全等模糊标准的场景下,事实上不存在准召的定义。因此,AI的目标应该是尽可能的“像人”。而想要评价有多“像人”,就先需要将人的工作数字化。而AI Agent是能够将数字化、自…...
Stable Diffusion 模型下载:ToonYou(平涂卡通)
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十...
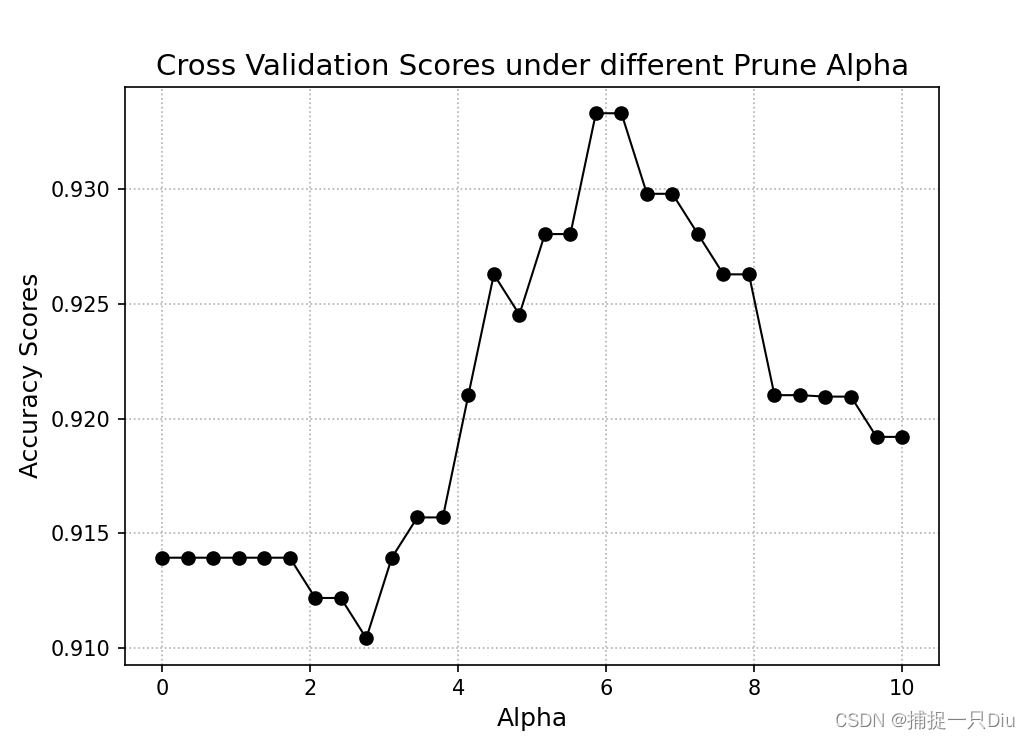
机器学习:分类决策树(Python)
一、各种熵的计算 entropy_utils.py import numpy as np # 数值计算 import math # 标量数据的计算class EntropyUtils:"""决策树中各种熵的计算,包括信息熵、信息增益、信息增益率、基尼指数。统一要求:按照信息增益最大、信息增益率…...

红队打靶练习:HACK ME PLEASE: 1
信息收集 1、arp ┌──(root㉿ru)-[~/kali] └─# arp-scan -l Interface: eth0, type: EN10MB, MAC: 00:0c:29:69:c7:bf, IPv4: 192.168.61.128 Starting arp-scan 1.10.0 with 256 hosts (https://github.com/royhills/arp-scan) 192.168.61.2 00:50:56:f0:df:20 …...
《VulnHub》GoldenEye:1
title: 《VulnHub》GoldenEye:1 date: 2024-02-16 14:53:49 updated: 2024-02-16 15:08:49 categories: WriteUp:Cyber-Range excerpt: 主机发现、目标信息扫描、源码 js 文件泄露敏感信息、hydra 爆破邮件服务(pop3)、邮件泄露敏…...
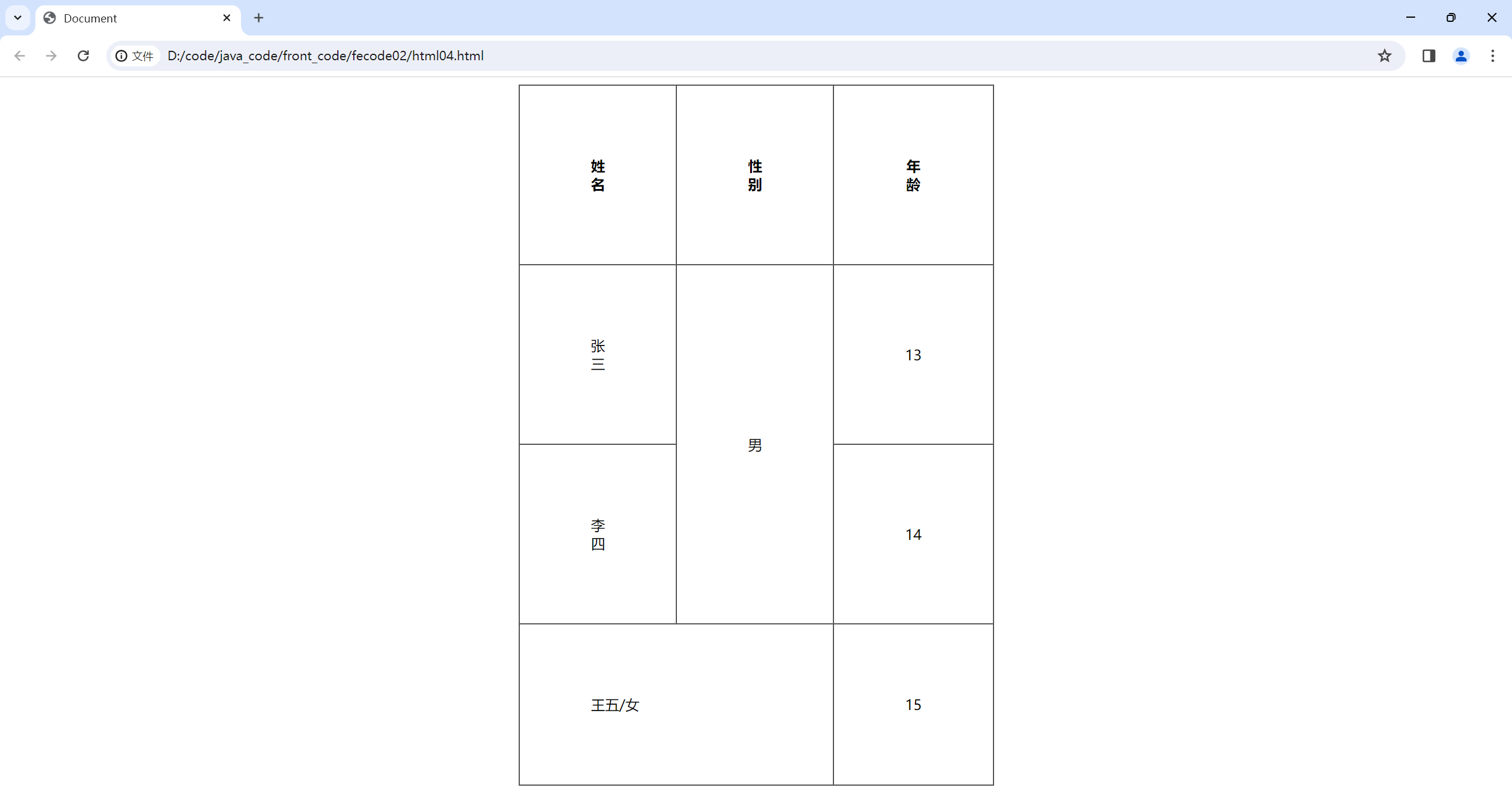
html的表格标签
html的表格标签 table标签:表示整个表格tr:表示表格的一行td:表示一个单元格th:表示表头单元格.会居中加粗thead:表格的头部区域 (注意和th区分,范围是比th要大的).tbody:表格得到主体区域. table包含tr , tr包含td或者th. 表格标签有一些属性,可以用于设置大小边…...
2022省赛真题:展开你的扇子)
蓝桥杯(Web大学组)2022省赛真题:展开你的扇子
思路: transform-origin: center bottom;使盒子旋转时,以底部的中心为坐标原点(题目已给出) 对每个盒子使用transform: rotate();实现旋转 笔记: 设置悬浮旋转时, #box div:hover #item6{ } 为什…...
复习基础知识1
局部变量 写程序时,程序员经常会用到局部变量 汇编中寄存器、栈,可写区段、堆,函数的局部变量该存在哪里呢? 注意:局部变量有易失性 一旦函数返回,则所有局部变量会失效。 考虑到这种特性,人们…...

java8-用流收集数据-6
本章内容口用co1lectors类创建和使用收集器 口将数据流归约为一个值 口汇总:归约的特殊情况 数据分组和分区口 口 开发自己的自定义收集器 我们在前一章中学到,流可以用类似于数据库的操作帮助你处理集合。你可以把Java8的流看作花哨又懒惰的数据集迭代器。它们…...

避开IAP跳转的坑:深入STM32的bin文件,搞懂PC指针和中断向量表那点事
避开IAP跳转的坑:深入STM32的bin文件,搞懂PC指针和中断向量表那点事 在嵌入式开发中,IAP(In-Application Programming)功能是实现设备固件远程升级的关键技术。然而,许多工程师在实现Bootloader跳转到App时…...

【Nginx】Nginx 自定义错误页面全解:从 404 到 502 的用户体验与故障隔离实战
Nginx 自定义错误页面全解:从 404 到 502 的用户体验与故障隔离实战 本文面向已部署过简单 Nginx 服务、了解反向代理概念,但尚未系统掌握其错误处理机制与用户友好降级策略的中高级工程师。我们将彻底拆解 error_page 指令的工作原理、作用域继承、内部重定向行为,揭示为何…...

Ti AWR2243实测:毫米波雷达通道积累,选相干还是非相干?一个实验讲清楚
Ti AWR2243毫米波雷达通道积累策略:工程实践中的深度抉择 毫米波雷达在现代自动驾驶系统中扮演着关键角色,而通道积累策略的选择直接影响着目标检测的精度与系统实时性。面对192个虚拟通道的海量数据,工程师们常常陷入两难:是追求…...

全网最全短临降水预报方向科研辅导
...

避坑指南:SAP BP客户维护cl_md_bp_maintain的那些“坑”与最佳实践
SAP BP客户维护实战:cl_md_bp_maintain深度避坑手册 当ABAP开发人员第一次接触cl_md_bp_maintain类时,往往会被其强大的业务伙伴(Business Partner)管理功能所吸引,但随之而来的是一系列令人头疼的"坑"。本文将从实际项目经验出发&…...

长期使用Taotoken Token Plan套餐的成本控制体会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐的成本控制体会 1. 从按需计费到套餐订阅的转变 在开始使用Taotoken平台时,我和团队…...

从零构建智能体工作流引擎:多Agent系统架构与工程实践
1. 项目概述:从零构建一个智能体工作流引擎最近在GitHub上看到一个挺有意思的项目,叫strands-agents/agent-builder。光看名字,你可能会觉得这又是一个“AI智能体”的玩具项目,但实际深入进去,你会发现它试图解决的是一…...

命令行媒体管理工具amem:本地化素材归档与自动化实践
1. 项目概述:一个被低估的本地化媒体管理工具最近在整理个人数字资产时,我遇到了一个老生常谈但又无比棘手的问题:如何高效、优雅地管理那些散落在硬盘各个角落的短视频、图片和音频文件?无论是手机拍摄的生活片段,还是…...

车载以太网之要火系列 - 第49篇郭大侠学SOME/IP:人说SOME/IP虽好,对手已在路上跑
写在开篇蓉儿又挖坑上回说到,郭靖学完了SOME/IP的十八般武艺——报文头、Service ID、Instance ID、Method、Event、Field、SD的Offer/Find/Subscribe三驾马车。郭靖合上笔记本,信心满满:“蓉儿,SOME/IP我算是学透了!服…...

5.【Python】Python3 运算符
第一步:分析与整理 运算符1. 什么是运算符? 运算符用于执行算术、比较、逻辑等操作。操作数是参与运算的值。例如 4 5 9 中,4 和 5 是操作数, 是运算符。 Python 支持以下运算符类型: 算术运算符比较(关系…...