TENT: FULLY TEST-TIME ADAPTATION BY ENTROPY MINIMIZATION--论文笔记
论文笔记
资料
1.代码地址
https://github.com/DequanWang/tent
2.论文地址
https://arxiv.org/abs/2006.10726
1论文摘要的翻译
在这种完全测试时适应的情况下,模型只有测试数据和自身参数。我们建议通过测试熵最小化(tent)进行适应:我们通过预测熵来优化模型的置信度。我们的方法会估算归一化统计量,并优化通道仿射变换,以便在每个批次上进行在线更新。Tent 降低了损坏的 ImageNet 和 CIFAR-10/100 图像分类的泛化误差,并达到了最先进的误差。在从 SVHN 到 MNIST/MNIST-M/USPS 的数字识别、从 GTA 到 Cityscapes 的语义分割以及 VisDA-C 基准上,Tent 处理了无源域适应。这些结果是在不改变训练的情况下,通过一次测试时间优化取得的。
2论文的创新点
2.1
强调了只有目标数据而没有源数据的完全测试时适应的设置。为了强调推理过程中的实际适应性,我们对离线和在线更新进行基准测试
2.2
我们将熵作为自适应目标,并提出了一种测试时间熵最小化方案(Tent),通过降低测试数据上模型预测的熵来减少泛化误差
2.3
对于对的鲁棒性,tent在ImageNet-C上达到44.0%的错误率,优于鲁棒训练(50.2%)和测试时间标准化的强基线(49.9%)
2.4
对于领域自适应,tent能够在线和无源地适应数字分类和语义分割,甚至可以与使用源数据并进行更多优化的方法相媲美
3 论文方法的概述
熵与误差有关,置信度更高的预测总体上更正确,下图为在熵低的数据集上预测具有更低的误差。所以确定性可以作为测试过程中的监督。

这里发现熵与corruption造成的偏移有关,因为corruption越多,熵就越大,随着corruption程度的增加,熵 与 图像分类的loss有很强的相关性。

为了最小化熵,tent通过估计统计量和逐批优化仿射参数对目标数据的推理进行归一化和转换。这种选择的低维、通道特征调制在测试期间是有效的,即使是在线更新。tent不限制或改变模型训练:它独立于给定模型参数的源数据。如果模型可以运行,就可以进行调整。最重要的是,tent不仅有效地减少了熵,还减少了误差。
本文的研究结果评估了图像分类中对corruption的泛化,对数字识别的域移位,以及对语义分割的模拟到真实移位。对于具有更多数据和优化的上下文,我们评估了给定标记源数据的鲁棒训练、领域适应和自监督学习方法。在给定目标数据的情况下,Tent可以实现更小的错误,并且在ImageNet-C基准测试的基础上进行了改进。分析实验支持我们的熵目标,检查对数据量的敏感性和适应参数的选择,并支持跨架构的普遍性
Adaptation处理从源到目标的泛化的任务。在源数据和标签 x s x^s xs, y s y^s ys上训练参数为θ的模型 f θ ( x ) f_θ(x) fθ(x)在移位的目标数据 x t x^t xt上测试时可能无法泛化。
我们的tent只需要模型 f θ f_θ fθ和未标记的目标数据 x t x^t xt在推理过程中进行自适应。
下图是总结的 适应设置、所需数据和损失类型。

我们在测试期间优化模型,通过调节其特征来最小化其预测的熵。我们把我们的方法tent称为测试熵。下图概述了tent的方法过程。

3.1 ENTROPY OBJECTIVE
我们的TTA的目标 L ( x t ) L(x^t) L(xt)是最小化模型预测的熵 H ( y ) H(y) H(y)。
3.2 MODULATION PARAMETERS
模型参数 θ θ θ是测试时间优化的自然选择,这些是对train-time entropy最小化的先验工作的选择然而, θ θ θ是我们设置中训练/源数据的唯一表示,改变 θ θ θ可能会导致模型偏离其训练。此外, f f f可能是非线性的, θ θ θ可能是高维的,这使得优化对test-time的使用过于敏感和低效。

为了稳定性和效率,我们只更新线性(尺度和移位)和低维(通道方向)的feature modulations。上图显示了显示了modulations的两个步骤
- 通过统计数据进行规范化和通过参数进行转换。归一化将输入 x x x集中并标准化为 ¯ x = ( x − µ ) / σ ¯x = (x−µ)/σ ¯x=(x−µ)/σ,通过其平均值µ和标准差σ。
- 变换通过尺度 γ γ γ和位移 β β β的仿射参数将 ¯ x ¯x ¯x转换为输出 x 0 = γ ¯ x + β x0 = γ¯x + β x0=γ¯x+β。注意,统计量 µ µ µ, σ σ σ是从数据中估计的,而参数 γ γ γ, β β β是通过损失优化的。
为了实现,我们只需重新利用源模型的规范化层。我们在测试过程中更新了所有层和通道的归一化统计量和仿射参数。
3.3 ALGORITHM
- Initialization
优化器收集源模型中每个归一化层 l l l和通道 k k k的仿射变换参数 γ l , k , β l , k {γl,k, βl,k} γl,k,βl,k。其余参数 θ θ θ\ γ l , k , β l , k {γl,k, βl,k} γl,k,βl,k是固定的。源数据的归一化统计 µ l , k , σ l , k {µl,k, σl,k} µl,k,σl,k将被丢弃。 - Iteration
每一步更新一批数据的规范化统计信息和转换参数。在向前传递期间,依次估计每层的归一化统计量。在反向传递过程中,通过预测熵 ∇ H ( y ) ∇H(y) ∇H(y)的梯度来更新变换参数 γ 、 β γ、β γ、β。注意,转换更新遵循当前批处理的预测,因此它只影响下一个批处理(除非重复forward操作)。每个额外的计算点只需要一个梯度,所以我们默认使用这个方案来提高效率。 - Termination
对于在线适配,不需要终止,只要有测试数据,迭代就会继续。对于离线自适应,首先更新模型,然后重复推理
当然,适应可以通过多个时代的更新来继续。
4 论文实验
我们评估了tent在CIFAR-10/CIFAR-100和ImageNet上的corruption鲁棒性,以及SVHN对MNIST/MNIST- m /USPS的数字自适应的领域适应性。
数据集
CIFAR-10、CIFAR-100、ImageNet上的损坏鲁棒性,
MNIST、MNIST- m 、USPS
基础模型
对于corruption,我们使用残差网络, CIFAR10/100上有26层(R-26), ImageNet上有50层(R-50)。
对于domain adaption,我们使用R-26架构。为了公平比较,每个实验条件下的所有方法都使用相同的架构。
训练超参数
我们根据源模型的训练超参数对调制参数 γ , β γ, β γ,β进行了优化,并且变化很小。在ImageNet上,我们使用SGD进行动量优化;在其他数据集上,我们由Adam优化(Kingma & Ba, 2015)。我们降低批大小(BatchSize, BS)以减少用于推理的内存使用,然后通过相同的因素降低学习率(LearningRate, LR)以进行补偿(Goyal等人,2017)。在ImageNet上,我们设置BS = 64, LR = 0.00025,在其他数据集上,我们设置BS = 128, LR = 0.001。我们通过随机打乱和跨方法共享顺序来控制排序。
基线任务
- Source将训练好的分类器应用于测试数据而不进行自适应;
- 对抗性域自适应(RG)反转域分类器在源和目标上的梯度,以优化域不变表示
- 自监督域自适应(UDA-SS)在源和目标上联合训练自监督旋转和定位任务,以优化共享表示
- 测试时训练(TTT)在源上对监督任务和自监督任务进行联合训练,然后在测试过程中对目标上的自监督任务进行持续训练
- 测试时间归一化(test-time normalization, BN)在测试过程中更新目标数据上的批归一化统计
- 伪标记(PL)调整置信度阈值,将超过阈值的预测分配为标签,然后在测试之前针对这些伪标签优化模型
4.1 稳健性 TO CORRUPTIONS
Tent用更少的数据和计算提高了性能。下表报告了在最严重的corruptions程度下不同腐败类型的平均错误。在CIFAR-10/100-C上,比较了所有方法,包括那些需要跨域或损失联合训练的方法,同时考虑到这些数据集的方便大小。这里的适应是离线的,以便与离线基线进行公平比较。Tent改进了全测试时间自适应基线(BN, PL),也改进了域自适应(RG, UDA-SS)和测试时间训练(TTT)方法,这些方法需要在源和目标上进行多次优化。
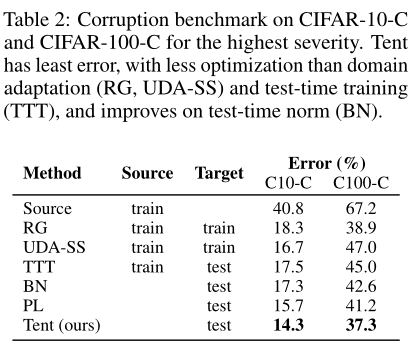
下图绘制了在ImageNet-C上每种损坏类型在损坏级别上的平均误差。

4.2 SOURCE-FREE DOMAIN ADAPTATION
Tent适应无源目标。表3报告了域适应和完测试时间适应方法的目标误差。测试时间归一化(Test-time normalization, BN)的性能略有提高,而对抗性领域自适应(arial domain adaptation, RG)和自监督领域自适应(self-supervised domain adaptive, UDA-SS)在源和目标联合训练下的性能有较大提高。Tent总是比源模型和BN具有更低的误差,并且在2/3的情况下达到最低的误差,即使只有一个历元并且不使用源数据。

4.3 分析
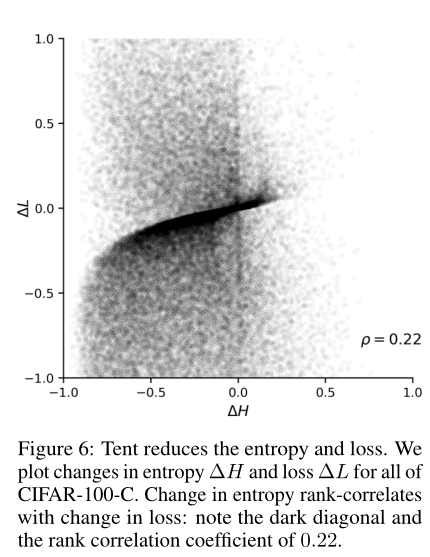
==Tent减少了熵和误差。==下图验证了tent确实减少了熵和任务损失(softmax cross-entropy)。我们绘制了CIFAR-100-C上所有75种损坏类型/级别组合的熵和损失的变化。两个轴都通过预测的最大熵(log 100)进行归一化,并裁剪为±1。大多数点经过自适应后熵值和误差都较低。
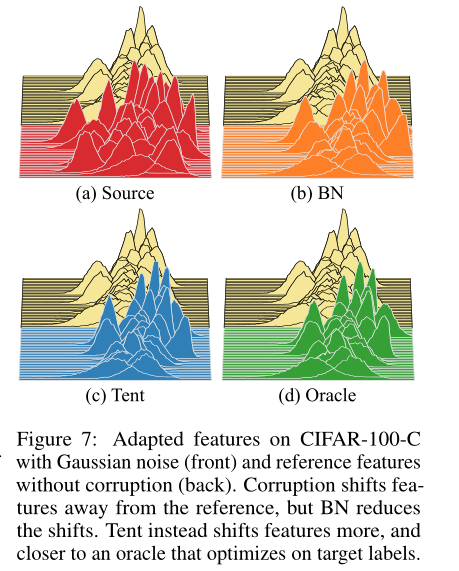
帐篷适应不同的架构。原则上帐篷是建筑不可知论者。为了衡量其在实践中的通用性,我们评估了基于自关注(SAN)和平衡求解(MDEQ) 的新架构在CIFAR-100-C上的损坏鲁棒性。下表显示,在与卷积残差网络相同的设置下,tent减少了误差。

5总结
Tent通过最小化测试时间熵来减少移位数据的泛化误差。在最小化熵的过程中,模型根据自己预测的反馈进行自我调整。这才是真正的自我监督的自我提升。这种类型的自我监督完全由被监督任务定义,不像代理任务旨在从数据中提取更多的监督,但它仍然显著地减少了错误。然而,由于corruption 和其他变化造成的错误仍然存在,因此需要更多的适应。接下来的步骤应该追求测试时间适应更多和更困难类型的转移,在更一般的参数,并通过更有效和高效的损失。
Shifts
Tent减少了各种转换的错误,包括图像损坏,数字外观的简单变化以及模拟到真实的差异。
Parameters
Tent通过规范化和转换来调整模型,但模型的大部分保持固定。test-time adaption可以更新更多的模型,但问题是要确定既具有表现力又可靠的参数,这可能与损失的选择相互作用。
Losses
Tent使熵最小化。对于更强的adaption,对于一般的但偶然的测试时间优化是否有有效的损失?熵在任务中是通用的,但在范围上是有限的。它需要批量优化,并且不能一次在一个点上偶然更新。
相关文章:
TENT: FULLY TEST-TIME ADAPTATION BY ENTROPY MINIMIZATION--论文笔记
论文笔记 资料 1.代码地址 https://github.com/DequanWang/tent 2.论文地址 https://arxiv.org/abs/2006.10726 1论文摘要的翻译 在这种完全测试时适应的情况下,模型只有测试数据和自身参数。我们建议通过测试熵最小化(tent)进行适应&…...

Java期末复习指南(1):知识点总结+思维导图,考试速成!
🔖面向对象 📖 Java作为面向对象的编程语言,我们首先必须要了解类和对象的概念,本章的所有内容和知识都是围绕类和对象展开的! ▐ 思维导图1 ▐ 类和对象的概念 • 简单来说,类就是对具有相同特征的一类事…...
OpenMV学习笔记1——IDE安装与起步
目录 一、OpenMV IDE下载 二、OpenMV界面 三、Hello World! 四、将代码烧录到OpenMV实现脱机运行 五、插SD卡(为什么买的时候没送?) 一、OpenMV IDE下载 浏览器搜索OpenMV官网,进入后点击“立即下载”࿰…...
C++设计模式|结构型 适配器模式
1.什么是适配器模式? 可以将⼀个类的接⼝转换成客户希望的另⼀个接⼝,主要⽬的是 充当两个不同接⼝之间的桥梁,使得原本接⼝不兼容的类能够⼀起⼯作。 2. 适配器模式的组成 (1)接口类,给客户端调用&…...
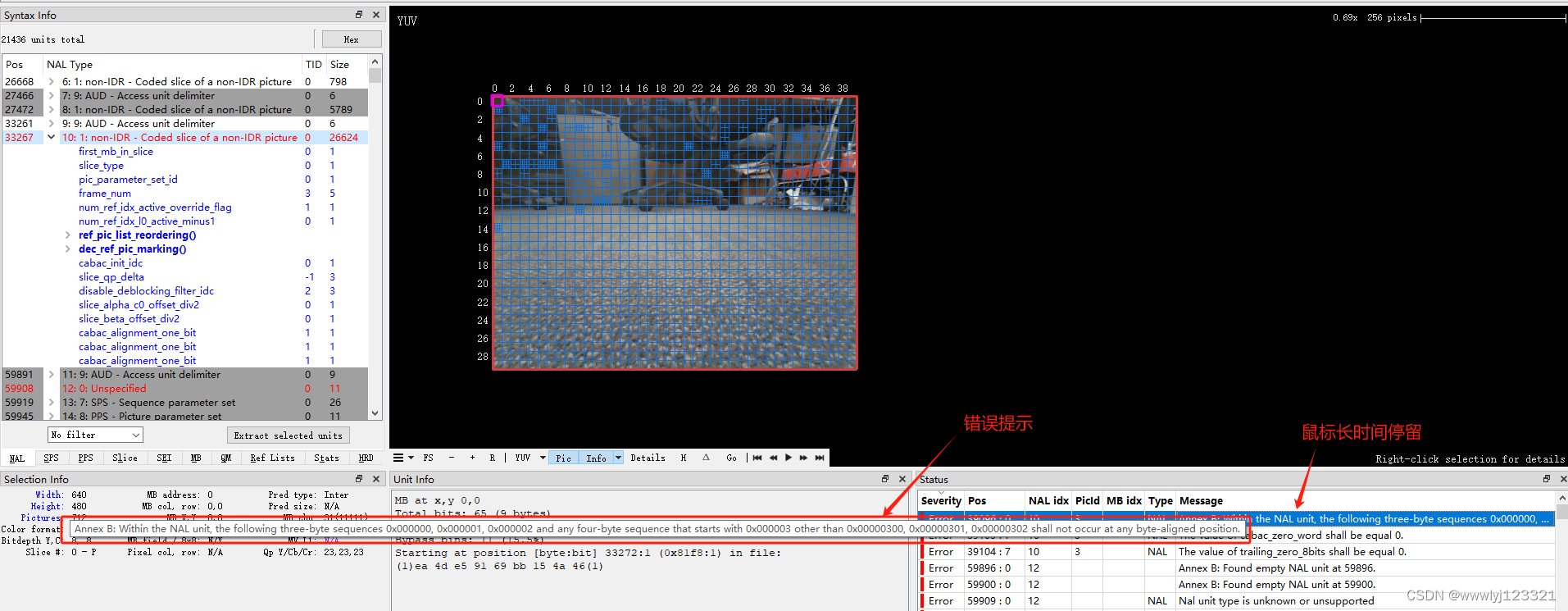
视频码流分析工具
一、VQ Analyzer 在线使用说明: https://vicuesoft.com/vq-analyzer/userguide/ ref: Video Analyzer and Streaming Tester Software – VQ Analyzer HEVC 分析工具 - 懒人李冰 推荐一个开源且跨平台的免费码流分析软件YUView - 知乎...
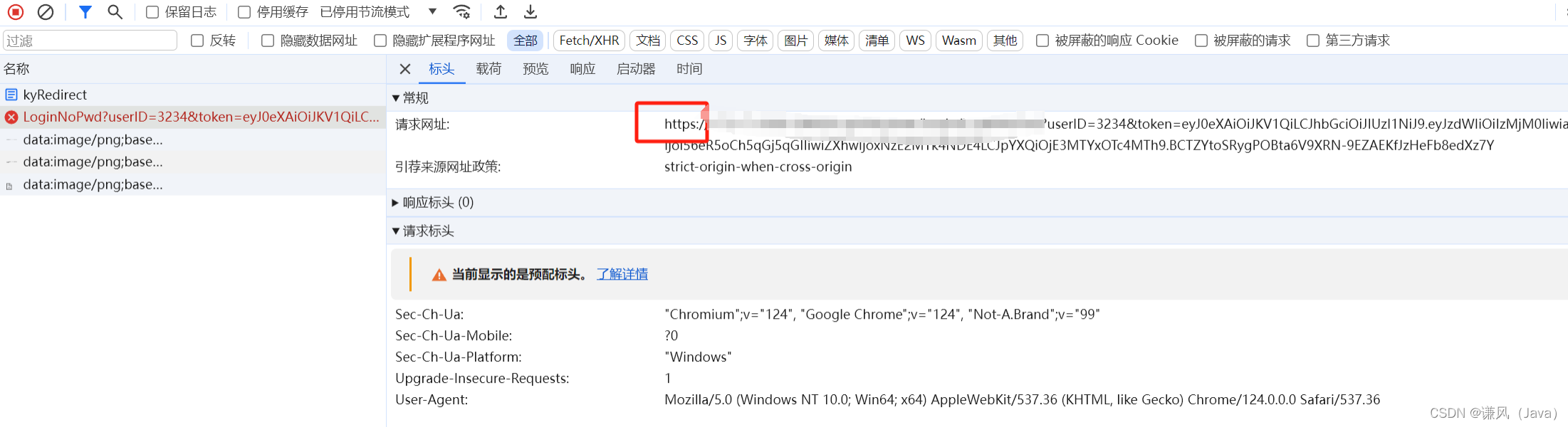
记一次重定向问题(浏览器安全)解决
近期做单点登陆功能,本身应该是一个很简单的功能,却发生了意向不到的问题…让我们看下: 首先第三方给出的地址需要通过JWT框架获取token拼接后跳转,我这边为了方便首选肯定是考虑用response.sendRedirect(url),但是做好…...

【传知代码】transformer-论文复现
文章目录 概述原理介绍模型架构 核心逻辑嵌入表示层注意力层前馈层残差连接和层归一化编码器和解码器结构 数据处理和模型训练环境配置小结 本文涉及的源码可从transforme该文章下方附件获取 概述 Transformer模型是由谷歌在2017年提出并首先应用于机器翻译的神经网络模型结构…...

大模型日报|今日必读的 13 篇大模型论文
大家好,今日必读的大模型论文来啦! 1.MIT新研究:并非所有语言模型特征都是线性的 最近的研究提出了线性表征假说:语言模型通过操作激活空间中概念(“特征”)的一维表征来执行计算。与此相反,来…...

Python 魂斗罗的音效和动漫效果
一、实现游戏音效 音效是游戏中不可或缺的一部分,它可以为游戏增添氛围和趣味性。在 Pygame 中,我们可以使用 pygame.mixer 模块来播放音效。下面是一个简单的示例代码,演示如何在游戏中播放音效: import pygamepygame.mixer.init…...

Raylib 绘制自定义字体的一种套路
Raylib 绘制自定义字体是真的难搞。我的需求是程序可以加载多种自定义字体,英文中文的都有。 我调试了很久成功了! 很有用的参考,建议先看一遍: 瞿华:raylib绘制中文内容 个人笔记|Raylib 的字体使用 - …...

C++学习笔记(21)——继承
目录 1. 继承的概念及定义1.1 继承的概念1.2 继承定义1.2.1 定义格式1.2.2 继承关系和访问限定符1.2.3 继承基类成员访问方式的变化 继承的概念总结: 2. 基类和派生类对象赋值转换3.继承中的作用域4.派生类的默认成员函数知识点:派生类中6个默认成员函数…...

DOS学习-目录与文件应用操作经典案例-more
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一.前言 二.使用 三.案例 一.前言 DOS系统的more命令是一个用于查看文本文件内容的工具。…...

android 在 Activity 的 onCreate 中获取View 的宽高
view 的 post 执行时,首先会判断view 的 mAttatchInfo 是否为空,如果不为空,则将Runnable 添加到mAttachInfo.handler 的 UI线程MessageQueue 中;如果为空,则先将Runnable 暂存在view 的类为HandlerActionQueue的mRunQ…...

Pod进阶——资源限制以及探针检查
目录 一、资源限制 1、资源限制定义: 2、资源限制request和limit资源约束 3、Pod和容器的资源请求和限制 4、官方文档示例 5、CPU资源单位 6、内存资源单位 7、资源限制实例 ①编写yaml资源配置清单 ②释放内存(node节点,以node01为…...
XSS---DOM破坏
文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结 一.什么是DOM破坏 在HTML中,如果使用一些特定的属性名(如id或name)给DOM元素命名,这些属性会在全局作用域中创建同名的全局变量,指向对…...

2024电工杯数学建模B 题:大学生平衡膳食食谱的优化设计
背景: 大学时代是学知识长身体的重要阶段, 同时也是良好饮食习惯形成的重要时期。这一特 定年龄段的年轻人, 不仅身体发育需要有充足的能量和各种营养素, 而且繁重的脑力劳动和 较大量的体育锻炼也需要消耗大量的能源物质。 大学生…...
)
LeetCode 1542.找出最长的超赞子字符串:前缀异或和(位运算)
【LetMeFly】1542.找出最长的超赞子字符串:前缀异或和(位运算) 力扣题目链接:https://leetcode.cn/problems/find-longest-awesome-substring/ 给你一个字符串 s 。请返回 s 中最长的 超赞子字符串 的长度。 「超赞子字符串」需…...

LLM企业应用落地场景中的问题概览
三个问题 AI思维快速工具:需要对接LLM的API、控制幻觉、管理知识库。POC验证四个难点 私有化部署的环境:包括网络和服务器环境。交互友好意想不到的情况方向选择:让客户做目标和方向的选择问题 一、RAG 多跳问题 通常发生在报告编写的数据整理环节,比如要从一堆报表中找…...
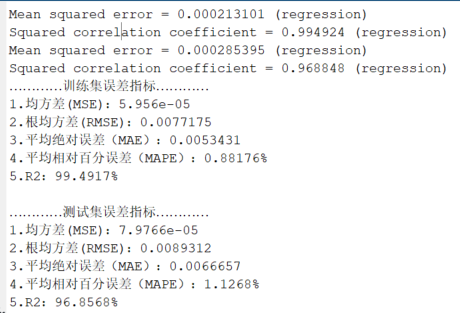
基于灰狼优化算法优化支持向量机(GWO-SVM)时序预测
代码原理及流程 基于灰狼优化算法优化支持向量机(GWO-SVM)的时序预测代码的原理和流程如下: 1. **数据准备**:准备时序预测的数据集,将数据集按照时间顺序划分为训练集和测试集。 2. **初始化灰狼群体和SVM模型参数…...

C++中获取int最大与最小值
不知道大家有没有遇到过这种要求:“返回值必须是int,如果整数数超过 32 位有符号整数范围 [−2^31, 2^31 − 1] ,需要截断这个整数,使其保持在这个范围内。例如,小于 −2^31 的整数应该被固定为 −2^31 ,大…...
)
Vue3项目里SignalR怎么用?一个聊天室Demo带你从配置到上线(.NET 6 + Vue 3)
Vue3与SignalR实战:构建高互动聊天室的全栈指南 引言 在当今追求实时交互体验的Web应用中,传统的HTTP请求-响应模式已无法满足即时通讯、实时通知等场景需求。SignalR作为ASP.NET Core生态中的实时通信库,通过自动选择最佳传输协议࿰…...
)
从V2L到V2G:深度解析双向OBC的HIL测试如何模拟真实用车场景(含CANoe SmartCharging配置)
从露营供电到电网互动:双向OBC的HIL测试实战指南 清晨的山谷里,一辆新能源车静静停驻在营地旁。车主取出便携式电烤盘,将充电枪插入车辆交流充电口,几分钟后烤盘上的牛排开始滋滋作响——这看似简单的场景背后,是双向O…...

解决RK3568上QML卡顿的实战:从怀疑供应商到亲手编译带OpenGL ES2的Qt 5.14.2
RK3568嵌入式开发实战:破解QML卡顿之谜与OpenGL ES2编译全解析 当你在RK3568开发板上运行精心设计的QML界面时,却发现动画效果卡顿得像幻灯片播放——这种体验足以让任何嵌入式开发者抓狂。本文记录了一位开发者从发现问题到最终解决的完整历程ÿ…...

macOS用户必看:vscode-icons安装与使用完整手册
macOS用户必看:vscode-icons安装与使用完整手册 【免费下载链接】vscode-icons Custom Visual Studio Code Icons 项目地址: https://gitcode.com/gh_mirrors/vsc/vscode-icons 想要为你的Visual Studio Code换上个性化图标吗?vscode-icons项目提…...

vue3+python基于Django框架的铁路博物馆展览系统的设计与实现67350649
目录同行可拿货,招校园代理 ,本人源头供货商项目背景技术栈核心功能模块关键技术实现部署方案项目亮点项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目背景 …...

Unity WebGL适配微信小游戏全链路指南
1. 为什么Unity WebGL不能直接扔进微信小游戏?——从“能跑”到“能上线”的认知断层很多人第一次尝试把Unity项目导出WebGL再塞进微信小游戏时,都会经历一个相似的困惑:本地浏览器里好好的3D场景,一放进微信开发者工具就白屏、报…...

解锁洛可可美学密码:用Midjourney V6实现蓬巴杜夫人级繁复纹样、柔光质感与粉金配色的5步精准控制法
更多请点击: https://intelliparadigm.com 第一章:洛可可美学的数字转译本质与Midjourney V6语义解码机制 洛可可美学以繁复卷曲的曲线、轻盈的不对称构图、粉金柔色调与自然母题(如贝壳、藤蔓、云朵)为标志,其核心并…...

创业团队如何利用Taotoken统一管理多个AI模型API以控制开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用Taotoken统一管理多个AI模型API以控制开发成本 对于资源有限的创业团队而言,在业务开发中引入大模型能…...

向量化智能矩阵系统的语义坍塌:当10万条内容同时找“相似“,为什么你的数据库扛不住?
摘要:智能矩阵系统从"关键词匹配"进化到"语义匹配"之后,遇到了一个被严重低估的性能瓶颈——向量检索的语义坍塌。本文从向量数据库原理、ANN近似最近邻算法、HNSW图索引、向量量化技术四个底层技术出发,拆解向量化智能矩…...

蒙古语AI语音落地难?ElevenLabs最新v3.2模型支持率提升至98.7%,但90%开发者忽略这5个编码陷阱
更多请点击: https://intelliparadigm.com 第一章:蒙古语AI语音落地的现实困境与技术拐点 蒙古语作为中国少数民族语言中使用人口较多、语法高度黏着、音系复杂的阿尔泰语系代表,其AI语音技术长期受限于低资源特性——标准语音数据集不足50小…...