spark第三章:工程化代码
系列文章目录
spark第一章:环境安装
spark第二章:sparkcore实例
spark第三章:工程化代码
文章目录
- 系列文章目录
- 前言
- 一、三层架构
- 二、拆分WordCount
- 1.三层拆分
- 2.代码抽取
- 总结
前言
我们上一次博客,完成了一些案例的练习,现在我要要进行一些结构上的完善,上一次的案例中,代码的耦合性非常高,想要修改就十分复杂,而且有很多代码都在重复使用,我们想要把一些重复的代码抽取出来,进而完成解耦合的操作,提高代码的复用。
一、三层架构
大数据的三层架构其中包括
controller(控制层):负责调度各模块
service(服务层):存放逻辑代码
dao(持久层):进行文件交互
现在我们分别给各层创建一个包
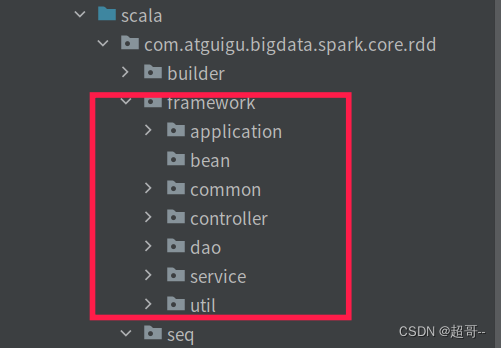
解释一下其中几个
application:项目的启动文件
bean:存放实体类
common:存放这个项目的通用代码
util:存放通用代码(所有项目均可)
二、拆分WordCount
万物皆可WordCount我们就以上次的WordCount为例操作。放一下源代码
object WordCount {def main(args: Array[String]): Unit = {// 创建 Spark 运行配置对象val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")// 创建 Spark 上下文环境对象(连接对象)val sc : SparkContext = new SparkContext(sparkConf)// 读取文件 获取一行一行的数据val lines: RDD[String] = sc.textFile("datas/word.txt")// 将一行数据进行拆分val words: RDD[String] = lines.flatMap(_.split(" "))// 将数据根据单次进行分组,便于统计val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))// 对分组后的数据进行转换val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)// 打印输出val array: Array[(String, Int)] = wordToSum.collect()array.foreach(println)sc.stop()}}
1.三层拆分
在进行数据抽取之前,我们先进行简单的三层架构拆分
记得把包名路径换成自己的
WordCountDao.scala
负责文件交互,也就是第一步的读取文件
package com.atguigu.bigdata.spark.core.rdd.framework1.daoimport com.atguigu.bigdata.spark.core.rdd.framework1.application.WordCountApplication.scclass WordCountDao {def readFile(path:String) ={sc.textFile(path)}
}
WordCountService.scala
负责逻辑运算
package com.atguigu.bigdata.spark.core.rdd.framework1.serviceimport com.atguigu.bigdata.spark.core.rdd.framework1.dao.WordCountDaoimport org.apache.spark.rdd.RDDclass WordCountService {private val wordCountDao =new WordCountDao()def dataAnalysis(): Array[(String, Int)] ={val lines: RDD[String] =wordCountDao.readFile("datas/word.txt")val words: RDD[String] = lines.flatMap(_.split(" "))val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)val array: Array[(String, Int)] = wordToSum.collect()array}
}
WordCountController.scala
负责调度项目
package com.atguigu.bigdata.spark.core.rdd.framework1.controllerimport com.atguigu.bigdata.spark.core.rdd.framework1.service.WordCountServiceclass WordCountController {private val wordCountService =new WordCountService()def dispath(): Unit ={val array=wordCountService.dataAnalysis()array.foreach(println)}
}
WordCountApplication.scala
main方法启动项目
package com.atguigu.bigdata.spark.core.rdd.framework1.applicationimport com.atguigu.bigdata.spark.core.rdd.framework1.controller.WordCountController
import org.apache.spark.{SparkConf, SparkContext}object WordCountApplication extends App {val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")val sc : SparkContext = new SparkContext(sparkConf)val controller = new WordCountController()controller.dispath()sc.stop()
}
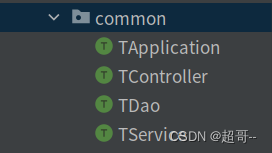
2.代码抽取
接下来我们把一些常用或者会重复实用的代码抽取出来。
创建四个Train,用来抽取四个文件
TApplication.scala
其中通用代码为环境创建
package com.atguigu.bigdata.spark.core.rdd.framework.commonimport com.atguigu.bigdata.spark.core.rdd.framework.util.EnvUtil
import org.apache.spark.{SparkConf, SparkContext}trait TApplication {def start(master: String="local[*]", app: String="Application")(op: =>Unit): Unit ={val sparkConf: SparkConf = new SparkConf().setMaster(master).setAppName(app)val sc : SparkContext = new SparkContext(sparkConf)EnvUtil.put(sc)try {op}catch {case ex=>println(ex.getMessage)}sc.stop()EnvUtil.clear()}
}TController.scala
定义调度Train之后由Controller进行重写
package com.atguigu.bigdata.spark.core.rdd.framework.commontrait TController {def dispatch():Unit
}
TDao.scala
WordCount通用读取,路径为参数
package com.atguigu.bigdata.spark.core.rdd.framework.commonimport com.atguigu.bigdata.spark.core.rdd.framework.util.EnvUtil
import org.apache.spark.rdd.RDDtrait TDao {def readFile(path:String): RDD[String] ={EnvUtil.take().textFile(path)}
}TService.scala
和Controller类似,由Service重写
package com.atguigu.bigdata.spark.core.rdd.framework.commontrait TService {def dataAnalysis():Any
}
定义环境,确保所有类都能访问sc线程
EnvUtil.scala
package com.atguigu.bigdata.spark.core.rdd.framework.utilimport org.apache.spark.SparkContextobject EnvUtil {private val scLocal =new ThreadLocal[SparkContext]()def put(sc:SparkContext): Unit ={scLocal.set(sc)}def take(): SparkContext = {scLocal.get()}def clear(): Unit ={scLocal.remove()}
}
修改三层架构
WordCountApplication.scala
package com.atguigu.bigdata.spark.core.rdd.framework.applicationimport com.atguigu.bigdata.spark.core.rdd.framework.common.TApplication
import com.atguigu.bigdata.spark.core.rdd.framework.controller.WordCountControllerobject WordCountApplication extends App with TApplication{start(){val controller = new WordCountController()controller.dispatch()}}WordCountController.scala
package com.atguigu.bigdata.spark.core.rdd.framework.controllerimport com.atguigu.bigdata.spark.core.rdd.framework.common.TController
import com.atguigu.bigdata.spark.core.rdd.framework.service.WordCountServiceclass WordCountController extends TController{private val WordCountService = new WordCountService()def dispatch(): Unit ={val array: Array[(String, Int)] = WordCountService.dataAnalysis()array.foreach(println)}
}
WordCountDao.scala
package com.atguigu.bigdata.spark.core.rdd.framework.daoimport com.atguigu.bigdata.spark.core.rdd.framework.common.TDaoclass WordCountDao extends TDao{}WordCountService.scala
package com.atguigu.bigdata.spark.core.rdd.framework.serviceimport com.atguigu.bigdata.spark.core.rdd.framework.common.TService
import com.atguigu.bigdata.spark.core.rdd.framework.dao.WordCountDao
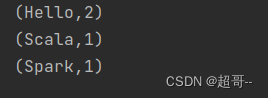
import org.apache.spark.rdd.RDDclass WordCountService extends TService{private val wordCountDao=new WordCountDao()def dataAnalysis(): Array[(String, Int)] = {val lines: RDD[String] = wordCountDao.readFile("datas/word.txt")val words: RDD[String] = lines.flatMap(_.split(" "))val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)val array: Array[(String, Int)] = wordToSum.collect()array}}再次运行
总结
对spark项目代码的规范就到这里,确实有点复杂,我也不知道说清楚没有。
相关文章:
spark第三章:工程化代码
系列文章目录 spark第一章:环境安装 spark第二章:sparkcore实例 spark第三章:工程化代码 文章目录系列文章目录前言一、三层架构二、拆分WordCount1.三层拆分2.代码抽取总结前言 我们上一次博客,完成了一些案例的练习࿰…...

Vue实战【封装一个简单的列表组件,实现增删改查】
文章目录🌟前言🌟table组件封装🌟父组件(展示表格的页面)🌟控制台查看父子组件通信是否成功🌟Vue2父子组件传递参数🌟写在最后🌟JSON包里写函数,关注博主不迷…...
微前端(无界)
前言:微前端已经是一个非常成熟的领域了,但开发者不管采用哪个现有方案,在适配成本、样式隔离、运行性能、页面白屏、子应用通信、子应用保活、多应用激活、vite 框架支持、应用共享等用户核心诉求都或存在问题,或无法提供支持。本…...
强烈推荐:0基础入门网安必备《网络安全知识图谱》
蚁景网安学院一直专注于网安实战技能培养,提供全方位的网安安全学习解决方案。我们集聚专业网安技术大佬资源,倾力打造了这本更全面更系统的“网络安全知识图谱”,让大家在网络安全学习路上不迷茫。 在这份网安技能地图册里,我们对…...

网络技术与应用概论(上)——“计算机网络”
各位CSDN的uu们你们好呀,今天,小雅兰的内容依旧是计算机网络的一些知识点噢,下面,让我们进入计算机网络的世界吧 网络内涵 网络特征 网络定义 互联网发展过程 从ARPA网络到Internet 从低速互联网到高速互联网 从数据结构到统一网…...
JAVASE/封装、继承、多态
博客制作不易,欢迎各位点赞👍收藏⭐关注前言在学习面向对象编程语言时,封装、继承、多态则是我们必须学习和使用的三大特征。本文通过举例,说明了该三大特征的基本权限特点。一、访问限定符范围private默认权限protectedpublic同一…...
SpringBoot ElasticSearch 【SpringBoot系列16】
SpringCloud 大型系列课程正在制作中,欢迎大家关注与提意见。 程序员每天的CV 与 板砖,也要知其所以然,本系列课程可以帮助初学者学习 SpringBooot 项目开发 与 SpringCloud 微服务系列项目开发 elasticsearch是一款非常强大的开源搜索引擎&a…...

Virtual box磁盘大小调整操作
Virtual box磁盘大小调整操作环境说明思路操作1、挂载要压缩的硬盘到 ~/data2、填充 0 文件3、删除 全是0空文件4、虚拟机关机5、在windows环境下用VBoxManage.exe 进行压缩硬盘加大环境说明 主机 windows 虚拟机 ubuntu 分配了 80G 的硬盘,现在已经占用 80 G 了。…...

MySQL注入秘籍【上篇】
MySQL注入秘籍【上篇】1.数据库敏感信息常用语句2.联合(UNION)查询注入3.报错注入原理常见报错注入函数1.数据库敏感信息常用语句 获取数据库版本信息 select version(); select innodb_version;获取当前用户 select user();获取当前数据库 select database();数…...
简单三步解决动态规划难题,记好这三步,动态规划就不难
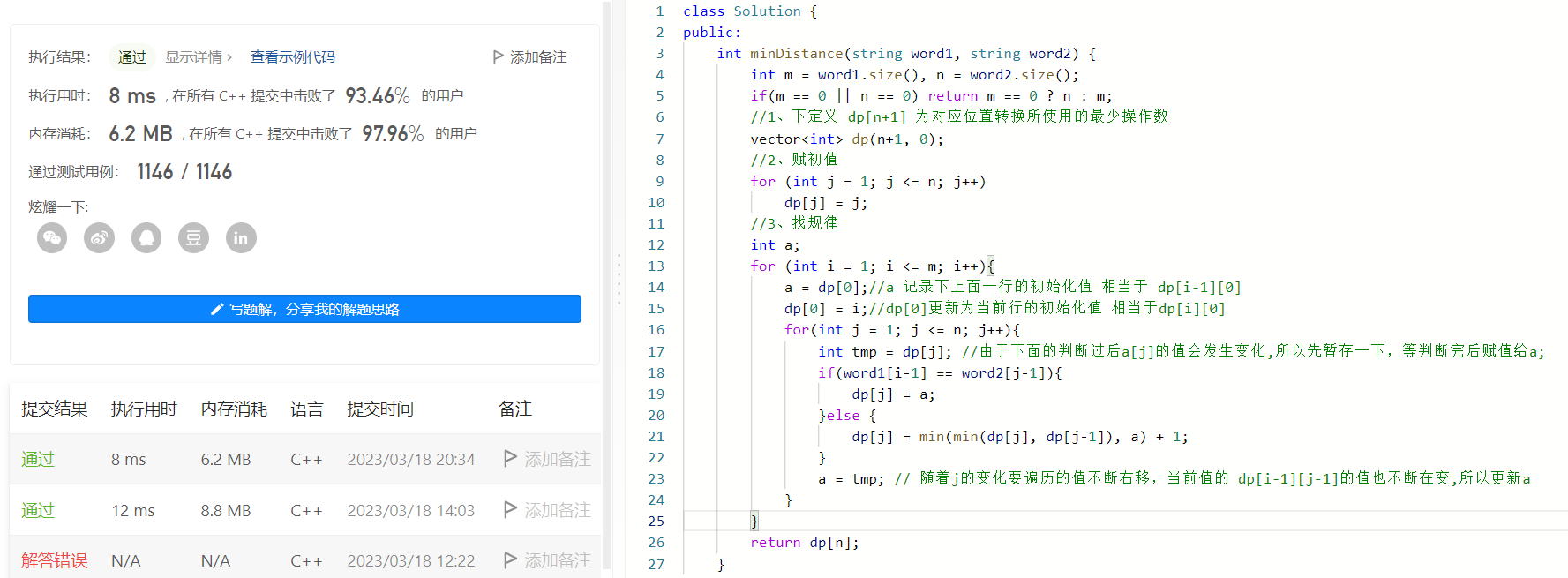
目录一、简单的一维DP剑指 Offer 10- I. 斐波那契数列1、三板斧解决问题2、优雅的解决问题剑指 Offer 63 股票的最大利润1、三板斧解决问题2、优雅的解决问题二、进阶的二维DP剑指offer47 礼物的最大价值1、三板斧解决问题2、优雅的解决问题编辑距离1、三板斧解决问题2、优雅的…...

算法进阶指南打卡
文章目录 基本算法 位运算递推与递归前缀和与差分二分排序倍增贪心总结与练习基本数据结构 栈队列链表与邻接表Hash字符串Tire二叉堆总结与练习搜索 树与图的遍历深度优先搜索剪枝迭代加深广度优先搜索广度变形A*IDA*总结与练习数学知识 质数约数同余矩阵乘法高斯消元与线性空…...

Chapter6.2:其他根轨迹及综合实例分析
该系列博客主要讲述Matlab软件在自动控制方面的应用,如无自动控制理论基础,请先学习自动控制系列博文,该系列博客不再详细讲解自动控制理论知识。 自动控制理论基础相关链接:https://blog.csdn.net/qq_39032096/category_10287468…...
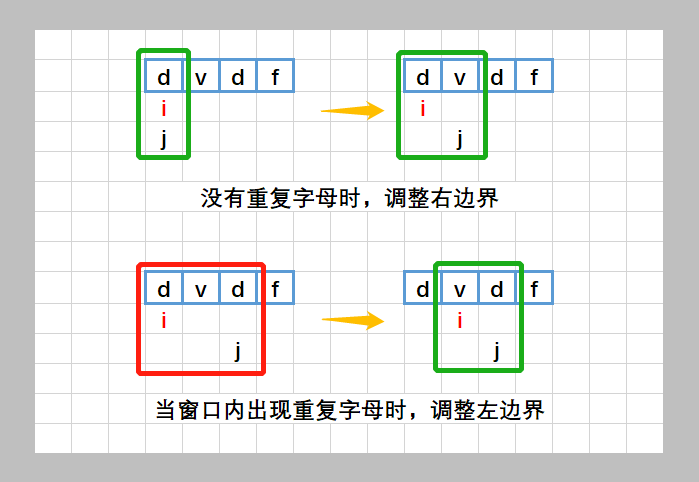
3. 无重复字符的最长子串——滑动窗口
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。 示例 2: 输入: s "bbbbb" 输出: 1 解释: 因为无…...
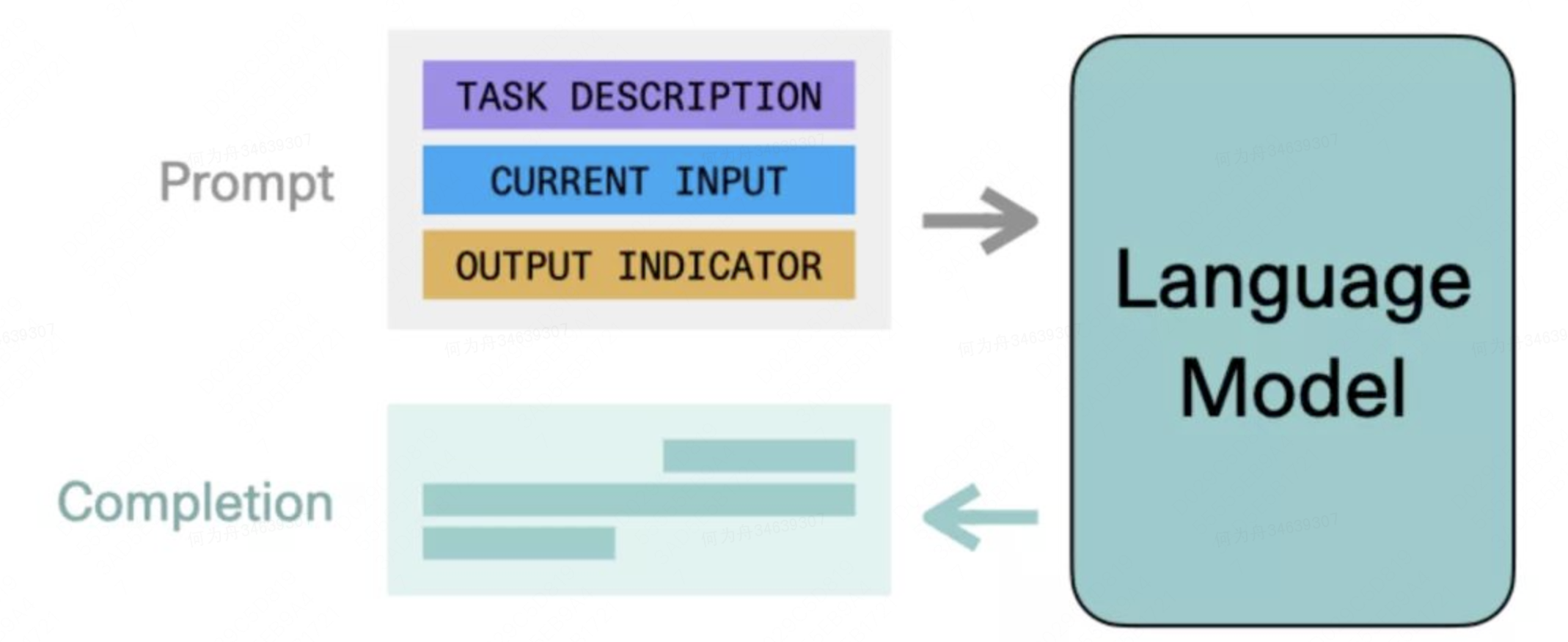
ChatGPT研究分享:机器第一次开始理解人类世界
0、为什么会对ChatGPT感兴趣一开始,我对ChatGPT是没什么关注的,无非就是有更大的数据集,完成了更大规模的计算,所以能够回答更多的问题。但后来了解到几个案例,开始觉得这个事情并不简单。我先分别列举出来,…...

可换皮肤的Qt登录界面
⭐️我叫忆_恒心,一名喜欢书写博客的在读研究生👨🎓。 如果觉得本文能帮到您,麻烦点个赞👍呗! 近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支持一下呗。👍⭐️❤️ 可换皮肤的Qt登录界面 QSS的学习笔记 快…...

Spring的常见问题汇总
一、bean实例化1、构造方法底层是无参构造方法来new的对象。2、静态工厂实例化Bean实质上就是:创建一个静态工厂类,然后调用静态工厂类的静态方法,来创建对象。3、实例工厂与FactoryBean实质上就是:创建一个工厂类,工厂…...
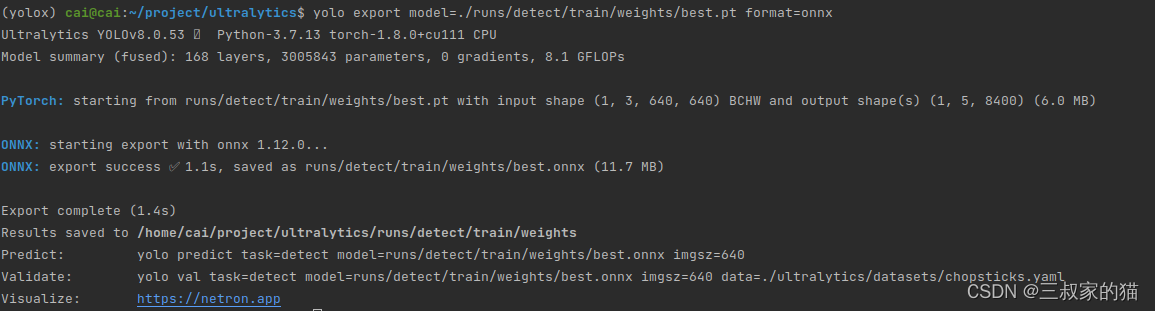
yolov8训练筷子点数数据集
序言 yolov8发布这么久了,一直没有机会尝试一下,今天用之前自己制作的筷子点数数据集进行训练,并且记录一下使用过程以及一些常见的操作方式,供以后翻阅。 一、环境准备 yolov8的训练相对于之前的yolov5简单了很多,…...
使用 Python 从点云生成 3D 网格
从点云生成 3D 网格的最快方法 已经用 Python 编写了几个实现来从点云中获取网格。它们中的大多数的问题在于它们意味着设置许多难以调整的参数,尤其是在不是 3D 数据处理专家的情况下。在这个简短的指南中,我想展示从点云生成网格的最快和最简单的过程。…...
将字符串分割数组join()将数组转字符串reverse()将数组反转)
vue使用split()将字符串分割数组join()将数组转字符串reverse()将数组反转
1.split() 将字符串切割成数组 const str Hello Vue2 Vue3 console.log(str.split()) console.log(str.split()) console.log(str.split( )) console.log(str.split( , 2)) console.log(str.split( , 6))输出如下 1.split()不传参数默认整个字符串作为数组的一个元素…...
队列实现及leetcode相关OJ题
上一篇写的是栈这一篇分享队列实现及其与队列相关OJ题 文章目录一、队列概念及实现二、队列源码三、leetcode相关OJ一、队列概念及实现 1、队列概念 队列同栈一样也是一种特殊的数据结构,遵循先进先出的原则,例如:想象在独木桥上走着的人&am…...
)
深入浅出:从原理到实践,手把手教你理解并校准RV1126 ISP的黑电平(BLC)
深入浅出:从原理到实践,手把手教你理解并校准RV1126 ISP的黑电平(BLC) 在数字图像处理领域,黑电平校准(Black Level Calibration, BLC)是一个看似简单却至关重要的环节。想象一下,当你用专业相机拍摄星空时…...

RCS调度系统:从架构蓝图到智能协同的实战解析
1. RCS调度系统:现代仓储的智能大脑 想象一下,在一个数万平方米的智能仓库里,上百台AGV(自动导引车)正在同时穿梭。它们有的在搬运货架,有的在分拣包裹,还有的在自动充电。这些AGV既不会撞车&am…...

JVS-APS智能排产后如何配置移动端扫码报工
报工是在工厂中,确定人员/产线按照计划执行后,提交生产结果数据,那么在APS 完成计划排产后,如何能便捷的报工,下面我们有JVS快速开发平台做了一个报工的应用,实现 aps-mes 之间 任务下发与任务结果反馈的整…...

突破B站字幕处理瓶颈:BiliBiliCCSubtitle全流程解决方案
突破B站字幕处理瓶颈:BiliBiliCCSubtitle全流程解决方案 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 一、问题发现:字幕处理的现实困境…...

BGE-Large-Zh前沿探索:量子计算语义编码实验
BGE-Large-Zh前沿探索:量子计算语义编码实验 引言 量子计算正在重新定义计算的边界,而自然语言处理作为人工智能的核心领域,也迎来了与量子技术融合的历史性机遇。我们进行了一项创新实验:将BGE-Large-Zh这一强大的语义编码模型…...

BiliBiliCCSubtitle:高效解决B站字幕处理难题全攻略
BiliBiliCCSubtitle:高效解决B站字幕处理难题全攻略 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 一、问题篇:字幕处理的真实困境与技术…...

Win11Debloat:让Windows 11系统轻盈如飞的优化工具
Win11Debloat:让Windows 11系统轻盈如飞的优化工具 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custo…...

SketchUp STL插件:5个简单步骤实现3D打印工作流革命
SketchUp STL插件:5个简单步骤实现3D打印工作流革命 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl 你是否曾为Sk…...

避坑指南:新到手的NUC 13装Ubuntu,WiFi驱动对了但图标不显示?可能是AX211网卡在Linux下的‘通病’
NUC 13安装Ubuntu后WiFi图标消失的深度排查与解决方案 刚拿到手的Intel NUC 13装上Ubuntu系统,WiFi驱动看似正常却不见图标?这可能是AX211网卡在Linux下的"通病"。作为一名长期与硬件兼容性问题打交道的技术顾问,我遇到过太多类似…...

Qwen2.5-0.5B-Instruct新手入门:从零到一的AI助手搭建全流程
Qwen2.5-0.5B-Instruct新手入门:从零到一的AI助手搭建全流程 1. 认识Qwen2.5-0.5B-Instruct 1.1 模型特点与优势 Qwen2.5-0.5B-Instruct是阿里开源的通义千问系列中最轻量级的指令微调版本,专为资源有限环境优化设计。这个5.08亿参数的模型虽然体积小…...