数据库系统 第42节 数据库索引简介
数据库索引是数据库表中一个或多个列的数据结构,用于加快数据检索速度。除了基础的B-Tree索引,其他类型的索引针对特定的数据类型和查询模式提供了优化。以下是几种不同类型的索引及其使用场景的详细说明和示例代码。
1. 位图索引 (Bitmap Index)
位图索引适用于具有少量不同值的列(例如性别、国家代码等),它使用位图来表示数据,从而提高查询效率。
适用场景:当列中的值域较小,且数据分布极不均匀时。
示例代码(Oracle):
CREATE BITMAP INDEX bitmap_gender_idx ON employees(gender);
在这个例子中,我们为employees表的gender列创建了一个位图索引,假设gender列只有少数几个值(如’M’和’F’)。
2. 全文索引 (Full-text Index)
全文索引用于搜索文本中的关键字,支持复杂查询,如模糊查询和多关键字查询。
适用场景:需要进行文本搜索的场合,如搜索引擎、文档管理系统。
示例代码(SQL Server):
CREATE FULLTEXT INDEX ON Documents(Body)KEY INDEX PK_Documents_DocumentIDWITH STOPLIST = SYSTEM;
这里,我们为Documents表的Body列创建了一个全文索引,使用系统停用词列表。
3. 空间索引 (Spatial Index)
空间索引用于地理空间数据,支持空间关系查询,如点与多边形的关系。
适用场景:地理信息系统(GIS)、地图服务。
示例代码(PostgreSQL with PostGIS):
CREATE EXTENSION postgis;CREATE TABLE locations (id SERIAL PRIMARY KEY,name VARCHAR(50),location GEOGRAPHY(Point)
);CREATE INDEX locations_gist_idx ON locations USING GIST (location);
在这个例子中,我们创建了一个包含地理空间数据的locations表,并为其location列创建了一个使用GiST算法的空间索引。
4. 函数索引 (Function-Based Index)
函数索引基于列的表达式或函数,允许索引列的计算结果,而不是列本身。
适用场景:需要根据列的计算结果进行查询优化。
示例代码(MySQL):
CREATE INDEX idx_lastname_upper ON users(UPPER(lastname));
这里,我们为users表的lastname列的转换为大写后的值创建了一个索引。
5. 表达式索引 (Expression Index)
表达式索引类似于函数索引,但它允许更复杂的表达式。
适用场景:需要基于列的复杂表达式进行查询优化。
示例代码(SQL Server):
CREATE INDEX idx_expression ON Sales((TotalAmount * 1.2));
在这个例子中,我们为Sales表的TotalAmount列乘以1.2的结果创建了一个索引。
6. 复合索引 (Composite Index)
复合索引包含两个或多个列,可以提高多列查询的性能。
适用场景:经常一起查询的多个列。
示例代码(MySQL):
CREATE INDEX idx_composite ON orders(cust_id, order_date);
这里,我们为orders表的cust_id和order_date列创建了一个复合索引。
7. 覆盖索引 (Covering Index)
覆盖索引是包含查询所需所有列的索引,可以避免访问表数据,直接从索引中获取数据。
适用场景:查询只涉及少数几列,且这些列可以被索引覆盖。
示例代码(Oracle):
CREATE INDEX idx_covering ON employees(emp_id, emp_name, department);
在这个例子中,我们为employees表的emp_id、emp_name和department列创建了一个覆盖索引。
通过这些不同类型的索引,数据库管理员和开发人员可以根据具体的数据和查询需求选择合适的索引类型,以优化数据库的性能和响应时间。
我们可以深入讨论一些特定场景下的索引策略,以及如何维护和优化索引。
8. 索引的维护
随着数据的不断变化,索引可能需要定期维护以保持其性能。
适用场景:数据频繁更新、插入或删除。
示例代码(通用):
- 重建索引:在数据库中定期重建索引可以帮助减少索引碎片,提高查询性能。
- 重新组织索引:对于某些数据库系统,如SQL Server,可以通过重新组织索引来减少页分裂。
9. 索引的监控和优化
监控索引的使用情况和性能,可以帮助确定哪些索引是有效的,哪些可能需要优化或删除。
适用场景:数据库性能调优。
示例代码(通用):
- 查询索引使用统计:大多数数据库提供了查询索引使用情况的工具,如MySQL的
SHOW INDEX和SQL Server的sys.indexes。
10. 索引的自动管理
一些数据库系统提供了自动管理索引的功能,可以自动创建、调整或删除索引。
适用场景:需要最小化数据库管理开销的环境。
示例代码(SQL Server):
CREATE INDEX ... ON ... WITH (ONLINE = ON, SORT_IN_TEMPDB = ON);
在这个例子中,我们创建了一个索引,并指定了在线创建索引和使用临时数据库进行排序,以减少对生产环境的影响。
11. 索引的并行处理
在多核处理器上,可以并行创建或重建索引,以加快索引操作的速度。
适用场景:大型数据库的索引操作。
示例代码(MySQL):
ALTER TABLE ... REBUILD PARTITION ... PARALLEL ...;
在这个例子中,我们重建了一个分区表的索引,并指定了并行处理。
12. 索引的压缩
在某些数据库系统中,可以对索引进行压缩以节省存储空间。
适用场景:存储空间受限的环境。
示例代码(Oracle):
ALTER TABLE ... ENABLE ROW MOVEMENT;
在Oracle中,启用行移动可以允许数据库自动压缩索引。
13. 索引的锁定策略
在索引操作期间,合理的锁定策略可以减少对数据库操作的影响。
适用场景:需要最小化索引操作对数据库性能影响的环境。
示例代码(SQL Server):
CREATE INDEX ... ON ... WITH (ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON);
在这个例子中,我们创建了一个索引,并允许行级和页面级锁定。
14. 索引的过滤条件
在创建索引时,可以指定过滤条件,使得索引只包含满足特定条件的行。
适用场景:特定查询模式的优化。
示例代码(SQL Server):
CREATE INDEX idx_filtered ON ... WHERE ...;
在这个例子中,我们创建了一个带有过滤条件的索引,只包含满足特定条件的行。
15. 索引的存储结构
不同的数据库系统提供了不同的存储结构来存储索引,如B-Tree、Hash、R-Tree等。
适用场景:根据数据类型和查询模式选择合适的存储结构。
示例代码(PostgreSQL):
CREATE INDEX ... USING GIN (column);
在这个例子中,我们为列创建了一个使用GIN(Generalized Inverted Index)存储结构的索引,适用于文本搜索。
通过这些高级索引策略和最佳实践,数据库管理员和开发人员可以更有效地利用索引来优化数据库的性能和响应时间。
16. 索引的分区
对于大型表,索引的分区可以帮助提高索引的管理和查询性能。
适用场景:大型数据库,特别是那些具有大量索引的表。
示例代码(Oracle):
CREATE INDEX idx_partitioned ON large_table (column) PARTITION BY RANGE (column) (PARTITION p1 VALUES LESS THAN (100),PARTITION p2 VALUES LESS THAN (200),PARTITION p3 VALUES LESS THAN (MAXVALUE));
在这个例子中,我们为large_table表的column列创建了一个分区索引。
17. 索引的覆盖范围
索引的覆盖范围是指索引中包含的列数。选择合适的覆盖范围可以提高查询性能。
适用场景:需要优化特定查询的性能。
示例代码(MySQL):
CREATE INDEX idx_covering_range ON table_name (column1, column2, column3);
在这个例子中,我们为table_name表创建了一个覆盖三个列的索引。
18. 索引的压缩和存储
在某些数据库系统中,可以对索引进行压缩以节省存储空间,同时保持查询性能。
适用场景:存储空间受限的环境。
示例代码(MySQL):
ALTER TABLE table_name ALGORITHM=INPLACE, LOCK=NONE;
在这个例子中,我们对table_name表进行了在线无锁的重构,以优化存储。
19. 索引的自动调整
一些数据库系统提供了自动调整索引大小和结构的功能,以适应数据的变化。
适用场景:数据频繁变化的环境。
示例代码(PostgreSQL):
ALTER INDEX index_name SET (fillfactor = 90);
在这个例子中,我们调整了index_name索引的填充因子,以优化存储和性能。
20. 索引的并发控制
在多用户环境中,合理的并发控制策略可以减少索引操作对数据库性能的影响。
适用场景:高并发的数据库环境。
示例代码(SQL Server):
CREATE INDEX idx_concurrency ON table_name (column) WITH (ONLINE = ON);
在这个例子中,我们创建了一个在线索引,以减少对数据库操作的影响。
21. 索引的版本控制
在分布式数据库系统中,索引的版本控制可以帮助确保数据的一致性和完整性。
适用场景:分布式数据库环境。
示例代码(通用):
- 在分布式数据库系统中,通常需要通过数据库管理系统的特定功能来实现索引的版本控制。
22. 索引的安全性
在某些情况下,可能需要对索引进行加密或限制访问,以保护敏感数据。
适用场景:包含敏感数据的数据库。
示例代码(Oracle):
CREATE INDEX idx_encrypted ON table_name (column) USING ENCRYPTION (ENCRYPTION TYPE IS 'AES256');
在这个例子中,我们为table_name表的column列创建了一个加密索引。
23. 索引的监控和日志记录
监控索引的使用和性能,以及记录索引操作的日志,可以帮助识别和解决性能问题。
适用场景:需要监控数据库性能的环境。
示例代码(通用):
- 大多数数据库系统提供了监控工具和日志记录功能,可以通过数据库管理系统的界面或命令来配置。
通过这些高级索引特性和策略,数据库管理员和开发人员可以更全面地管理和优化数据库索引,以适应各种复杂的业务需求和数据环境。
相关文章:

数据库系统 第42节 数据库索引简介
数据库索引是数据库表中一个或多个列的数据结构,用于加快数据检索速度。除了基础的B-Tree索引,其他类型的索引针对特定的数据类型和查询模式提供了优化。以下是几种不同类型的索引及其使用场景的详细说明和示例代码。 1. 位图索引 (Bitmap Index) 位图…...

C++11 --- 智能指针
序言 在使用 C / C 进行编程时,许多场景都需要我们在堆上申请空间,堆内存的申请和释放都需要我们自己进行手动管理。这就存在容易造成堆内存泄露(忘记释放),二次释放,程序发生异常时内存泄露等问题…...

C#顺序万年历自写的求余函数与周位移算法
static int 返回月的天数(int 年, int 月){return (月 2 ?(((年 % 4 0 && 年 % 100 > 0) || 年 % 400 0) ? 29 : 28) :(((月 < 7 && 月 % 2 > 0) || (月 > 7 && 月 % 2 0)) ? 31 : 30));}static int 返回年总天数(int 年, int 标 …...

【Java并发编程一】八千字详解多线程
目录 多线程基础 1.线程和进程 线程是什么? 为啥要有线程? 进程和线程的区别? Java 的线程 和 操作系统线程 的关系 使用jconsole观察线程 2.创建线程的多种方式 3.Thread类及其常见方法 Thread类的常见构造方法 Thread类的常见属性…...

CentOS 8FTP服务器
FTP(文件传输协议)是一种客户端-服务器网络协议,允许用户在远程计算机之间传输文件。这里有很多可用于Linux的开源FTP服务软件,最流行最常用的FTP服务软件有 PureFTPd, ProFTPD, 和 vsftpd。在本教程中,我们将在CentOS…...

C++ | Leetcode C++题解之第385题迷你语法分析器
题目: 题解: class Solution { public:NestedInteger deserialize(string s) {if (s[0] ! [) {return NestedInteger(stoi(s));}stack<NestedInteger> st;int num 0;bool negative false;for (int i 0; i < s.size(); i) {char c s[i];if …...

【软件设计师真题】第一大题---数据流图设计
解答数据流图的题目关键在于细心。 考试时一定要仔细阅读题目说明和给出的流程图。另外,解题时要懂得将说明和流程图进行对照,将父图和子图进行对照,切忌按照常识来猜测。同时应按照一定顺序考虑问题,以防遗漏,比如可以…...

系统架构的发展历程之模块化与组件化
模块化开发方法 模块化开发方法是指把一个待开发的软件分解成若干个小的而且简单的部分,采用对复杂事物分而治之的经典原则。模块化开发方法涉及的主要问题是模块设计的规则,即系统如何分解成模块。而每一模块都可独立开发与测试,最后再组装…...
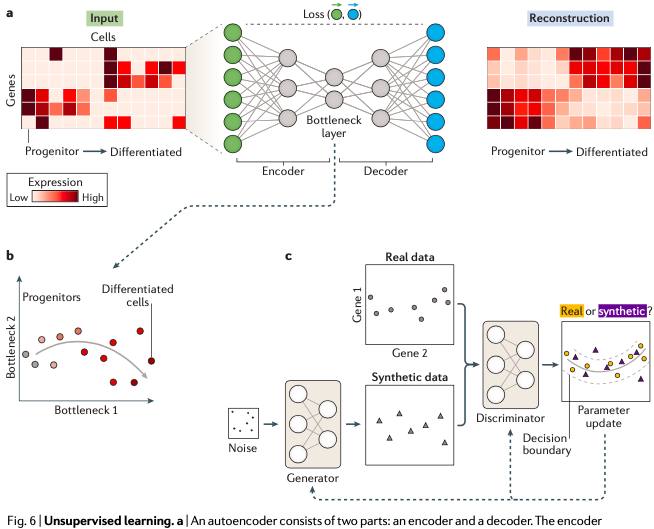
基因组学中的深度学习
----/ START /---- 基因组学其实是一门将数据驱动作为主要研究手段的学科,机器学习方法和统计学方法在基因组学中的应用一直都比较广泛。 不过现在多组学数据进一步激增——这个从目前逐渐增多的各类大规模人群基因组项目上可以看出来,这其实带来了新的挑…...

解决老师询问最高分数问题的编程方案
解决老师询问最高分数问题的编程方案 问题分析数据结构选择:线段树线段树的基本操作伪代码伪代码:构建线段树伪代码:更新操作伪代码:查询操作C语言实现代码详细解释在日常教学中,老师经常需要查询某一群学生中的最高分数,并有时会更新某位同学的成绩。为了实现这一功能,…...

com.baomidou.mybatisplus.annotation.DbType 无法引入
com.baomidou.mybatisplus.annotation.DbType 无法引入爆红 解决 解决 ❤️ 3.4.1 是mybatis-plus版本,根据实际的配置→版本一致 <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-annotation</artifactId>&…...

从零开始学习JVM(七)- StringTable字符串常量池
1 概述 String应该是Java使用最多的类吧,很少有Java程序没有使用到String的。在Java中创建对象是一件挺耗费性能的事,而且我们又经常使用相同的String对象,那么创建这些相同的对象不是白白浪费性能吗。所以就有了StringTable这一特殊的存在&…...

数据库课程设计mysql
进行 MySQL 数据库课程设计通常包括以下几个步骤,从需求分析到数据库设计和实现。以下是一个常见的流程及要点: 1. 需求分析 首先,明确系统的功能需求。这包括用户需求、业务流程、功能模块等。你需要与相关人员(比如老师、同学…...

AI学习指南深度学习篇-带动量的随机梯度下降法的基本原理
AI学习指南深度学习篇——带动量的随机梯度下降法的基本原理 引言 在深度学习中,优化算法被广泛应用于训练神经网络模型。随机梯度下降法(SGD)是最常用的优化算法之一,但单独使用SGD在收敛速度和稳定性方面存在一些问题。为了应…...

点餐小程序实战教程03创建应用
目录 1 创建应用2 第一部分侧边栏3 第二部分页面功能区4 第三部分大纲树5 第四部分代码区6 第五部分模式切换7 第六部分编辑区域8 第七部分组件区域9 第八部分,发布区域10 第九部分开发调试和高阶配置总结 上一篇我们介绍了如何实现后端API,介绍了登录验…...

鸿蒙自动化发布测试版本app
创建API客户端 API客户端是AppGallery Connect用于管理用户访问AppGallery Connect API的身份凭据,您可以给不同角色创建不同的API客户端,使不同角色可以访问对应权限的AppGallery Connect API。在访问某个API前,必须创建有权访问该API的API…...

力扣9.7
115.不同的子序列 题目 给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数,结果需要对 109 7 取模。 数据范围 1 < s.length, t.length < 1000s 和 t 由英文字母组成 分析 令dp[i][j]为s的前i个字符构成的子序列中为t的前j…...

GPU 带宽功耗优化
移动端GPU 的内存结构: 先简述移动端内存cache结构;上图的UMA结构 on-Chip memory 包括了 L1、L2 cache,非常关键的移动端的 Tiles 也是保存在 on-chip上还包括寄存器文件:提供给每个核心使用的极高速存储。 共享内存(…...

Linux Centos 7网络配置
本步骤基于Centos 7,使用的虚拟机是VMware Workstation Pro,最终可实现虚拟机与外网互通。如为其他发行版本的linux,可能会有差异。 1、检查外网访问状态 ping www.baidu.com 2、查看网卡配置信息 ip addr 3、配置网卡 cd /etc/sysconfig…...

第三天旅游线路规划
第三天:从贾登峪到禾木风景区,晚上住宿贾登峪; 从贾登峪到禾木风景区入口: 1、行程安排 根据上面的耗时情况,规划一天的行程安排如下: 1)早上9:00起床,吃完早饭&#…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...