建模杂谈系列252 规则的串行改并行
说明
提到规则,还是需要看一眼RETE算法:
Rete算法是一种用于高效处理基于规则的系统中的模式匹配问题的算法,广泛应用于专家系统、推理引擎和生产系统。它的设计目的是在大量规则和数据的组合中快速找到满足特定规则条件的模式。
Rete算法的几个关键特点,使它在特定场景下非常高效:
1. 避免冗余计算
- 保存中间结果:Rete算法利用称为“Rete网”的数据结构存储中间计算结果。每次新数据到来时,不会重新从头计算所有规则,而是仅更新那些受到影响的部分。这避免了对不相关数据的重复匹配,大大减少了计算量。
- 共享条件检查:许多规则往往有相似的条件。Rete算法通过共享相同条件的计算结果,避免了对相同条件的重复评估。例如,如果多个规则都检查某个属性是否为特定值,Rete算法只进行一次检查,而不是对每个规则重复进行检查。
2. 增量式匹配
- Rete算法是一种增量式匹配算法。它仅在有新数据到达或数据更新时进行部分更新,而不是每次都从头重新计算所有数据和规则。这样一来,对于大量规则和数据的系统来说,性能得到了显著提升。
3. 分离规则与数据的处理
- Rete算法将规则的模式匹配与具体的数据处理分离开来。每个规则的条件被分解成不同的节点,在数据到来时,数据在这些节点中传播。这样即便是非常复杂的规则,算法也可以高效地进行匹配。
4. 适合多条件匹配
- Rete算法特别适合处理多个条件组合的模式匹配问题。它通过构建树形或网络结构来对条件进行层次化处理,使得多个条件的组合能够被高效地处理。
5. 低重复性数据处理
- 如果一个系统中的事实变化较少,而规则非常多,Rete算法的优势尤其明显。它能够减少对不变事实的重新处理,只处理变化的事实或数据。
为什么高效:
- 空间换时间:Rete算法通过大量存储中间结果,换取计算效率,适合需要频繁进行规则匹配的场景。
- 避免冗余计算和重复条件检查,最大限度地减少了不必要的计算。
- 增量更新方式确保了只处理受影响的部分,而不是每次全局匹配,大大提升了效率。
这些特性使得Rete算法在处理复杂的规则系统时能够大大减少计算开销,尤其适用于规则众多、数据量大但变化频繁的场景。
事实上,RETE产生的时间特别早(1974年),那个时代的计算资源是特别稀缺的。那个时代的许多算法、命令都是具有极简、极高效的特点,同时可读性一般也很差。
我认为,随着硬件的进步,效率是次要考虑的问题。如何节约人的时间,如何确保可靠的决策(可解释性)才是要有限考虑的问题。当然我还是更多的从数据处理的角度,而不是一个纯粹业务的角度去考虑规则引擎这个产品。
内容
1 人能掌握的逻辑
横向来看,人能掌握的逻辑不会超过10个(超过一定数据,大脑会自己尝试聚类),但是通过层级化纵向构建,我们可以掌控上百,甚至上千个逻辑。
但是层级化,通常也是效率的大敌。即便是使用了RETE,但是规则的逻辑链条很长,最终的执行结果也快不了。
既然层级避免不了,那么就建立一个层级框架,让逻辑可以更有效的聚拢和排序。
逻辑层级:
- R0: 前置规则 : 例如 <18岁不可以贷款, 通用由业务的监管强行指定,常为 if
- R1: 强规则 : 例如 没有固定收入不可以贷款, 由业务本身的逻辑确定,常为 if
- R2: 弱规则 : 例如 信用评分低于600不可以贷款, 超出人可观察的部分,采用模型量化的方式,常为model
- R3: 规则的规则 : 例如 同时有5个特定规则打分低,不可以贷款, model or if
- R4: 后置规则 : 例如 测试用户可以通过 , 其他特定的修补,常为 if
执行层级不同与逻辑层级,按照顺序,尽量合并可以并行执行的部分;并且尽量提早过滤掉可以递减的部分。这里其实还有另一个问题:一条数据是应该尽早作出决定,还是坚持跑完所有规则。
2 现实问题
先解决一些现实问题:实体匹配环节特别慢。
最初在实现逻辑时,并没有考虑效率问题。
逻辑代码大抵如下,对一篇文档里的若干个实体,循环调用规则(微服务接口)来获得处理结果。
...# r0 for the_ent in the_ent_list:# r0resp1 = req.post(f'{base_url}r000/', json = {'some_ent':the_ent}).json()if resp1['status'] == 'reject':print('r000', the_ent)continue resp2 = req.post(f'{base_url}r001/', json = {'some_ent':the_ent}).json()if resp2['status'] == 'reject':print('r001', the_ent)mr.illegal_suffix.append(the_ent)continue# r0 endthe_ent_len = len(the_ent) if the_ent_len< 2:mr.too_short.append(the_ent)elif the_ent_len <7:mr.short.append(the_ent)elif the_ent_len < 25:mr.norm.append(the_ent)else:mr.too_long.append(the_ent)
...
所以,当有15个实体的时候,第一个规则就花了约(0.005x15 ~ 0.075秒),第二个规则花了(0.005x64 ~ 0.32秒)
['基金', '美芯晟', '高新兴', '骏成科技', '证券时报', '深市主板', '创业板', '沪市', '科创板', '计算机', '机械设备', '共有3', '潍柴动力', '乐心医疗', '嘉曼服饰', '敏芯股份', '渝开发', '长虹美菱', '德联集团', '数据宝', '中航西飞', '顺络电子', '基金家数', '华利集团', '杰瑞股份', '邦彦技术', '兴瑞科技', '深天马', '漫步', '金力永磁', '太阳能', '普蕊斯', '德方纳米', '华锐精密', '伊之密', '西子洁能', '陕西华达', '浙江鼎力', '诺瓦星云', '远光']
0.006989002227783203
0.006243467330932617
0.007495403289794922
0.00716400146484375
0.00490117073059082
0.006025791168212891
0.00599360466003418
0.0046253204345703125
0.00520634651184082
0.004281282424926758
0.00481104850769043
0.00475764274597168
0.004372358322143555
0.005066394805908203
0.005623817443847656
r001 沪市
0.005009651184082031
0.004489898681640625
0.00529026985168457
0.004183292388916016
0.005280017852783203
0.004261970520019531
0.00518345832824707
0.004296541213989258
0.004305362701416016
0.004907131195068359
0.004319667816162109
0.004322052001953125
0.005274534225463867
0.004192829132080078
0.005210399627685547
0.004171133041381836
0.005131244659423828
0.004136562347412109
0.0051212310791015625
0.004184722900390625
0.004403829574584961
0.006170988082885742
0.004761934280395508
0.009701728820800781
0.007318019866943359
0.004835844039916992
0.004235267639160156
0.002786397933959961
0.0059130191802978516
0.0027306079864501953
0.0025987625122070312
0.0024881362915039062
0.004175662994384766
0.002477884292602539
0.004856109619140625
0.0036249160766601562
0.002595186233520508
0.0032770633697509766
0.0023193359375
0.003595113754272461
0.002864360809326172
0.0032558441162109375
0.004605293273925781
0.003146648406982422
0.0032491683959960938
0.0031249523162841797
0.0046842098236083984
0.003545045852661133
0.0027167797088623047
0.0030341148376464844
0.0034787654876708984
0.004285573959350586
0.002904176712036133
0.0032575130462646484
0.0021605491638183594
0.003958225250244141
0.00409245491027832
0.005880117416381836
0.004957675933837891
0.0028581619262695312
0.0026171207427978516
0.0026040077209472656
0.0026750564575195312
0.002580881118774414所以,效率问题在这里可以通过IO并发来解决。理论上,用协程更好些,多线程简单一点。
2.1 先测试一个并发
使用asyncio 并发
import json
import asyncio, aiohttpasync def json_query_worker(task_id = None , url = None , json_params = None,time_out = 320, semaphore = None):async with semaphore:try:async with aiohttp.ClientSession() as session:async with session.post(url, json = {**json_params},timeout=aiohttp.ClientTimeout(total=time_out)) as response:res = await response.text()return {task_id: json.loads(res)}except json.JSONDecodeError as e:print({task_id: f"JSONDecodeError: {e}"})return Noneexcept Exception as e:print({task_id: f"Exception: {e}"})return Noneasync def json_player(task_list , concurrent = 3):semaphore = asyncio.Semaphore(concurrent) # 并发限制tasks = [asyncio.ensure_future(json_query_worker(**x, semaphore = semaphore)) for x in task_list]return await asyncio.gather(*tasks)
执行
rname = 'r000'
# rname = 'r001'
short_name_query_url = f'http://127.0.0.1:24133/{rname}/'
ent_list = ['基金', '美芯晟', '高新兴', '骏成科技', '证券时报', '深市主板', '创业板', '沪市', '科创板', '计算机',
'机械设备', '共有3', '潍柴动力', '乐心医疗', '嘉曼服饰', '敏芯股份', '渝开发', '长虹美菱', '德联集团', '数据宝',
'中航西飞', '顺络电子', '基金家数', '华利集团', '杰瑞股份', '邦彦技术', '兴瑞科技', '深天马', '漫步',
'金力永磁', '太阳能', '普蕊斯', '德方纳米', '华锐精密', '伊之密', '西子洁能', '陕西华达', '浙江鼎力', '诺瓦星云', '远光']import time
tick1 = time.time()
task_list = []
for ent in ent_list:tem_dict = {}tem_dict['task_id'] = ent tem_dict['url'] = short_name_query_urltem_dict['json_params'] = {'some_ent':ent}task_list.append(tem_dict)
res = asyncio.run(json_player(task_list, concurrent = 100))
tick2 = time.time()
print('takes %.2f ' %(tick2-tick1))tick3 = time.time()
import requests as req
res_dict = {}
for ent in ent_list:resp = req.post(short_name_query_url, json = {'some_ent':ent}).json()res_dict[ent] = resp
tick4 = time.time()
print('takes %.2f ' %(tick4-tick3))takes 0.06
takes 0.22
---
takes 0.05
takes 0.22
---
takes 0.05
takes 0.19
---
takes 0.05
takes 0.18
---
takes 0.05
takes 0.23
一共有40个请求,平均下来,并行情况下每个约0.0015, 串行下每个0.0055。
所以,改造的思路:
- 1 【以实体为中心】原来是每个实体,逐个循环去遍历请求规则服务(这个是one模式,有用且仍然会保留)。
- 2 【以规则为中心】将所有实体批次的请求规则,一次性获得结果。
在这里,有一个细节(序列化开销)还是需要注意的。
在大部分的请求中,只要将对应的实体进行请求即可,问题不大;但是有个别规则,为了实现上下文判别,需要实体和原文同时输入。这时,如果原文很大,而实体又很多,那么序列化的成本就会非常高。另外就是,当处理还是按文档级别来,那么其实也还是某种程度的one模式(文档内并行了,而文档间还是串行)
所以,api化和本地化(函数)又是一对模式。 如果是查询性质的,或者是密集计算型的任务,适合用api。例如,要进行数据库查询,或者大模型请求,比较适合api化。而IO类的,比如,要查询一个实体的上下文,本质上是要在一个稍微大一些的文本里做正则类模糊查询,这个就适合在本地(函数)做。
2.2 并行改造
从效率考虑,并行的,递减的执行
part1: 这部分主要是进行过滤和分流。
原来
# r0 for the_ent in the_ent_list:# r0resp1 = req.post(f'{base_url}r000/', json = {'some_ent':the_ent}).json()if resp1['status'] == 'reject':print('r000', the_ent)continue resp2 = req.post(f'{base_url}r001/', json = {'some_ent':the_ent}).json()if resp2['status'] == 'reject':print('r001', the_ent)mr.illegal_suffix.append(the_ent)continue# r0 endthe_ent_len = len(the_ent) if the_ent_len< 2:mr.too_short.append(the_ent)elif the_ent_len <7:mr.short.append(the_ent)elif the_ent_len < 25:mr.norm.append(the_ent)else:mr.too_long.append(the_ent)
并行化
r000_url = base_url + 'r000/'tick1 = time.time()task_list = []for ent in ent_list:tem_dict = {}tem_dict['task_id'] = ent tem_dict['url'] = r000_urltem_dict['json_params'] = {'some_ent':ent}task_list.append(tem_dict)r000_res = asyncio.run(json_player(task_list, concurrent = 100))# 解析结果,保留passent_list1 = []for tem_res in r000_res:for k,v in tem_res.items():# print(k,v)if v['status'] == 'pass':ent_list1.append(k)tick2 = time.time()print('takes %.2f ' %(tick2-tick1))# 增加解析结果,慢了20%。如果可以传递一个全局对象,不需要再解析,这个可以更快
takes 0.06
r001
# r001 ent_list1 -> ent_list2r001_url = base_url + 'r001/'tick1 = time.time()task_list = []for ent in ent_list1:tem_dict = {}tem_dict['task_id'] = ent tem_dict['url'] = r001_urltem_dict['json_params'] = {'some_ent':ent}task_list.append(tem_dict)r001_res = asyncio.run(json_player(task_list, concurrent = 100))# 解析结果,保留passent_list2 = []for tem_res in r001_res:for k,v in tem_res.items():# print(k,v)if v['status'] == 'pass':ent_list2.append(k)elif v['status'] =='reject':mr.illegal_suffix.append(k)tick2 = time.time()print('takes %.2f ' %(tick2-tick1))
takes 0.06In [40]: mr
Out[40]: MultiRes(doc_id='aa', too_short=[], illegal_suffix=['沪市'], short=[], short_result=[], norm=[], norm_right=[], norm_modify=[], norm_vague=[], norm_right_result=[], norm_modify_result=[], norm_vague_result=[], too_long=[], mapping_list=[])
分流
# 分流for the_ent in ent_list2:the_ent_len = len(the_ent) if the_ent_len< 2:mr.too_short.append(the_ent)elif the_ent_len <7:mr.short.append(the_ent)elif the_ent_len < 25:mr.norm.append(the_ent)else:mr.too_long.append(the_ent)In [42]: mr
Out[42]: MultiRes(doc_id='aa', too_short=[], illegal_suffix=['沪市'], short=['基金', '美芯晟', '高新兴', '骏成科技', '证券时报', '深市主板', '创业板', '科创板', '计算机', '机械设备', '共有3', '潍柴动力', '乐心医疗', '嘉曼服饰', '敏芯股份', '渝开发', '长虹美菱', '德联集团', '数据宝', '中航西飞', '顺络电子', '基金家数', '华利集团', '杰瑞股份', '邦彦技术', '兴瑞科技', '深天马', '漫步', '金力永磁', '太阳能', '普蕊斯', '德方纳米', '华锐精密', '伊之密', '西子洁能', '陕西华达', '浙江鼎力', '诺瓦星云', '远光'], short_result=[], norm=[], norm_right=[], norm_modify=[], norm_vague=[], norm_right_result=[], norm_modify_result=[], norm_vague_result=[], too_long=[], mapping_list=[])
写着写着,我感觉可以归为一种称为 「waterfall」的模式
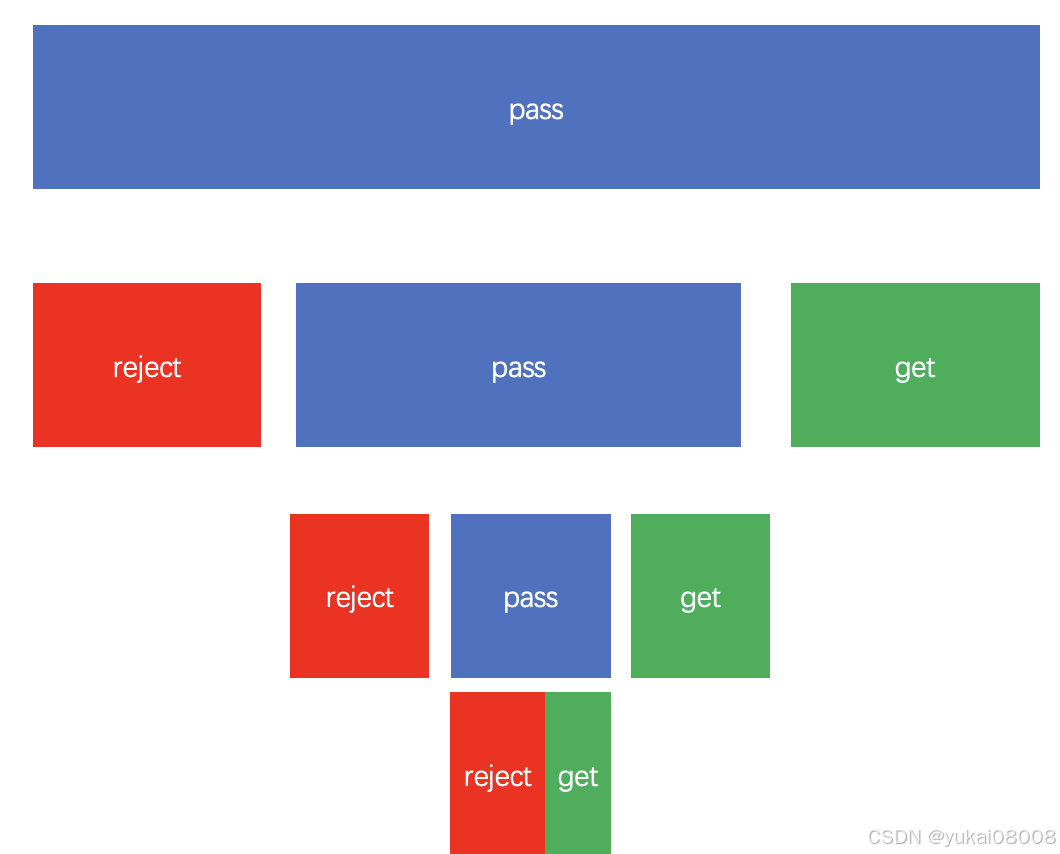
假设最初进来的数据是蓝色部分(pass),每一层的处理会分为三种情况:pass, reject和get。这样从形式上就可以完全统一起来
import json
import asyncio, aiohttpasync def json_query_worker(task_id = None , url = None , json_params = None,time_out = 320, semaphore = None):async with semaphore:try:async with aiohttp.ClientSession() as session:async with session.post(url, json = {**json_params},timeout=aiohttp.ClientTimeout(total=time_out)) as response:res = await response.text()return {task_id: json.loads(res)}except json.JSONDecodeError as e:print({task_id: f"JSONDecodeError: {e}"})return Noneexcept Exception as e:print({task_id: f"Exception: {e}"})return Noneasync def json_player(task_list , concurrent = 3):semaphore = asyncio.Semaphore(concurrent) # 并发限制tasks = [asyncio.ensure_future(json_query_worker(**x, semaphore = semaphore)) for x in task_list]return await asyncio.gather(*tasks)# 接口返回数据模型 v {status: pass/reject/get , data:None 或者匹配全称}
# mapping_list 仅用于本次,不是通用设计
# raw 也是如此
import time
def waterfall_api_mode(last_fall, rule_name ,reject_list = None, get_list = None, mappling_list = None, raw = None , base_url = None):next_fall = []last_ent_list = last_fall pure_rule_url = rule_name + '/'if len(last_ent_list):rule_url = base_url + pure_rule_url# api modetick1 = time.time()task_list = []for ent in last_ent_list:tem_dict = {}tem_dict['task_id'] = ent tem_dict['url'] = rule_urlif raw is None :tem_dict['json_params'] = {'some_ent':ent}else:tem_dict['json_params'] = {'some_ent':ent,'raw':raw}task_list.append(tem_dict)rule_res = asyncio.run(json_player(task_list, concurrent = 100))# 解析结果,保留passfor tem_res in rule_res:for k,v in tem_res.items():# print(k,v)if v['status'] == 'pass':next_fall.append(k)elif v['status'] == 'get':if get_list is not None :get_list.append(v['data'])if mappling_list is not None :mappling_list.append({'ent':k,'mapping_ent': v['data']})elif v['status'] == 'reject':if reject_list is not None :reject_list.append(k)tick2 = time.time()print('takes %.2f ' %(tick2-tick1))return next_fall
这样在运行规则时形式上会高度统一:
这次是事后调整,所以有些地方明显不是最优的。例如worker在并发时可以直接修改全局对象,而不是在处理完之后再进行合并。
2.3 等价校验
在并行化改造之后,需要进行结果校验才能切换。由于这部分内容不改变内容,仅仅是做运行效率的提升,所以结果可以直接使用程序进行比对。
方法:
- 1 随机抽取100-10000篇文档处理
- 2 分别采取串行和并行服务处理,结果直接进行等价判断
- 3 如果在随机一万的程度都没有差异,则可以替换
相关文章:
建模杂谈系列252 规则的串行改并行
说明 提到规则,还是需要看一眼RETE算法: Rete算法是一种用于高效处理基于规则的系统中的模式匹配问题的算法,广泛应用于专家系统、推理引擎和生产系统。它的设计目的是在大量规则和数据的组合中快速找到满足特定规则条件的模式。 Rete算法…...

0.ffmpeg面向对象oopc
因为查rtsp相关问题,接触了下ffmpeg源码,发现它和linux内核一样,虽然都是c写的,但是都是面向对象的思想,c的面向对象称之为oopc。 这让我想起来一件好玩的事,有些搞linux内核驱动的只会c的开发人员不知道l…...

KDD2024参会笔记-Day1
知乎想法:链接 听的第一场汇报:RAG Meeting LLMs 综述论文:https://arxiv.org/pdf/2405.06211 PPT:https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/2024-KDD-RAG-Meets-LLM-tutorial-Part1.pdf 检索࿱…...

Java操作Elasticsearch的实用指南
Java操作Elasticsearch的实用指南 一、创建索引二、增删改查 一、创建索引 在ElasticSearch中索引相当于mysql中的表,mapping相当于表结构,所以第一步我们要先创建索引。 假设我们有一张文章表的数据需要同步到ElasticSearch,首先需要根据数据库表创建…...

数据库系统 第42节 数据库索引简介
数据库索引是数据库表中一个或多个列的数据结构,用于加快数据检索速度。除了基础的B-Tree索引,其他类型的索引针对特定的数据类型和查询模式提供了优化。以下是几种不同类型的索引及其使用场景的详细说明和示例代码。 1. 位图索引 (Bitmap Index) 位图…...

C++11 --- 智能指针
序言 在使用 C / C 进行编程时,许多场景都需要我们在堆上申请空间,堆内存的申请和释放都需要我们自己进行手动管理。这就存在容易造成堆内存泄露(忘记释放),二次释放,程序发生异常时内存泄露等问题…...

C#顺序万年历自写的求余函数与周位移算法
static int 返回月的天数(int 年, int 月){return (月 2 ?(((年 % 4 0 && 年 % 100 > 0) || 年 % 400 0) ? 29 : 28) :(((月 < 7 && 月 % 2 > 0) || (月 > 7 && 月 % 2 0)) ? 31 : 30));}static int 返回年总天数(int 年, int 标 …...

【Java并发编程一】八千字详解多线程
目录 多线程基础 1.线程和进程 线程是什么? 为啥要有线程? 进程和线程的区别? Java 的线程 和 操作系统线程 的关系 使用jconsole观察线程 2.创建线程的多种方式 3.Thread类及其常见方法 Thread类的常见构造方法 Thread类的常见属性…...

CentOS 8FTP服务器
FTP(文件传输协议)是一种客户端-服务器网络协议,允许用户在远程计算机之间传输文件。这里有很多可用于Linux的开源FTP服务软件,最流行最常用的FTP服务软件有 PureFTPd, ProFTPD, 和 vsftpd。在本教程中,我们将在CentOS…...

C++ | Leetcode C++题解之第385题迷你语法分析器
题目: 题解: class Solution { public:NestedInteger deserialize(string s) {if (s[0] ! [) {return NestedInteger(stoi(s));}stack<NestedInteger> st;int num 0;bool negative false;for (int i 0; i < s.size(); i) {char c s[i];if …...

【软件设计师真题】第一大题---数据流图设计
解答数据流图的题目关键在于细心。 考试时一定要仔细阅读题目说明和给出的流程图。另外,解题时要懂得将说明和流程图进行对照,将父图和子图进行对照,切忌按照常识来猜测。同时应按照一定顺序考虑问题,以防遗漏,比如可以…...

系统架构的发展历程之模块化与组件化
模块化开发方法 模块化开发方法是指把一个待开发的软件分解成若干个小的而且简单的部分,采用对复杂事物分而治之的经典原则。模块化开发方法涉及的主要问题是模块设计的规则,即系统如何分解成模块。而每一模块都可独立开发与测试,最后再组装…...
基因组学中的深度学习
----/ START /---- 基因组学其实是一门将数据驱动作为主要研究手段的学科,机器学习方法和统计学方法在基因组学中的应用一直都比较广泛。 不过现在多组学数据进一步激增——这个从目前逐渐增多的各类大规模人群基因组项目上可以看出来,这其实带来了新的挑…...

解决老师询问最高分数问题的编程方案
解决老师询问最高分数问题的编程方案 问题分析数据结构选择:线段树线段树的基本操作伪代码伪代码:构建线段树伪代码:更新操作伪代码:查询操作C语言实现代码详细解释在日常教学中,老师经常需要查询某一群学生中的最高分数,并有时会更新某位同学的成绩。为了实现这一功能,…...

com.baomidou.mybatisplus.annotation.DbType 无法引入
com.baomidou.mybatisplus.annotation.DbType 无法引入爆红 解决 解决 ❤️ 3.4.1 是mybatis-plus版本,根据实际的配置→版本一致 <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-annotation</artifactId>&…...

从零开始学习JVM(七)- StringTable字符串常量池
1 概述 String应该是Java使用最多的类吧,很少有Java程序没有使用到String的。在Java中创建对象是一件挺耗费性能的事,而且我们又经常使用相同的String对象,那么创建这些相同的对象不是白白浪费性能吗。所以就有了StringTable这一特殊的存在&…...

数据库课程设计mysql
进行 MySQL 数据库课程设计通常包括以下几个步骤,从需求分析到数据库设计和实现。以下是一个常见的流程及要点: 1. 需求分析 首先,明确系统的功能需求。这包括用户需求、业务流程、功能模块等。你需要与相关人员(比如老师、同学…...

AI学习指南深度学习篇-带动量的随机梯度下降法的基本原理
AI学习指南深度学习篇——带动量的随机梯度下降法的基本原理 引言 在深度学习中,优化算法被广泛应用于训练神经网络模型。随机梯度下降法(SGD)是最常用的优化算法之一,但单独使用SGD在收敛速度和稳定性方面存在一些问题。为了应…...

点餐小程序实战教程03创建应用
目录 1 创建应用2 第一部分侧边栏3 第二部分页面功能区4 第三部分大纲树5 第四部分代码区6 第五部分模式切换7 第六部分编辑区域8 第七部分组件区域9 第八部分,发布区域10 第九部分开发调试和高阶配置总结 上一篇我们介绍了如何实现后端API,介绍了登录验…...

鸿蒙自动化发布测试版本app
创建API客户端 API客户端是AppGallery Connect用于管理用户访问AppGallery Connect API的身份凭据,您可以给不同角色创建不同的API客户端,使不同角色可以访问对应权限的AppGallery Connect API。在访问某个API前,必须创建有权访问该API的API…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

Unity动态自然系统:Forest Environment-Dynamic Nature深度解析
1. 这不是“贴图堆砌”,而是自然系统级建模:Forest Environment-Dynamic Nature 的真实定位你有没有试过在Unity里拖进几棵树、铺点草、加个天空盒,然后发现场景像一张静止的风景明信片——风不动、叶不摇、雨不落、雾不散?我做过…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...

Android Root检测绕过:从逆向分析到Frida分层Hook实战
1. 这不是“绕过root检测”,而是理解检测逻辑后的精准干预在安卓逆向工程的实际工作中,“过root检测”这个说法本身就容易引发误解——它听起来像某种黑箱魔法,仿佛只要套用某个脚本、加载某个插件,就能让App对设备状态“视而不见…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...