Java操作Elasticsearch的实用指南
Java操作Elasticsearch的实用指南
- 一、创建索引
- 二、增删改查
一、创建索引
在ElasticSearch中索引相当于mysql中的表,mapping相当于表结构,所以第一步我们要先创建索引。
- 假设我们有一张文章表的数据需要同步到ElasticSearch,首先需要根据数据库表创建ES的索引结构。
-- 文章表
create table if not exists post
(id bigint auto_increment comment 'id' primary key,title varchar(512) null comment '标题',content text null comment '内容',tags varchar(1024) null comment '标签列表(json 数组)',thumbNum int default 0 not null comment '点赞数',favourNum int default 0 not null comment '收藏数',userId bigint not null comment '创建用户 id',createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',isDelete tinyint default 0 not null comment '是否删除',index idx_userId (userId)
) comment '帖子' collate = utf8mb4_unicode_ci;ElasticSearch的索引结构:
- aliases:别名(为了方便后续数据迁移)
- 字段类型是text,这个字段可以被分词,可模糊查询;字段类型是keyword,只能完全匹配,精确查询。
- analyzer(存储时生效的分词器):用ik_max_word,拆的更碎、索引更多,更有可能被搜出来
- search analyzer (查询时生效的分词器):用ik_smart,更偏向于用户想要搜的分词。
PUT post
{"aliases": {"post": {}},"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"tags": {"type": "keyword"},"userId": {"type": "keyword"},"createTime": {"type": "date"},"updateTime": {"type": "date"},"isDelete": {"type": "keyword"}}}
}

二、增删改查
使用java客户端进行增删改查,第一步导入依赖。
<!-- elasticsearch--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>
- 第一种方式: ElasticsearchRepository<PostEsDTO,Long>,默认提供了简单的增删改查,多用于可预期的、相对没那么复杂的查询、自定义查询。

@Testvoid testSelect() {System.out.println(postEsDao.count());Page<PostEsDTO> PostPage = postEsDao.findAll(PageRequest.of(0, 5, Sort.by("createTime")));List<PostEsDTO> postList = PostPage.getContent();System.out.println(postList);}@Testvoid testAdd() {PostEsDTO postEsDTO = new PostEsDTO();postEsDTO.setId(1L);postEsDTO.setTitle("我是章三");postEsDTO.setContent("张三学习java,学习使我快乐!");postEsDTO.setTags(Arrays.asList("java", "python"));postEsDTO.setUserId(1L);postEsDTO.setCreateTime(new Date());postEsDTO.setUpdateTime(new Date());postEsDTO.setIsDelete(0);postEsDao.save(postEsDTO);System.out.println(postEsDTO.getId());}@Testvoid testFindById() {Optional<PostEsDTO> postEsDTO = postEsDao.findById(1L);System.out.println(postEsDTO);}@Testvoid testCount() {System.out.println(postEsDao.count());}@Testvoid testFindByCategory() {List<PostEsDTO> postEsDaoTestList = postEsDao.findByUserId(1L);System.out.println(postEsDaoTestList);}
ES 中,_开头的字段表示系统默认字段,比如 _id,如果系统不指定,会自动生成。但是不会在surce 字段中补充 id 的值,所以建议大家手动指定。
支持根据方法名自动生成方法,比如:
ListcPostEsDTO> findByTitle(String title);
- 第二种方式: Spring 默认给我们提供的提作 es 的客户端对象 ElasticsearchRestTemplate,也提供了增制改查,它的增删改查更灵活,适用于更复杂的操作。
ES的搜索条件:
GET /_search
{"query": { "bool": { 组合条件"must": [ 必须都满足{ "match": { "title": "Search" }}, 模糊查询 { "match": { "content": "Elasticsearch" }}],"filter": [ { "term": { "status": "published" }}, 精确查询{ "range": { "publish_date": { "gte": "2015-01-01" }}} 范围查询],"should" : [{ "term" : { "tags" : "env1" } },{ "term" : { "tags" : "deployed" } }],"minimum_should_match" : 1, 包含匹配,最少匹配1条"boost" : 1.0}}
}
对于复杂的查询,建议使用第二种方式。
//依赖注入
@Resourceprivate ElasticsearchRestTemplate elasticsearchRestTemplate;
三个步骤:
1、取参数
2、把参数组合为ES支持的搜索条件
3、从返回值中取结果
Long id = postQueryRequest.getId();Long notId = postQueryRequest.getNotId();String searchText = postQueryRequest.getSearchText();String title = postQueryRequest.getTitle();String content = postQueryRequest.getContent();List<String> tagList = postQueryRequest.getTags();List<String> orTagList = postQueryRequest.getOrTags();Long userId = postQueryRequest.getUserId();// es 起始页为 0long current = postQueryRequest.getCurrent() - 1;long pageSize = postQueryRequest.getPageSize();String sortField = postQueryRequest.getSortField();String sortOrder = postQueryRequest.getSortOrder();BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();// 过滤boolQueryBuilder.filter(QueryBuilders.termQuery("isDelete", 0));if (id != null) {boolQueryBuilder.filter(QueryBuilders.termQuery("id", id));}if (notId != null) {boolQueryBuilder.mustNot(QueryBuilders.termQuery("id", notId));}if (userId != null) {boolQueryBuilder.filter(QueryBuilders.termQuery("userId", userId));}// 必须包含所有标签if (CollectionUtils.isNotEmpty(tagList)) {for (String tag : tagList) {boolQueryBuilder.filter(QueryBuilders.termQuery("tags", tag));}}// 包含任何一个标签即可if (CollectionUtils.isNotEmpty(orTagList)) {BoolQueryBuilder orTagBoolQueryBuilder = QueryBuilders.boolQuery();for (String tag : orTagList) {orTagBoolQueryBuilder.should(QueryBuilders.termQuery("tags", tag));}orTagBoolQueryBuilder.minimumShouldMatch(1);boolQueryBuilder.filter(orTagBoolQueryBuilder);}// 按关键词检索if (StringUtils.isNotBlank(searchText)) {boolQueryBuilder.should(QueryBuilders.matchQuery("title", searchText));// boolQueryBuilder.should(QueryBuilders.matchQuery("description", searchText));boolQueryBuilder.should(QueryBuilders.matchQuery("content", searchText));boolQueryBuilder.minimumShouldMatch(1);}// 按标题检索if (StringUtils.isNotBlank(title)) {boolQueryBuilder.should(QueryBuilders.matchQuery("title", title));boolQueryBuilder.minimumShouldMatch(1);}// 按内容检索if (StringUtils.isNotBlank(content)) {boolQueryBuilder.should(QueryBuilders.matchQuery("content", content));boolQueryBuilder.minimumShouldMatch(1);}// 排序SortBuilder<?> sortBuilder = SortBuilders.scoreSort();if (StringUtils.isNotBlank(sortField)) {sortBuilder = SortBuilders.fieldSort(sortField);sortBuilder.order(CommonConstant.SORT_ORDER_ASC.equals(sortOrder) ? SortOrder.ASC : SortOrder.DESC);}// 分页PageRequest pageRequest = PageRequest.of((int) current, (int) pageSize);// 构造查询NativeSearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(boolQueryBuilder).withPageable(pageRequest).withSorts(sortBuilder).build();SearchHits<PostEsDTO> searchHits = elasticsearchRestTemplate.search(searchQuery, PostEsDTO.class);
后记
👉👉💕💕美好的一天,到此结束,下次继续努力!欲知后续,请看下回分解,写作不易,感谢大家的支持!! 🌹🌹🌹
相关文章:
Java操作Elasticsearch的实用指南
Java操作Elasticsearch的实用指南 一、创建索引二、增删改查 一、创建索引 在ElasticSearch中索引相当于mysql中的表,mapping相当于表结构,所以第一步我们要先创建索引。 假设我们有一张文章表的数据需要同步到ElasticSearch,首先需要根据数据库表创建…...

数据库系统 第42节 数据库索引简介
数据库索引是数据库表中一个或多个列的数据结构,用于加快数据检索速度。除了基础的B-Tree索引,其他类型的索引针对特定的数据类型和查询模式提供了优化。以下是几种不同类型的索引及其使用场景的详细说明和示例代码。 1. 位图索引 (Bitmap Index) 位图…...

C++11 --- 智能指针
序言 在使用 C / C 进行编程时,许多场景都需要我们在堆上申请空间,堆内存的申请和释放都需要我们自己进行手动管理。这就存在容易造成堆内存泄露(忘记释放),二次释放,程序发生异常时内存泄露等问题…...

C#顺序万年历自写的求余函数与周位移算法
static int 返回月的天数(int 年, int 月){return (月 2 ?(((年 % 4 0 && 年 % 100 > 0) || 年 % 400 0) ? 29 : 28) :(((月 < 7 && 月 % 2 > 0) || (月 > 7 && 月 % 2 0)) ? 31 : 30));}static int 返回年总天数(int 年, int 标 …...

【Java并发编程一】八千字详解多线程
目录 多线程基础 1.线程和进程 线程是什么? 为啥要有线程? 进程和线程的区别? Java 的线程 和 操作系统线程 的关系 使用jconsole观察线程 2.创建线程的多种方式 3.Thread类及其常见方法 Thread类的常见构造方法 Thread类的常见属性…...

CentOS 8FTP服务器
FTP(文件传输协议)是一种客户端-服务器网络协议,允许用户在远程计算机之间传输文件。这里有很多可用于Linux的开源FTP服务软件,最流行最常用的FTP服务软件有 PureFTPd, ProFTPD, 和 vsftpd。在本教程中,我们将在CentOS…...

C++ | Leetcode C++题解之第385题迷你语法分析器
题目: 题解: class Solution { public:NestedInteger deserialize(string s) {if (s[0] ! [) {return NestedInteger(stoi(s));}stack<NestedInteger> st;int num 0;bool negative false;for (int i 0; i < s.size(); i) {char c s[i];if …...

【软件设计师真题】第一大题---数据流图设计
解答数据流图的题目关键在于细心。 考试时一定要仔细阅读题目说明和给出的流程图。另外,解题时要懂得将说明和流程图进行对照,将父图和子图进行对照,切忌按照常识来猜测。同时应按照一定顺序考虑问题,以防遗漏,比如可以…...

系统架构的发展历程之模块化与组件化
模块化开发方法 模块化开发方法是指把一个待开发的软件分解成若干个小的而且简单的部分,采用对复杂事物分而治之的经典原则。模块化开发方法涉及的主要问题是模块设计的规则,即系统如何分解成模块。而每一模块都可独立开发与测试,最后再组装…...
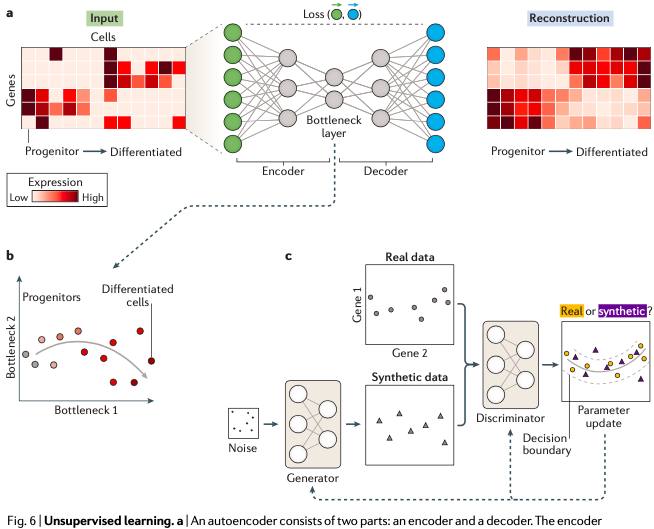
基因组学中的深度学习
----/ START /---- 基因组学其实是一门将数据驱动作为主要研究手段的学科,机器学习方法和统计学方法在基因组学中的应用一直都比较广泛。 不过现在多组学数据进一步激增——这个从目前逐渐增多的各类大规模人群基因组项目上可以看出来,这其实带来了新的挑…...

解决老师询问最高分数问题的编程方案
解决老师询问最高分数问题的编程方案 问题分析数据结构选择:线段树线段树的基本操作伪代码伪代码:构建线段树伪代码:更新操作伪代码:查询操作C语言实现代码详细解释在日常教学中,老师经常需要查询某一群学生中的最高分数,并有时会更新某位同学的成绩。为了实现这一功能,…...

com.baomidou.mybatisplus.annotation.DbType 无法引入
com.baomidou.mybatisplus.annotation.DbType 无法引入爆红 解决 解决 ❤️ 3.4.1 是mybatis-plus版本,根据实际的配置→版本一致 <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-annotation</artifactId>&…...

从零开始学习JVM(七)- StringTable字符串常量池
1 概述 String应该是Java使用最多的类吧,很少有Java程序没有使用到String的。在Java中创建对象是一件挺耗费性能的事,而且我们又经常使用相同的String对象,那么创建这些相同的对象不是白白浪费性能吗。所以就有了StringTable这一特殊的存在&…...

数据库课程设计mysql
进行 MySQL 数据库课程设计通常包括以下几个步骤,从需求分析到数据库设计和实现。以下是一个常见的流程及要点: 1. 需求分析 首先,明确系统的功能需求。这包括用户需求、业务流程、功能模块等。你需要与相关人员(比如老师、同学…...

AI学习指南深度学习篇-带动量的随机梯度下降法的基本原理
AI学习指南深度学习篇——带动量的随机梯度下降法的基本原理 引言 在深度学习中,优化算法被广泛应用于训练神经网络模型。随机梯度下降法(SGD)是最常用的优化算法之一,但单独使用SGD在收敛速度和稳定性方面存在一些问题。为了应…...

点餐小程序实战教程03创建应用
目录 1 创建应用2 第一部分侧边栏3 第二部分页面功能区4 第三部分大纲树5 第四部分代码区6 第五部分模式切换7 第六部分编辑区域8 第七部分组件区域9 第八部分,发布区域10 第九部分开发调试和高阶配置总结 上一篇我们介绍了如何实现后端API,介绍了登录验…...

鸿蒙自动化发布测试版本app
创建API客户端 API客户端是AppGallery Connect用于管理用户访问AppGallery Connect API的身份凭据,您可以给不同角色创建不同的API客户端,使不同角色可以访问对应权限的AppGallery Connect API。在访问某个API前,必须创建有权访问该API的API…...

力扣9.7
115.不同的子序列 题目 给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数,结果需要对 109 7 取模。 数据范围 1 < s.length, t.length < 1000s 和 t 由英文字母组成 分析 令dp[i][j]为s的前i个字符构成的子序列中为t的前j…...

GPU 带宽功耗优化
移动端GPU 的内存结构: 先简述移动端内存cache结构;上图的UMA结构 on-Chip memory 包括了 L1、L2 cache,非常关键的移动端的 Tiles 也是保存在 on-chip上还包括寄存器文件:提供给每个核心使用的极高速存储。 共享内存(…...

Linux Centos 7网络配置
本步骤基于Centos 7,使用的虚拟机是VMware Workstation Pro,最终可实现虚拟机与外网互通。如为其他发行版本的linux,可能会有差异。 1、检查外网访问状态 ping www.baidu.com 2、查看网卡配置信息 ip addr 3、配置网卡 cd /etc/sysconfig…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...
)
用ESP32-C3的PWM做个RGB呼吸灯吧:从配置结构体到色彩渐变(乐鑫ESP-IDF实战)
ESP32-C3 RGB呼吸灯实战:从PWM配置到色彩渐变算法 当智能家居的灯光不再只是简单的开关控制,而是能像呼吸般自然渐变时,整个空间的氛围立刻变得生动起来。ESP32-C3凭借其出色的LED PWM控制器(LEDC)外设,为开…...

智能烹饪助手:基于传感器融合与AI的厨房自动化实践
1. 项目概述:一个让厨房小白也能自信下厨的智能伙伴每次站在灶台前,你是不是也经历过这样的场景:一边手忙脚乱地翻着菜谱,一边担心锅里的菜是不是快糊了,还要分心去计算各种调料该放多少?对于很多刚接触烹饪…...

三分钟快速上手:FanControl让你的电脑风扇从此安静又高效
三分钟快速上手:FanControl让你的电脑风扇从此安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...