【Llamaindex RAG实践】
基础任务 (完成此任务即完成闯关)
- 任务要求:基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前InternLM2-Chat-1.8B模型不会回答,借助 LlamaIndex 后 InternLM2-Chat-1.8B 模型具备回答 A 的能力,截图保存。

llamaindex+Internlm2 RAG实践
本文将分为以下几个部分来介绍,如何使用 LlamaIndex 来部署 InternLM2 1.8B(以 InternStudio 的环境为例)
- 前置知识
- 环境、模型准备
- LlamaIndex HuggingFaceLLM
- LlamaIndex RAG
1. 前置知识
正式介绍检索增强生成(Retrieval Augmented Generation,RAG)技术以前,大家不妨想想为什么会出现这样一个技术。 给模型注入新知识的方式,可以简单分为两种方式,一种是内部的,即更新模型的权重,另一个就是外部的方式,给模型注入格外的上下文或者说外部信息,不改变它的的权重。 第一种方式,改变了模型的权重即进行模型训练,这是一件代价比较大的事情,大语言模型具体的训练过程,可以参考InternLM2技术报告。第二种方式,并不改变模型的权重,只是给模型引入格外的信息。类比人类编程的过程,第一种方式相当于你记住了某个函数的用法,第二种方式相当于你阅读函数文档然后短暂的记住了某个函数的用法。
RAG 效果比对
如图所示,由于xtuner是一款比较新的框架, InternLM2-Chat-1.8B 训练数据库中并没有收录到它的相关信息。左图中问答均未给出准确的答案。右图未对 InternLM2-Chat-1.8B 进行任何增训的情况下,通过 RAG 技术实现的新增知识问答。
进入开发机后,创建新的conda环境,命名为 llamaindex,在命令行模式下运行:
conda create -n llamaindex python=3.10
复制完成后,在本地查看环境。
conda env list
结果如下所示。
# conda environments: # base * /root/.conda llamaindex /root/.conda/envs/llamaindex
运行 conda 命令,激活 llamaindex 然后安装相关基础依赖 python 虚拟环境:
conda activate llamaindex conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
安装python 依赖包
pip install einops==0.7.0 protobuf==5.26.1
环境激活后,命令行左边会显示当前(也就是 llamaindex )的环境名称,如下图所示:

2.2 安装 Llamaindex
安装 Llamaindex和相关的包
conda activate llamaindex pip install llama-index==0.10.38 llama-index-llms-huggingface==0.2.0 "transformers[torch]==4.41.1" "huggingface_hub[inference]==0.23.1" huggingface_hub==0.23.1 sentence-transformers==2.7.0 sentencepiece==0.2.0
2.3 下载 Sentence Transformer 模型
源词向量模型 Sentence Transformer:(我们也可以选用别的开源词向量模型来进行 Embedding,目前选用这个模型是相对轻量、支持中文且效果较好的,同学们可以自由尝试别的开源词向量模型) 运行以下指令,新建一个python文件
cd ~ mkdir llamaindex_demo mkdir model cd ~/llamaindex_demo touch download_hf.py
打开download_hf.py 贴入以下代码
import os# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/model/sentence-transformer')
然后,在 /root/llamaindex_demo 目录下执行该脚本即可自动开始下载:
cd /root/llamaindex_demo conda activate llamaindex python download_hf.py
更多关于镜像使用可以移步至 HF Mirror 查看。
2.4 下载 NLTK 相关资源
我们在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。 我们用以下命令下载 nltk 资源并解压到服务器上:
cd /root git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages cd nltk_data mv packages/* ./ cd tokenizers unzip punkt.zip cd ../taggers unzip averaged_perceptron_tagger.zip
之后使用时服务器即会自动使用已有资源,无需再次下载
3. LlamaIndex HuggingFaceLLM
运行以下指令,把 InternLM2 1.8B 软连接出来
cd ~/model ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/ ./
运行以下指令,新建一个python文件
cd ~/llamaindex_demo touch llamaindex_internlm.py
打开llamaindex_internlm.py 贴入以下代码
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.llms import ChatMessage
llm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code":True},tokenizer_kwargs={"trust_remote_code":True}
)rsp = llm.chat(messages=[ChatMessage(content="xtuner是什么?")])
print(rsp)
之后运行
conda activate llamaindex cd ~/llamaindex_demo/ python llamaindex_internlm.py
结果为:
回答的效果并不好,并不是我们想要的xtuner。
4. LlamaIndex RAG
安装 LlamaIndex 词嵌入向量依赖
conda activate llamaindex pip install llama-index-embeddings-huggingface==0.2.0 llama-index-embeddings-instructor==0.1.3
运行以下命令,获取知识库
cd ~/llamaindex_demo mkdir data cd data git clone https://github.com/InternLM/xtuner.git mv xtuner/README_zh-CN.md ./
运行以下指令,新建一个python文件
cd ~/llamaindex_demo touch llamaindex_RAG.py
打开llamaindex_RAG.py贴入以下代码
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settingsfrom llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_modelllm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code":True},tokenizer_kwargs={"trust_remote_code":True}
)
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("xtuner是什么?")print(response)
之后运行
conda activate llamaindex cd ~/llamaindex_demo/ python llamaindex_RAG.py
结果为:

借助RAG技术后,就能获得我们想要的答案了。
5. LlamaIndex web
运行之前首先安装依赖
pip install streamlit==1.36.0
运行以下指令,新建一个python文件
cd ~/llamaindex_demo touch app.py
打开app.py贴入以下代码
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLMst.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")# 初始化模型
@st.cache_resource
def init_models():embed_model = HuggingFaceEmbedding(model_name="/root/model/sentence-transformer")Settings.embed_model = embed_modelllm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code": True},tokenizer_kwargs={"trust_remote_code": True})Settings.llm = llmdocuments = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()index = VectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine()return query_engine# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:st.session_state['query_engine'] = init_models()def greet2(question):response = st.session_state['query_engine'].query(question)return response# Store LLM generated responses
if "messages" not in st.session_state.keys():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}] # Display or clear chat messages
for message in st.session_state.messages:with st.chat_message(message["role"]):st.write(message["content"])def clear_chat_history():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]st.sidebar.button('Clear Chat History', on_click=clear_chat_history)# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):return greet2(prompt_input)# User-provided prompt
if prompt := st.chat_input():st.session_state.messages.append({"role": "user", "content": prompt})with st.chat_message("user"):st.write(prompt)# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":with st.chat_message("assistant"):with st.spinner("Thinking..."):response = generate_llama_index_response(prompt)placeholder = st.empty()placeholder.markdown(response)message = {"role": "assistant", "content": response}st.session_state.messages.append(message)
之后运行
streamlit run app.py
然后在命令行点击,红框里的url。

即可进入以下网页,然后就可以开始尝试问问题了。
询问结果为:

相关文章:
【Llamaindex RAG实践】
基础任务 (完成此任务即完成闯关) 任务要求:基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前InternLM2-Chat-1.8B模型不会回答,借助 LlamaIndex 后 InternLM2-Chat-1.8B 模型具备回答 A 的能力,截…...
[Linux]:线程(三)
✨✨ 欢迎大家来到贝蒂大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:Linux学习 贝蒂的主页:Betty’s blog 1. POSIX 信号量 1.1 信号量的概念 为了解决多执行流访问临界区,…...

云原生(四十一) | 阿里云ECS服务器介绍
文章目录 阿里云ECS服务器介绍 一、云计算概述 二、什么是公有云 三、公有云优缺点 1、优点 2、缺点 四、公有云品牌 五、市场占有率 六、阿里云ECS概述 七、阿里云ECS特点 阿里云ECS服务器介绍 一、云计算概述 云计算是一种按使用量付费的模式,这种模式…...

qemu-system-aarch64开启user用户模式网络连接
一、问题 在使用qemu构建arm64的虚拟机时,虚拟机没有网络,桥接方式相对麻烦,我只是需要联网更新即可。与宿主机的通信我使用共享文件夹即可满足要求。 使用指令启动虚拟机时,网络部分的参数为 -net user,hostfwdtcp::10022-:22 …...

Android车载——VehicleHal初始化(Android 11)
1 概述 VehicleHal是AOSP中车辆服务相关的hal层服务。它主要定义了与汽车硬件交互的标准化接口和属性管理,是一个独立的进程。 2 进程启动 VehicleHal相关代码在源码树中的hardware/interfaces/automotive目录下 首先看下Android.bp文件: cc_binary …...

CTFshow 命令执行 web37-web40
目录 web37 方法一:php://input 方法二:data协议 web38 web39 web40 方法一:构造文件读取 方法二:构造数组rce web37 error_reporting(0); if(isset($_GET[c])){$c $_GET[c];if(!preg_match("/flag/i", $c)){incl…...
码 进制))
数据结构与算法篇((原/反/补)码 进制)
目录 讲解一:原/反/补)码 一、原码 二、反码 三、补码 四、有符号位整型 五、无符号位整型 六、Java中的整型 七、整数在底层存储形式 讲解二:进制 一、简介 二、常用的进制 十进制 二进制 八进制 十六进制 知识补充 三、进制转换 1. 二…...

Python画笔案例-077 绘制 颜色饱和度测试
1、绘制 颜色饱和度测试 通过 python 的turtle 库绘制 颜色饱和度测试,如下图: 2、实现代码 绘制 颜色饱和度测试,以下为实现代码: """饱和度渐变示例,本程序需要coloradd模块支持,请在cmd窗口,即命令提示符下输入pip install coloradd进行安装。本程序演…...

简历投递经验01
嵌入式简历制作指南与秋招求职建议 技术要求概览 在嵌入式领域求职时,技术能力是HR和面试官最关注的点之一。以下是一些关键技术点,以及它们在简历中的体现方式。 1. 编程语言与开发环境 掌握C/C语言。熟悉至少一种单片机或微处理器的开发环境。 2.…...

数据和算力共享
数据和算力共享 针对数字化应用实践中需要在不同的物理域和信息域中进行数据的访问交换以及共享计算等需求,本文分析了在数据平台、数据集成系统以及信息交换系统中存在的问题。 在基于联邦学习的基础上,提出一种跨域数据计算共享系统,能够同时共享数据和计算资源,并支持在线…...

SpringBoot 集成 Ehcache 实现本地缓存
目录 1、Ehcache 简介2、Ehcache 集群方式3、工作原理3.1、缓存写入3.2、缓存查找3.3、缓存过期和驱逐3.4、缓存持久化 4、入门案例 —— Ehcache 2.x 版本4.1、单独使用 Ehcache4.1.1、引入依赖4.1.2、配置 Ehcache4.1.2.1、XML 配置方式4.1.2.1.1、新建 ehcache.xml4.1.2.1.2…...

CSP-J 复赛真题 P9749 [CSP-J 2023] 公路
文章目录 前言[CSP-J 2023] 公路题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示 示例代码代码解析思考过程总结 总结 前言 在CSP-J 2023的复赛中,出现了一道引人注目的题目——“公路”。这道题目不仅考察了选手们对算法的理解和运用能力,…...

MeterSphere压测配置说明
在MeterSphere中,执行性能测试时的配置参数对测试结果有重要影响。以下是对MeterSphere压测配置中几个关键参数的解释: 执行方式:决定了测试的执行模式,例如可以按照持续时间或迭代次数来执行测试。 按持续时间:在这种…...

数据库软题6.1-关系模式-关系模式的各种键
关系模式的各种键 题1-由关系模式求候选键 1. 候选键唯一不冗余 对选项进行闭包运算,如果得到全部属性U,则为候选码 A:AC-ABC-ABCD B:AB-ABC-ABCD C:AE-ABE-ABCE -ABCDE-ABCDEH D:DE2. R的候选码可以从A1,A2,A3,A1A2,A1A3,A2A3,A1A2A3中选择ÿ…...

ulimit:资源限制
一、命令简介 ulimit 是一个用于资源管理的工具,对于确保系统资源的合理分配和安全使用至关重要。 使用场景: 系统管理:限制用户进程使用的资源,防止资源滥用,保证系统稳定。调试:调整核心文件大…...

解决Python使用Selenium 时遇到网页 <body> 划不动的问题
如果在使用 Selenium 时遇到网页的 <body> 划不动的问题,这通常是因为页面的滚动机制(例如,可能使用了一个具有固定高度的容器或自定义的滚动条)导致无法通过简单的 JavaScript 实现滚动。可以通过以下方法来解决该问题。 …...

pytorch版本和cuda版本不匹配问题
文章目录 🌕问题:Python11.8安装pytorch11.3失败🌕CUDA版本和pytorch版本的关系🌕安装Pytorch2.0.0🌙pip方法🌙cuda方法 🌕问题:Python11.8安装pytorch11.3失败 🌕CUDA版…...

Vue/组件的生命周期
这篇文章借鉴了coderwhy大佬的Vue生命周期 在Vue实例化或者创建组件的过程中 内部涉及到一系列复杂的阶段 每一个阶段的前后时机都可能对应一个钩子函数 以下是我根据coderwhy大佬文章对于每一个阶段的一些看法 1.过程一 首先实例化Vue或者组件 在实例化之前 会对应一个钩子函…...

【Nacos架构 原理】内核设计之Nacos寻址机制
文章目录 前提设计内部实现单机寻址文件寻址地址服务器寻址 前提 对于集群模式,集群内的每个Nacos成员都需要相互通信。因此这就带来一个问题,该以何种方式去管理集群内部的Nacos成员节点信息,即Nacos内部的寻址机制。 设计 要能够感知到节…...
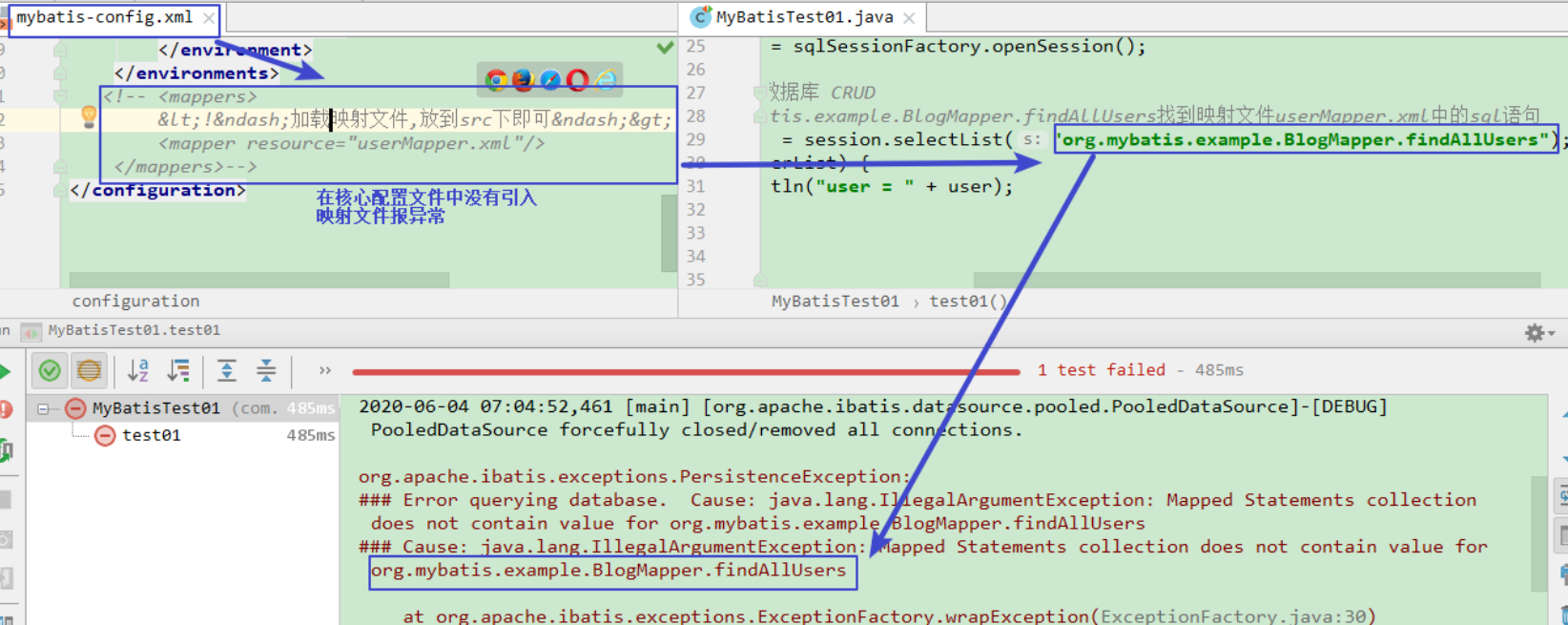
入门案例:mybatis流程,核心,常见错误
入门案例:mybatis执行流程分析 说明: 1.第一步:是从核心配置文件mybatis-config.xml中构建SqlSessionFactory对象,由于核心配置文件mybatis-config.xml中关联了映射文件UserMapper.xml,所以在SqlSessionFactory中也存在映射文件的…...

技术视角:分布式投票系统的异步解耦架构与多语言协同实践
技术视角:分布式投票系统的异步解耦架构与多语言协同实践 【免费下载链接】example-voting-app Example Docker Compose app 项目地址: https://gitcode.com/gh_mirrors/exa/example-voting-app 在当今企业级应用架构设计中,如何平衡高并发处理、…...

IDEA 2018.2.3 下 Maven 依赖包消失?别慌,可能是版本兼容性在作祟
IDEA 2018.2.3 下 Maven 依赖包消失的深度排查指南 当你打开一个尘封已久的老项目,准备继续维护或迁移时,突然发现IDEA的External Libraries里空空如也,只剩下孤零零的JDK包,整个项目文件一片飘红——这种场景对许多维护历史代码库…...

告别手动框选!用SUSTechPOINTS的V键批量标注,5分钟搞定一帧点云
解锁SUSTechPOINTS的V键批量标注:点云处理效率革命 在自动驾驶与机器人研发领域,点云标注是构建高精度感知模型的基础环节,但传统逐帧手动标注方式往往成为项目进度的瓶颈。我曾参与过一个城市级点云数据集标注项目,团队最初采用常…...

避坑指南:在Unity 2022 LTS中配置XCharts插件时遇到的3个常见问题及解决方法
Unity 2022 LTS中XCharts插件实战避坑手册 当数据可视化成为现代应用的核心需求时,Unity开发者常会选择XCharts这类开源图表插件来快速实现专业级图表展示。但在实际项目落地过程中,版本兼容性、环境配置和平台适配等问题往往会让开发进程意外卡壳。本文…...

MQ-3与MiCS-5524气体传感器对比:从原理到实战的选型指南
1. 项目概述与核心价值在嵌入式开发、环境监测乃至一些创意DIY项目中,气体检测是一个常见且关键的需求。无论是为了安全预警(如天然气泄漏),还是进行环境质量评估(如VOC监测),选择一款合适的传感…...

量子误差缓解:Bhattacharyya距离与保形预测的应用
1. 量子噪声与误差缓解的核心挑战在当前的NISQ(Noisy Intermediate-Scale Quantum)时代,量子计算机面临的最大障碍就是噪声和误差问题。这些噪声主要来源于量子比特与环境之间的相互作用、门操作的不完美性以及测量误差等。以一个典型的超导量…...
pydantic-settings、核心BaseModel、字段约束Field()、FastAPI)
Python Pydantic介绍(数据校验、自动类型转换、结构化数据建模、序列化JSON、配置管理)pydantic-settings、核心BaseModel、字段约束Field()、FastAPI
文章目录Python 数据校验神器:Pydantic 完全指南一、什么是 Pydantic二、Pydantic 能解决什么问题1)数据校验(Validation)2)自动类型转换(Parsing)3)结构化数据建模4)序列…...

Linux内核C11升级:从C89到现代C语言的演进与挑战
1. 项目概述:一次内核语言的“心脏移植”手术最近Linux内核社区放出了一个重磅消息,未来计划将内核的C语言标准从使用了二十多年的C89/C90,升级到C11。这个消息一出,在开发者圈子里激起的讨论,不亚于当年从Python 2迁移…...

量子纠错程序的形式化验证方法与工程实践
1. 量子纠错程序验证的核心挑战量子纠错(Quantum Error Correction, QEC)是量子计算实现实用化的关键技术屏障。与传统经典计算不同,量子系统面临着更为复杂的噪声环境:退相干、门操作误差、测量错误等量子特异性噪声会迅速破坏脆…...

Midjourney玩具相机风格从翻车到封神:1个--v 6.1专属参数组合+2个隐藏式胶片颗粒注入指令+1套曝光补偿校准表
更多请点击: https://intelliparadigm.com 第一章:Midjourney玩具相机风格的视觉本质与审美悖论 失真即真实:玩具相机的光学哲学 玩具相机(Toy Camera)风格在 Midjourney 中并非简单模拟 Lomography 或 Holga 的物理…...